 |
Vorlesung "Unix"von Prof. Jürgen Plate |
|
Vorlesung "Unix"von Prof. Jürgen Plate |
Unix is user friendly, it just happens to be very particular about who it makes friends with.
Linux ist im Prinzip nichts anderes als eine neue Unix-Variante. Zu den Besonderheiten von Linux zählen die freie Verfügbarkeit des gesamten Quelltexts und die große Hardware-Unterstützung. Genau genommen bezeichnet der Begriff Linux nur den Kernel: Der Kernel ist der innerste Teil (Kern) eines Betriebssystems mit ganz elementaren Funktionen wie Speicherverwaltung, Prozessverwaltung und Steuerung der Hardware.
Als Linux-Distribution wird die Einheit bezeichnet, die aus dem eigentlichen Betriebssystem (Kernel) und seinen Zusatzprogrammen besteht. Eine Distribution ermöglicht eine rasche und bequeme Installation von Linux. Distributionen werden zumeist in Form von CD-ROMs oder DVDs verkauft. Viele Distributionen sind darüber hinaus auch zum Download im Internet verfügbar. Wegen der riesigen Datenmengen (oft mehrere GByte) ist das Kopieren einer Distribution via Internet bzw. eine direkte Installation über das Netz aber nur bei einer ausgezeichneten Internet-Anbindung möglich. Manche behandeln die Distributionen sogar so, als seien sie eigene Betriebssysteme. Die Frage, welche Distribution die beste sei, welche wem zu empfehlen sei etc., artet leicht zu einem Glaubenskrieg aus. Wer sich einmal für eine Distribution entschieden und sich an deren Eigenheiten gewöhnt hat, steigt nicht so schnell auf eine andere Distribution um. Ein Wechsel der Distribution ist nur durch eine Neuinstallation möglich, bereitet also einige Mühe. Um Linux herum existieren auch etliche Behauptungen und Vorurteile:
Linux ist schneller/langsamer als Windows: Diese Aussage ist so weder in der einen noch in der anderen Form richtig. Tatsächlich gibt es einzelne Programme, die unter Linux oder unter Windows schneller laufen. Daraus lassen sich aber keine allgemein gültigen Schlussfolgerungen ziehen. Das Ergebnis hängt unter anderem davon ab, für welches Betriebssystem das Programm optimiert wurde, welche Linux- und Windows-Versionen miteinander verglichen werden, welche Hardware für den Vergleich verwendet wurde etc.
Linux benötigt weniger Ressourcen als Windows: Grundsätzlich stimmt es, dass Sie Linux auf einem 486-er PC mit einigen MByte RAM betreiben können. In dieser Konfiguration läuft Linux zwar nur im Textmodus, bietet ansonsten aber sicher viel mehr Funktionen als eine alte Windows-Version, die auf einem derartigen Rechner ebenfalls noch läuft. Wenn Sie dagegen eine aktuelle Linux-Distribution von Red Hat oder Suse mit einer aktuellen Windows-Version vergleichen, sind die Unterschiede weniger deutlich. Für ein komfortables Arbeiten in einer grafischen Benutzeroberfläche (KDE oder Gnome) stellt Linux ähnliche Hardware-Ansprüche wie Windows.
Linux ist sicherer als Windows: Leider kranken alle zurzeit populären Betriebssysteme an Sicherheitsproblemen. Linux schneidet in den meisten Vergleichen relativ gut ab, dennoch finden sich immer wieder neue Sicherheitslücken. Wie sicher Linux ist, hängt aber auch von seiner Verwendung ab:
Die Sicherheit von Linux-Systemen hängt schließlich sehr stark von Ihrem eigenen Wissen ab. Wenn Sie als Linux-Einsteiger rasch einen Internet-Server konfigurieren und ins Netz stellen, ist nicht zu erwarten, dass dieser Server bereits optimal abgesichert ist. Es mangelt aber nicht an Literatur zu diesem Thema!
Linux ist stabiler als Windows: Mittlerweile hat Microsoft mit Windows 7 durchaus respektable und stabile Windows-Versionen zustande gebracht. Der Linux-Kernel an sich ist außerordentlich stabil. Wenn Sie mit Linux aber das Gesamtsystem der mitgelieferten Software meinen (also eine ganze Distribution), dann sieht es mit der Stabilität gleich erheblich schlechter aus. Insbesondere relativ neue Programme stürzen immer wieder ab. Server-Programme laufen dagegen meist vollkommen fehlerfrei. Je stärker Sie sich anwendungsorientierten Programmen zuwenden und Linux als Desktop-System einsetzen, desto eher werden Sie die negativen Seiten kennen lernen.
Linux ist billiger als Windows: Diese Aussage ist leicht zu untermauern - Linux ist schließlich kostenlos erhältlich. Bei Microsoft hat man mit dieser Argumentation natürlich keine Freude - dort weist man darauf hin, dass auch Schulungskosten etc. berücksichtigt werden müssen. (In solchen Rechenbeispielen wird Windows-Wissen meist als gottgegeben vorausgesetzt, Linux-Kenntnisse natürlich nicht.) Außerdem ist nicht jede Linux-Distribution tatsächlich kostenlos.
Linux ist kompliziert zu installieren: Wenn man einen PC kauft, ist Windows meist schon vorinstalliert. Insofern stellt es natürlich einen Mehraufwand dar, Linux zusätzlich zu installieren. Wie Sie im nächsten Kapitel feststellen werden, ist eine Linux-Installation aber mittlerweile kinderleicht - und sicher nicht schwieriger als eine Windows-Installation. Problematisch ist lediglich die Unterstützung neuer Hardware, die unter Windows besser ist: Jeder Hersteller von Computer-Komponenten stellt selbstverständlich einen Windows-Treiber zur Verfügung. Vergleichbare Treiber für Linux müssen dagegen oft von der Open-Source-Gemeinschaft programmiert werden. Das dauert natürlich eine gewisse Zeit.
Linux ist kompliziert zu bedienen: Dieses Vorurteil ist alt, aber nicht mehr bzw. nur noch in einem sehr geringen Maß zutreffend. Linux ist einfach anders zu bedienen als Windows, so wie auch Apples Mac OS anders zu bedienen ist. Wirklich schwieriger ist die Handhabung von Linux zumeist nicht, lediglich die Umgewöhnung von Windows kann manchmal mühsam sein.
Als Ken Thompson 1969 bei Bell Laboratories, die Entwicklung eines neuen Betriebssystems begann, waren die meisten der vorhandenen Systeme ausgesprochene Batch-Systeme. Der Programmierer gab seine Lochkarten oder Lochstreifen beim Operator ab, diese wurden in den Rechner eingelesen und ein Rechenauftrag nach dem anderen abgearbeitet. Der Programmierer konnte dann nach einiger Zeit seine Ergebnisse abholen.
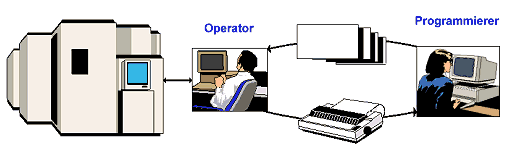
Ziel von Ken Thompsons Entwicklung war es deshalb, ein System zu schaffen, auf welchem mehrere Programmierer im Team und im Dialog mit dem Rechner arbeiten, Programme entwickeln, korrigieren und dokumentieren konnten, ohne von einem Großrechner mit allen seinen Restriktionen abhängig zu sein. Dabei standen Funktionalität, strukturelle Einfachheit und Transparenz sowie leichte Bedienbarkeit im Vordergrund der Entwicklung. Dieses erste System mit dem Namen Unix lief auf einer DEC PDP-7. Unix ist vom Betriebssystem "Multics" inspiriert, so auch der Name. Brian Kernighan schlug vor, das neue Betriebssystem "Unics" zu nennen. Irgendwer hat es dann mit "X" am Schluss buchstabiert und dabei blieb es dann.
Schon bald findet sich eine kommerzielle Anwendung: Die Patentabteilung der Bell Labs sucht ein System zum Erstellen, Bearbeiten und Formatieren von Patentformularen. Mit dem auf die PDP-11 portierten und erweiterten Text-Prozessor "roff" (heute noch als "nroff" für die Formatierung der Manual-Pages zuständig) nimmt Unics Mitte 1971 seinen ersten kommerziellen Dienst auf. Währenddessen arbeiten die Entwickler an Erweiterungen und neuen Programmen auf derselben Maschine. Am 3. November 1971 ist schließlich das "Unix Time-Sharing System", First Edition fertig.
Die erste Version von Unix war in der Assemblersprache der PDP-7 geschrieben. Von Anfang an wollte Thompson das System in einer hardwareunabhängige Hochsprache programmieren. Zuerst entwickelt er eine einfache Sprache auf Basis von BCPL (Basic Combined Programming Language), die er schlicht "B" nennt. B ist als Interpreter-Sprache für ein Betriebssystem aber nicht schnell genug. Dennis Ritchie erweitert die Syntax um strukturierte Typen und schreibt 1971 den fehlenden Compiler. Brian Kernighan, späterer Koautor von AWK (Aho, Weinberger, Kernighan) steuert die Dokumentation zur neuen Sprache bei, die "C" genannt wird.
Unix wurde 1972 in C umgeschrieben und auf die PDP-11 übertragen. Von nun an erfolgte die Weiterentwicklung des Systemkerns sowie der meisten Dienstprogramme in dieser Sprache. Die Kompaktheit und strukturelle Einfachheit des Systems ermunterte viele Benutzer zur eigenen Aktivität und Weiterentwicklung des Systems, so daß Unix recht schnell einen relativ hohen Reifegrad erreichte. Dies ist deshalb bemerkenswert, da kein Entwicklungsauftrag hinter diesem Prozess stand und die starke Verbreitung von Unix nicht auf den Vertrieb oder die Werbung eines Herstellers, sondern primär auf das Benutzerinteresse zurückzuführen ist. Eine ähnliche Entwicklung zeigt sich seit einigen Jahren bei den freien Unix-Varianten.
Mitte 1973 erscheint Unix V4, fast vollständig in C geschrieben. Damit ist das System auch sehr portabel. Wo immer ein C-Compiler existiert, kann Unix implementiert werden. Schon 1973 erhält die UCB (University of California, Berkeley) eine Kopie von Unix V4 und beginnt umgehend mit Erweiterungen - die Wurzel des heute noch aktiven BSD-Unix.
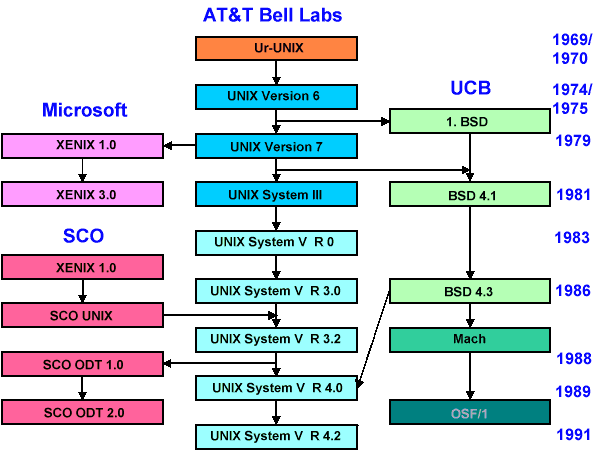
Da das 1956 erlassene Consent Decree AT&T kommerzielle Aktivitäten außerhalb des Telefonmarktes verbietet, gibt die Firma Unix-Quellen und -Binaries zum geringen Preis an Universitäten ab. 1977 veröffentlicht der Student Bill Joy die Berkeley-Erweiterungen als Berkeley Software Distribution (BSD), 1978 folgt 2BSD und der legendäre Editor "vi". 3BSD und 4BSD werden zur Grundlage für die Entwicklung von TCP/IP - und damit des Internets. Die für Universitäten erschwinglichen PDP-Nachfolgerechner VAX und das darauf portierte 4.xBSD steigern die Verbreitung. Im Lauf der Zeit sind zwei Entwicklungszweige entstanden, da Unix sowohl bei Bell Labs (AT&T) als auch an der Universität von Berkley weiterentwickelt wurde: "BSD" und "System V". Kommerzielle Unix-Versionen von Sun (SunOS/Solaris), DEC (Ultrix) und andere folgen.
Als 1979 nach der Freigabe von Unix V7 das Consent Decree fällt, will AT&T Unix kommerziell nutzen. Als eine der ersten Firmen lizenziert Microsoft 1979 den Code von Unix V7. Seine Portierungen auf Intels 8086 erscheinen 1980 unter dem Namen "Xenix OS". Obwohl Microsoft bereits 1987 Xenix an SCO verkauft, die es weiterführt, hat dieses kurze Intermezzo Folgen: Die Unix-Erfahrungen bilden schon den Hintergrund des DOS-2.0-Dateisystems und die Grundlage für Windows NT. Auch die TCP/IP-Implementierung erinnert stark an BSD-Unix.
AT&T entwickelt Unix weiter, es folgen die Systeme III, IV und V. Ihnen entstammen viele Derivate diverser Hersteller. Auch entwickelt AT&T die freien UNIXe V8, V9 und V10 weiter, doch ohne sich um die Verbreitung zu bemühen. Die Nachfolge tritt 1987 Plan 9 an. Daneben wurden zahlreiche weitere Unix-Derivate entwickelt, z. B. die frei erhältlichen Systeme Net-BSD; Free-BSD, Minix und "Linux".
Die allerersten Teile des Linux-Kernels wurden von Linus Torvalds (Helsinki) entwickelt, der den Programmcode im September 1991 über das Internet freigab. In kürzester Zeit fanden sich weltweit Programmierer, die an der Idee Interesse hatten und Erweiterungen dazu programmierten: ein verbessertes System zur Dateiverwaltung, Treiber für diverse Hardware-Komponenten, Zusatzprogramme wie den DOS-Emulator etc. All diese Einzelkomponenten wurden ebenfalls kostenlos zur Verfügung gestellt. Das Gesamtsystem wuchs mit einer atemberaubenden Geschwindigkeit. Die Entstehung dieses neuen Betriebssystems wäre ohne die weltweite Kommunikation der Programmierer via Internet unmöglich gewesen.
Ein wesentlicher Faktor dafür, dass Linux frei von den Rechten der großen Software-Firmen ist und dennoch derart schnell entwickelt werden konnte, war die zu diesem Zeitpunkt schon frei verfügbare Software. Linux ist nicht aus dem Nichts aufgetaucht, wie das manchmal fälschlich dargestellt wird, sondern baut auf einer breiten Basis freier Software auf. Für die ersten Schritte war das freie (aber im Funktionsumfang sehr eingeschränkte) Minix eine praktische Grundlage. So verwendeten die ersten Linux-Versionen noch das Dateisystem von Minix.
In ihrer Bedeutung wohl noch wichtiger für Unix und Linux waren und sind die zahlreichen GNU-Programme (GNU is Not Unix). GNU-Programme wurden auf vielen Unix-Systemen als Ersatz für diverse (teuere) Originalkomponenten verwendet - etwa der GNU-C-Compiler, der Texteditor Emacs und viele andere GNU-Utilities. Sobald der Kernel von Linux dann so weit entwickelt worden war, dass der GNU-C-Compiler darauf zum Laufen gebracht werden konnte, stand praktisch mit einem Schlag die gesamte Palette der GNU-Tools zur Verfügung. So wurde aus einem Kernel plötzlich ein recht vollständiges System, das dann für eine noch größere Entwicklergemeinde zu einer attraktiven Umgebung wurde.
GNU-Programme sind ebenso wie Linux (unter gewissen Einschränkungen) frei kopierbar - und zwar nicht nur als Binärprogramme, sondern mit sämtlichen Codequellen. Das ermöglicht es allen GNU-Anwendern, die Programme bei Problemen oder Fehlern selbst zu erweitern oder zu korrigieren. Aus diesen änderungen resultieren immer bessere und ausgereiftere Versionen der diversen GNU-Programme. Nicht zuletzt aufgrund der freien Verfügbarkeit des Programmcodes stellt der GNU-C-Compiler den Standard in der Unix-Welt dar: Der Compiler ist praktisch auf jedem Unix-System verfügbar - und nicht nur dort.
Erst die Kombination aus dem Linux-Kernel, den zahlreichen GNU-Komponenten, der Netzwerk-Software des BSD-Unix, dem ebenfalls frei verfügbaren X Window System des MIT (Massachusetts Institute of Technology) und dessen Portierung XFree86 für PCs mit Intel-Prozessoren sowie aus zahlreichen weiteren Programmen macht eine Linux-Distribution zu einem kompletten Unix-System.
Das Ziel der Entwickler von GNU und Linux war es also, ein System zu schaffen, dessen Quellen frei verfügbar sind und es auch bleiben. Um einen Missbrauch auszuschließen, ist Software, die im Sinne von GNU entwickelt wurde und wird, durch die GNU General Public License (kurz GPL) geschützt. Hinter der GPL steht die Free Software Foundation (FSF). Diese Organisation wurde von Richard Stallmann (der unter anderem auch Autor des Editors Emacs ist) gegründet, um qualitativ hochwertige Software frei verfügbar zu machen.
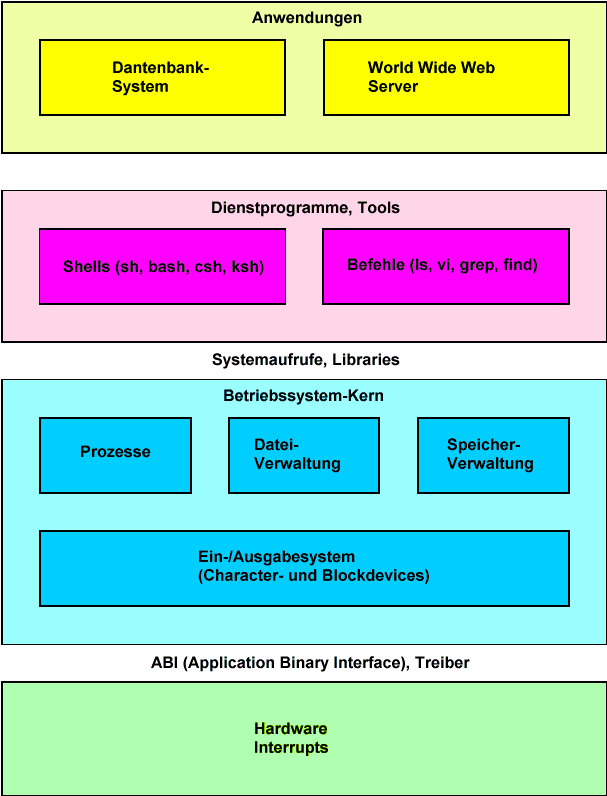
Die Dialogschnittstelle zur Kommunikation mit dem Benutzer (zeichenorientiert) wird dabei als Shell bezeichnen. Diese Shells unter Unix haben dabei zwei Funktionen, sie werden
Kommandointerpreter = Shell:
Damit jeder dieser Benutzer seine Daten vor dem Zugriff der anderen Benutzer schützen kann, muß man sich, bevor man mit einem Unix-System arbeiten kann, erst einmal anmelden, das heißt, einen speziellen Benutzernamen und ein Passwort eingeben. Dadurch erfährt das System, welcher Benutzer da gerade die Arbeit aufnehmen möchte, und kann diesem Benutzer seine persönliche Arbeitsumgebung (inclusive aller privater Daten) zur Verfügung stellen.
Nach dem Einschalten des Terminals bzw. nach Aufnahme der Verbindung mit dem Unix-Rechner meldet sich das BS mit der Aufforderung, sich zu identifizieren:
login:
Der Benutzer gibt darauf den ihm zugewiesenen Login-Namen ein. Dann erscheint die Abfrage des Paßwortes:
password:
Nun muß der Benutzer sein Passwort eingeben. Das Passwort wird im Gegensatz zu den üblichen Eingaben nicht auf dem Bildschirm ausgegeben. Wenn alles gutgeht, sind Sie jetzt beim System angemeldet (man sagt auch: eingeloggt). Sie erkennen die erfolgreiche Anmeldung daran, daß die Eingabeaufforderung des Systems, der sog. Prompt erscheint. Der Prompt sieht etwa so aus:
benutzername@sun1-lbs$
und dahinter ist ein Cursor sichtbar (die Texteinfügemarkierung) und das System erwartet nun die Eingabe eines Kommandos.
Hat sich der Benutzer vertippt, erscheint die Meldung:
login incorrect
und die o. g. Prozedur muß wiederholt werden. Neue Benutzer haben noch kein Passwort, sie drücken nur die RETURN-Taste bei der Frage nach dem Passwort. Bei vielen Systemen wird der Benutzer beim ersten Login zur Eingabe des Passwortes aufgefordert. Zum Ändern und Eingeben des Passworts gibt es ein eigenes Kommando:
passwd
Das Passwort muß einigen Bedingungen genügen:
Beim Einschalten des Rechners werden zunächst Systeminitialisierungsroutinen durchlaufen und die einzelnen Platten des Systems in das Dateisystem eingebunden ("mount"). Je nach BS-Version gelangt das BS dann gleich in den Mehrbenutzerbetrieb oder in den Einzelbenutzerbetrieb (single user mode). Dieser Modus ist speziell für die Systemwartung notwendig, wenn kein anderer Benutzer den Rechner verwenden darf (z. B. Generieren einern neuen Systemversion, Benutzerverwaltung, Datensicherung, etc.). Vom Einzelbenutzerbetrieb wird dann der normale Mehrbenutzerbetrieb gestartet. Beim Abschalten des Systems wird umgekehrt verfahren. Alle noch laufenden Prozesse werden gestoppt (normalerweise mit vorheriger Warnung der noch aktiven Benutzer, damit diese ihre Arbeit in Ruhe beenden können), das Dateisystem aktualisiert (Schließen offener Dateien, Wegschreiben von Pufferbereichen) und in den Einzelbenutzerbetrieb übergegangen. Danach kann abgeschaltet werden.
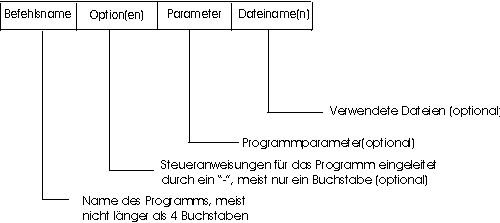
Fast jedem Kommando kann eine Liste von Dateien mitgegeben werden, auf die das Kommando dann angewendet wird. Fehlt die Dateiliste, wird in der Regel die Standardeingabe - normalerweise die Tastatur - als Eingabedatei verwendet. Wie spater noch genauer gezeigt wird, verwendet Unix die Jokerzeichen (Wildcards) Stern (*) und Fragezeichen (?), um beliebige Zeichen innerhalb eines Dateinamens zu kennzeichnen. DOS und Windows haben diese Methode übernommen. Im Gegensatz zu DOS und Windows werden diese Wildcards jedoch nicht vom Programm, sondern von der Shell zu Dateinamen expandiert. Deshalb "sieht" jedes Unix-Programm nur eine mehr oder weniger lange Dateiliste.
Nahezu jedes Fenster hat unter X einen Rahmen. Mit Hilfe dieses Rahmens kann man die Dimensionen und die Position des Fensters verändern. Zunächst kann man durch "Klicken und Ziehen" auf die Titelleiste des Fensters das Fenster als Ganzes bewegen und an einer anderen Stelle des Bildschirms "loslassen". "Klicken und Ziehen" bedeutet, daß man mit dem Mauspfeil auf die Titelleiste zeigt, dann die linke Maustaste drückt, festhält, und bei gedrückter Taste die Maus bewegt. Wenn das Fenster die erwünschte Position erreicht hat, läßt man die linke Maustaste wieder los.
Wenn man jetzt mit der Maus die untere rechte Ecke des Fensters ansteuert, verwandelt sich der Mauspfeil selber in eine "Ecke" (ausprobieren!). Wenn der Mauspfeil so aussieht, dann kann man durch klicken+ziehen (s.o.) die Fenstergröße verändern. Es ist nicht ratsam, die Größe der zwei Textfenster zu ändern, die gleich am Anfang erscheinen, weil viele Programme davon ausgehen, daß diese Fenster eine feste Größe haben (nämlich 80 Zeichen Breite und 25 Zeilen Höhe).
Weiterhin sind am oberen Rand des Fensters, direkt rechts neben der Titelleiste, zwei Knöpfe zu sehen: einer enthält ein großes und einer ein kleines Quadrat. Durch einmaliges, kurzes Klicken auf den Knopf mit dem großen Quadrat bewirkt man, daß das Fenster seine volle Größe annimmt, d.h. es wird in der Regel über den ganzen Bildschirm vergrößert. Ein weiteres Klicken auf diesen Knopf setzt die Fenstergröße wieder auf die Normalgröße zurück.
Der zweite Knopf, der mit dem kleinen Quadrat, bewirkt, daß das Fenster zum Symbol verkleinert wird. Das Symbol landet dann in der "Icon-Box", die in der Abbildung des gesamten X-Window-Bildschirms (oben) in der linken unteren Ecke zu sehen ist. Ein Doppelklick auf ein Icon führt dazu, daß das entsprechende Fenster wieder geöffnet und im Vordergrund angezeigt wird (d.h. ohne daß es durch andere Fenster überdeckt wird). Man kann also diese Icons auch dazu benutzen, unsichtbare (weil verdeckte) Fenster wieder in den Vordergrund zu holen.
Den Inhalt einiger Fenster (xterm) kann man mit Hilfe der Rollbalken auf der rechten Seite bewegen, und so auch bereits nach oben weggerollte Zeilen wieder sichtbar machen. Dazu plaziert man den Mauszeiger auf den schwarzen Bereich des Rollbalkens und hält die mittlere Maustaste gedrückt, während man die Maus nach oben oder unten bewegt.
Das X-Window-System wird verlassen, indem man mit der Maus auf den Hintergrund des Bildschirms klickt, dabei die linke Maustaste aber nicht losläßt, sondern bei gedrückter Taste die Maus nach unten zieht. Es erscheint ein Menü und man kann den Punkt "Exit" oder "Quit" ansteuern und dann die Maustaste loslassen. Nach einer weiteren Abfrage ("OK") ist man dann wieder auf der grünen Kommandozeile und kann mit dem Kommando "exit" die Sitzung beenden. Bei Linux geht das auch durch Drücken von Ctrl-Alt-Backspace.
Da Unix ein Multiuser-System ist, muß der Zugriff auf einzelne Dateien und Verzeichnisse vom System schon so geregelt werden, daß kein Benutzer die Daten der anderen Benutzer manipulieren oder vertrauliche Daten unbefugterweise einsehen kann. Das wird dadurch gewährleistet, daß jede Datei und jedes Verzeichnis einen Besitzer (Owner) hat, und dieser Besitzer kann mit Hilfe bestimmter Befehle festlegen, welcher der anderen Benutzer auf welche Weise auf seine Dateien zugreifen darf. Die meisten Dateien und Verzeichnisse in einem Unix-System gehören natuergemäß dem Systemverwalter (der den Usernamen "root" trägt) und jeder Benutzer kann auf diese Dateien lesend zugreifen, sie aber nicht verändern (zu dieser Art von Dateien gehören zum Beispiel alle Anwendungsprogramme, die das System zur Verfügung stellt).
Man unterscheidet grob drei Dateitypen (weitere Typen weiter unten):
Unix arbeitet mit einem Filesystem, das auf den ersten Blick dem von DOS sehr ähnlich ist (nur auf den ersten). Also gibt es eine Baumstruktur von verschiedenen Verzeichnissen (Directories), in der sich jede Datei irgendwo befindet. Beachten Sie aber, daß ein Directory beim Anzeigen zunächst genauso aussieht, wie eine Datei!. Die einzelnen Verzeichnisnamen werden durch normale Schrägstriche ('/') getrennt, NICHT durch Backslashes ('\') wie bei DOS/Windows!
Nach dem Einloggen landen Sie in Ihrem sogenannten Homedirectory (Meist '/home/username'). Es gehört Ihnen ganz alleine, damit können Sie machen, was Sie wollen. Zum Beispiel können Sie dort Dateien oder weitere Verzeichnisse anlegen. An dieser Stelle gleich einige wichtige Punkte:
/usr/projekt1/meier/test/steuerung
| steuerung | (akt. Verz.: /usr/projekt1/meier/test) |
| test/steuerung | (akt. Verz.: /usr/projekt1/meier) |
Das aktuelle Verzeichnis ist immer jenes, dessen Inhalt wir gerade bearbeiten. Das aktuelle Verzeichnis läßt sich jederzeit wechseln, aber ein Verzeichnis ist zu einem bestimmten Zeitpunkt immer das aktuelle und alle unsere Kommandos beziehen sich dann auf dieses eine, aktuelle, Verzeichnis.
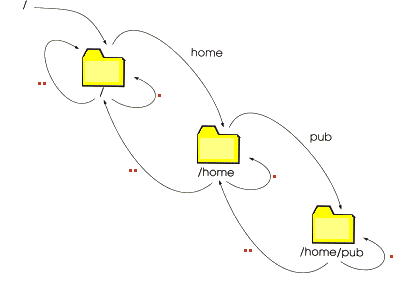
Eine besondere Erwähnung verdienen die beiden Verzeichnis-Einträge "." und "..". Das sind Stellvertreter für Verzeichnisnamen, die man statt der realen Namen (abkürzend) benutzen kann. Und zwar bezeichnet "." das jeweils aktuelle Verzeichnis, und ".." das dem aktuellen Verzeichnis übergeordnete Verzeichnis.

Alle Benutzer sind in einer speziellen Datei gespeichert,
die nur der Superuser ändern darf - sonst könnte ja jeder einen neuen
Benutzer eintragen.
Jeder Benutzer kann aber sein Passwort ändern, das auch in dieser
Datei steht. Dazu muß er schreibend auf die Datei zugreifen - obwohl
er dazu keine Berechtigung besitzt. Das Programm "passwd" gehört dem
Superuser, hat das SUID-Bit gesetzt und kann so auf die User-Datei schreibend
zugreifen.
Wenn das SGID-Bit (Set Group ID) gesetzt ist, hat das Programm die Rechte
der Gruppe, zu der es gehört. Dieses Feature wird z. B. beim Drucker-Spooling
verwendet. Bei Dateien ohne Ausführungsrecht sorgt dieses Bit
dafür, daß die Datei nur von einem Prozess geöffnet werden
kann (Vermeiden von Verklemmungen).
Bei Verzeichnissen hat das SGID-Bit eine andere Aufgabe. Dateien, die in ein
SGID-Verzeichnis kopiert werden, erhalten automatisch die Gruppe des Verzeichnisses
(man muß also nicht mehr explizit die Gruppe setzen, um den Mitgliedern einer
Gruppe Zugriff zu ermöglichen). Setzen durch das Kommando: "chmod g+s datei".
Anzeige: "s" statt "x" bei den Gruppen-Rechten ("l" bei Daten-Dateien).
Das STICKY-Bit sollte früher den Systemdurchsatz verbessern. Programme, bei denen
dieses Bit gesetzt ist, verbleiben nach dem ersten Aufruf im Speicher und
starten bei den folgenden Aufrufen schneller. Heute ist das nicht mehr nötig.
Bei Verzeichnissen dient dieses Bit der Systemsicherheit.
Auch wenn im Verzeichnis für alle User Schreibrecht existiert (= Löschen
und Anlegen von Dateien), können bei gesetztem Sticky-Bit nur Dateien
gelöscht werden, die einer folgenden Bedingungen genügen:
Historisches: Das System der Zugriffsrechte, insbesondere SUID, SGID und STICKY, wurden von den Entwicklern patentiert. Interessant an der Patentschrift (Bild der ersten Seite) war, das alles als Digitalschaltung dargestellt wurde, denn Software war damals noch nicht patentierbar. Das Patent wurde ein Jahr nach Erteilung von den Entwicklern freigegeben.
Schaut man sich ein physisches Dateisystem genauer an, so erkennt man den Betriebssytemblock als kleinste Einheit (im Bereich von 512 Byte bis 16 kByte). Das physische Dateisystem wird in in vier Bereiche aufgespalten:
Die Größe der einzelnen Bereiche wird bei der Initialisierung eines physischen Dateisystems festgelegt und kann im nachhinein nicht mehr dynamisch verändert werden (außer im Unix-System AIX von IBM). Das dazu notwendige Kommando ist 'mkfs' (make file system). Die Bereiche eines physischen Dateisystems sind auf die Kapazität eines logisch Datenträgers und damit maximal auf die Gesamtkapazität eines Festplattenlaufwerks beschränkt, d. h. festplattenübergreifende physische Dateisysteme sind nicht möglich.
Die Verwaltungsinformation über Dateien steht also nicht wie bei DOS oder Windows in den Dateien selbst, sondern in den Inodes. Jede Datei besitzt einen eigenen Inode (eine eigene Datei-Nummer). Der Zugriff erfolgt entweder sequentiell (Datei ist ein Strom von Bytes ohne weitere Strukturierung) oder wahlfrei (random access) durch Positionierung auf ein bestimmtes Byte in der Datei. Das BS hat einen Cache-Mechanismus implementiert, der einen Teil der Datei im Speicher hält. Ziel: Reduzierung der Plattenzugriffe.
Problem: Dateien müssen regelmäßig aktualisiert werden (Cache-Inhalt auf die Platte schreiben), Gefahr der Inkonsistenz von Daten bei Prozess-Abbruch oder Stromausfall.
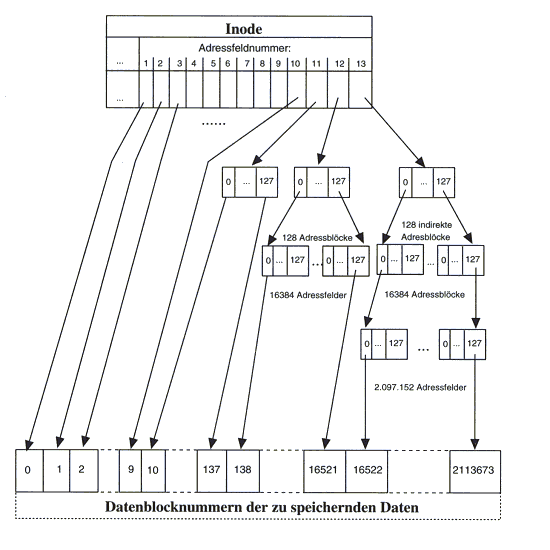
Zu beachten ist, daß der Name der Datei nicht aufgeführt wird. Diese Systemarchitektur ermöglicht es, unter mehreren (verschiedenen) Namen als Einträge von Verzeichnissen die gleiche Datei (genauer gesagt Inode und Dateiinhalt) anzusprechen. Der Inode fungiert somit als Bindeglied zwischen dem Namen und dem Inhalt einer Datei. Für die Adressierung der Inhalte einer Datei ergibt sich eine bestimmte Verweisstruktur.
Eine Datei mit bis zu 10 Plattenblöcken (Blockgröße 512 oder 1024 Bytes) kann also direkt angesprochen werden. Größere Dateien haben zusätzlich einen Verweis (einfach indirekt) auf einen Datenblock, der seinerseits 128 Verweisfelder enthält. Reicht das noch nicht, wird zweimal (128 Blöcke mit je 128 Verweisen) oder dreimal indiziert (Dateigröße bis 2 GByte bei 512-Byte-Blöcken, bis 16 GByte bei 1KByte-Blöcken).
Das System der Links wird generell verwendet. So gibt es unter Unix keinen Systemaufruf zum Löschen einer Datei, sondern lediglich einen Unlink-Call. Wenn der Link-Zähler einer Datei auf Null gesunken ist (durch entsprechend viele Unlink-Aufrufe), wird deren Inode und der durch die Datei belegte Plattenplatz freigegeben.
Gerätedateien dienen zur Abwicklung des Datenverkehrs zwischen den Programmen und der Peripherie. Da sie, wie die abstrakten Komponenten (normale Dateien, Verzeichnisse, usw.) einheitlich in den Systembaum integriert werden, sind auch für sie die Zugriffsschutzmechanismen und Ein- /Ausgabeumleitung gültig. Die Geräte werden durch logische Namen angesprochen, die die Gerätetreiber der Peripheriegeräte bezeichnen. Intern wird jedes Gerät durch eine Treiber-Nummer (major device number) und eine Geräte-Nummer (minor device number) markiert. Diese Nummern sind im ls -l Eintrag in dem Feld enthalten, das die Dateigröße angibt.
Ein Gerät kann durchaus auch über verschiedene Treiber angesprochen werden. Normalerweise werden die Geräte vom Benutzer nicht direkt, sondern über Dienstprogramme angesprochen. Wenn jemand z. B. den Drucker direkt anspricht, während ein anderer Benutzer über den Spooler ausdruckt, gibt es "Datenmüll" auf dem Papier. Zwei interessante Geräte können jedoch alle Benutzer ansprechen:
Es gibt bei Unix prinzipiell zwei Typen von Treibern:
Um gezielt steuern zu können, welcher Benutzer auf welche Devices zugreifen darf, sind den Devices unterschiedliche Benutzergruppen zugeordnet. Beispielsweise sind die Devices /dev/ttyS* für die seriellen Schnittstellen üblicherweise der Gruppe uucp zugeordnet. Wenn der Systemadministrator möchte, dass die Userin gundel über die serielle Schnittstelle direkt auf ein Modem zugreifen darf, fügt er gundel zur Gruppe uucp hinzu (mit dem Kommando usermod -G oder durch Bearbeiten der Datei /etc/group).
Eine vollständige Beschreibung aller unter Linux zurzeit definierten Devices samt der dazugehörigen Device-Nummern finden Sie in der Datei /usr/src/linux/Documentation/devices.txt (nur, wenn der Kernel-Quellcode installiert ist).
Die größte Neuerung in Kernel 2.6 ist die Vergrößerung der Device-Nummern auf 64 Bits. Bereits vorhandene Device-Nummern sollten sich dadurch nicht ändern; ganz sind Kompatibilitätsprobleme aber nicht auszuschließen. Offen ist noch, ob sich am prinzipiellen Umgang mit Device-Dateien in Zukunft etwas ändern wird.
Im Verzeichnis /dev befinden sich normalerweise Gerätedateien (Device Nodes), die, wie oben beschrieben, den Zugriff auf Geräte (z. B. Festplatten, Maus, Soundkarte) erlauben. Diese Gerätedateien werden normalerweise mit MAKEDEV angelegt, denn ohne Gerätedatei ist kein Zugriff auf ein Gerät möglich. Aus diesem Grunde existieren normalerweise Unmengen von Gerätedateien für größtenteils nicht vorhandene Geräte. Das udev-Dateisystem legt diese Gerätedateien dynamisch an, der Einsatz von MAKEDEV ist nicht mehr nötig und es existieren nur noch Gerätedateien für existierende Geräte mit Treiber. Mit andren Worten: nie wieder nach nicht existierenden Geräten suchen oder Device Nodes anlegen müssen. Salopp gesagt erstellt und entfernt es Einträge in /dev, basierend auf der aktuellen Systemkonfiguration. Prinzipiell ist udev ein modulares System zur automatischen Erstellung von Gerätedateien in /dev.
Dies wurde erreicht durch überwachen der vom Programm hotplug generierten Ereignisse im System und Auslesen von Informationen zu diesen Ereignissen aus dem Dateisystem sysfs. udev arbeitet unter Benutzung von hotplug-Aufrufen des Kernels, wann immer ein Gerät zum Kernel hinzugefügt oder daraus entfernt wird. Die Namensgebung und Zugangsberechtigungen werden im User-Space ausgeführt. Die Ziele des udev Projekts sind:
Um diese Funktionen zu liefern, wird udev in drei unterschiedlichen Projekten entwickelt: namedev, libsysfs und natürlich udev.
Der erste Schritt überprüft, ob das Gerät ein einzigartiges Identifikationsmerkmal hat. Zum Beispiel haben USB-Geräte eine einzigartige USB-Seriennummer und SCSI-Geräte eine einzigartige UUID. Wenn namedev eine übereinstimmung zwischen dieser einzigartigen Nummer und einer gegebenen Konfigurationsdatei findet, dann wird der von der Konfigurationsdatei gelieferte Name verwendet.
Der zweite Schritt überprüft die Bus-Gerätenummer. Für nicht-hot-swappable Umgebungen ist diese Prozedur ausreichend, um ein Hardware-Gerät zu identifizieren. Zum Beispiel verändern sich PCI-Busnummern selten in der Lebenszeit eines Systems. Findet namedev eine übereinstimmung mit dieser Position und einer gegebenen Konfigurationsdatei, wird der von der Konfigurationsdatei gelieferte Name verwendet.
Auch die Bus-Topologie ist ein eher statischer Weg zur Definition von Geräten. Wenn die Position des Gerätes zu einer vom Benutzer gelieferten Einstellung passt, wird der beiliegende Name verwendet.
Der vierte Schritt ist eine einfache Stringersetzung. Wenn der Kernel-Name (der Standardname) des Device zu einem gegebenen Ersatzstring passt, wird der Ersatzname stattdessen verwendet.
Der letzte Schritt nimmt den vom Kernel gelieferten Standardnamen. In den meisten Fällen ist dies ausreichend, da es zur augenblicklich üblichen Gerätebenennung passt.
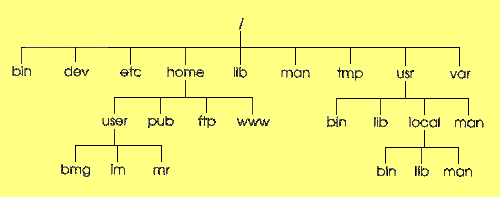
Stimmt, das Bild war weiter oben schon zu sehen. Wenn wir uns ein Verzeichnis mit dem Kommando "ls -l" ansehen, erhalten wir eine solche Liste:
total 1093 -rw-r--r-- 1 root root 116547 May 25 1997 System.map drwxr-xr-x 2 root root 1024 Sep 23 1996 bin/ drwxr-xr-x 2 root root 1024 May 25 1997 boot/ drwxr-xr-x 2 root root 1024 Oct 27 1996 cdrom/ drwxr-xr-x 3 root root 20480 May 4 15:28 dev/ drwxr-xr-x 7 root root 2048 May 4 16:05 etc/ drwxr-xr-x 5 root root 1024 Dec 7 1997 home/ drwxr-xr-x 3 root root 1024 Sep 23 1996 lib/ drwxr-xr-x 5 root root 1024 Sep 23 1996 local/ drwxr-xr-x 2 root root 12288 Sep 23 1996 lost+found/ drwxr-xr-x 2 root root 1024 Sep 23 1996 mnt/ dr-xr-xr-x 5 root root 0 May 4 1999 proc/ drwx------ 5 root root 1024 Sep 21 1997 root/ drwxr-xr-x 4 root root 2048 Sep 23 1996 sbin/ drwxrwxrwx 4 root root 1024 Apr 6 09:18 tmp/ drwxr-xr-x 18 root root 1024 Apr 25 1997 usr/ drwxr-xr-x 14 root root 1024 Apr 25 1997 var/ -rw-r--r-- 1 root root 407793 May 25 1997 vmlinuz
Betrachten wir diese Ausgabe von rechts nach links. Ganz rechts in jeder Zeile steht der Dateiname, jede Zeile ist der Eintrag für eine Datei. Links davon steht in drei Feldern Datum und Uhrzeit der letzten Modifikation der Datei. Im fünften Feld (links vom Monat) steht die Größe der Datei in Bytes (1 Byte entspricht einem Zeichen, also z.B. einem Buchstaben). Die weiteren zwei Felder links von der Dateigröße geben den Besitzer der Datei und dessen Gruppe an. Alle Dateien in diesem Verzeichnis gehören dem Benutzer "root", der Mitglied der Gruppe "root" ist. Schließlich stehen ganz links (in der ersten Spalte) die Zugriffsrechte. Das erste Zeichen dieser ersten Spalte zeigt an, ob es sich beim entsprechenden Eintrag um eine normale Datei ("-"), um ein Verzeichnis ("d"), um ein Character-Device ("c"), um ein Blockdevice ("b") oder um einen Link ("l") handelt.
| Verzeichnis | Beschreibung / Funktion |
| / | Hier sollte mit Ausnahme des Default-Kernels und der zugehörigen System-Map keine Dateien liegen |
| /bin | Systemverwaltungsprogramme, die nicht spezifisch für den Superuser sind (cp, ls oder more) |
| /boot | Lilo-Dateien, die nicht ausführbar und keine Konfigurationsdateien sind; hier liegen auch alternative Kernel |
| /dev | Gerätedateien |
| /etc | Konfigurationsdateien des Basissystems und von Lilo sowie die Benutzerdatenbank |
| /home | Heimatverzeichnisse der Benutzer |
| /lib | Shared Libraries des Basissystems |
| /lost+found | Nimmt Dateien auf, die beim Plattencheck anfallen |
| /mnt | Hier mountet man Laufwerke wie CD-ROM (/mnt/cdrom) und Diskette (/mnt/floppy) |
| /opt | Erweiterungspakete (in Unterverzeichnissen); hier sollte beispielsweise KDE oder Netscape Communicator installiert sein |
| /proc | Dateien des proc-Dateisystems - ein virtuelles Dateisystem, über das Informationen über die Hardware ermittelt werden können |
| /root | Home-Verzeichnis des Superusers (root) |
| /sbin | Die ausführbaren Dateien für Systemadministation und Startskripten |
| /tmp | Temporäre Dateien |
| /usr | Zweites Hauptverzeichnis für Prgramme (Unix System Resources) |
| /usr/X11R6 | X-Window-System |
| /usr/dict | Wörterbücher zu ispell |
| /usr/doc | Doku |
| /usr/include | Header-Dateien für den Präprozessor |
| /usr/local | Lokale Anwendungen + Dateien (analog /usr) |
| /usr/info | Textdateien des Textinfo-Dokumentationssystems |
| /usr/man | Manuals (Online-Hilfe) |
| /usr/share | Architekturunabhängige Daten in verteilten Systemen mit verschiedenen Rechnerarchitekturen (Sparc, RS 6000 ...) |
| /usr/src | Quellcode für die Programme des Standardsystems |
| /usr/src/linux | Kernel-Sourcen; meist handelt es sich hier nur um einen symbolischen Link auf ein aussagekräftigeres Verzeichnis |
| /usr/spool | Wird aus Kompatibilitätsgründen als symbolischer Link auf /var/spool beibehalten |
| /var | Verzeichnis für die variablen Daten, falls /usr über NFS readonly gemountet ist; in /var/log liegen System-Logfiles |
| Funktion | Standard Unix | Berkely Unix |
| Zeilenende | Return-Taste | Return-Taste |
| Lösche Zeichen | # | Backspace |
| Lösche Zeile | @ | Ctrl-U |
| Programm abbrechen | Delete | Ctrl-C |
| Dateiende Eingabeende | Ctrl-D | Ctrl-D |
| Ausgabe anhalten | Ctrl-S | Ctrl-S |
| Ausgabe fortsetzen | Ctrl-Q | Ctrl-Q |
| Bildschirm wiederherstellen | Ctrl-L | Ctrl-L |
Ctrl-S und Ctrl-Q waren früher bei langsamen, seriellen Terminals noch als Reaktionstest brauchbar. Heute sind sie nicht mehr zum Steuern der Ausgabe verwendbar, weil die Bildschirmanzeige zu schnell durchläft. Trotzdem kann Ctrl-S Ärger machen, wenn Sie versehentlich auf die Taste kommen. Dann bleibt die Ausgabe stehen und man hat das Gefühl, der Rechner reagiert nicht mehr. Also erstmal versuchsweise Ctrl-Q drücken.
pwd (Print Working Directory)
Gibt das aktuelle Verzeichnis aus - damit man weiß, wo man überhaupt
rumpfuscht.
cd (Change Directory)
Navigieren im Dateibaum - Wechsel des aktuellen Verzeichnisses. Wechsel
nur in Verzeichnisse mit Execute-Permission möglich. Es gibt zwei
Aufrufformen:
ls (List)
ls [-Parameter] [pfadname]
Auflisten von Dateien und Verzeichnissen mit der zugehörigen Information
(Eselsbrücke: "laß sehen"). Durch Parameter wird die Ausgabe
gesteuert. ls ohne Dateispezifikation listet das aktuellen Verzeichnis,
sonst muß der Pfad angegeben werden. ls / listet z. B. das
Wurzelverzeichnis auf Parameter: ls kennt sehr viele Parameter,
die wichtigsten sind:
ls -al listet z. B. alle wichtige Informationen
ls -CF liefert eine übersichtliche Kurzliste
man (Manual)
Brauchen Sie zu einem Befehl eine Erläuterung, geben Sie
'man Befehl' ein, statt 'Befehl' natürlich den Namen des zu erklärenden
Befehls. Diese Manual-Seiten sind für fast alle Kommandos vorhanden.
Je nach Implementierung ist seitenweises Blättern mit der Leertaste
möglich - oder ein Reaktionstest mit CTRL-S und CTRL-Q. Sehen Sie
sich z. B. einmal die Infos über den Befehl 'ps'
('Prozess Status') an. Der ist auch sehr nützlich. Auch die hier
vorgestellten Befehle können noch viel mehr - alles steht in dem
Manual-Seiten.
Es ist auch unmöglich, in diesem Skript bei jedem Kommando
alle Parameter aufzuzählen. Auch werden sicher nicht alle wichtigen
Kommandos besprochen. Aus diesem Grund ist für den Anfänger wie für den Profi
das man-Kommando wichtig und Voraussetzung für die Arbeit.
passwd (Password)
Interaktives Ändern des Paßworts. Zunächst muß
das bisherige Paßwort eingegeben werden.Bei der Eingabe der Paßwörter
werden diese auf dem Bildschirm nicht angezeigt. Damit Eingabefehler abgefangen
werden können, ist das neue Passwort zweimal einzugeben. Programmamblauf:
$ passwd
old passwd: Josef1
newpasswd: Maria2
retype new passwd: Maria2
who (Who)
Das Kommando gibt aus, wer alles im System aktiv ist. Es werden Login-Name,
Terminal und Datum/Uhrzeit der Anmeldung angezeigt. Zum Beispiel:
$ who hans tty11 Juli 15 09:15 karl tty12 Juli 15 09:55 kathi tty18 Juli 15 10:03
Wer nur wissen will, an welchem Terminal er sitzt, tippt: who am i Das Kommando kennt etliche Parameter, die wichtigsten sind: -p Anzeige der Prozesse, die gerade laufen -T Terminal-Status (mit "write" erreichbar?)
tty (Teletype)
gibt den Namen des aktuellen Terminals (eigentlich jenen des Device-Treibers)
aus. Direkte Ausgabe auf dem Bildschirm können auf dieses Device geleitet
werden. Sie gelangen dann auf jeden Fall aus den Bildschirm, auch wenn
die Eingabe umgeleitet wird (näheres später).
finger Info über User
Informationen über einen User erhält man mit
'finger user' - einfach mal ausprobieren. Unter der Idle-Time versteht man
übrigens die Zeit, seit der der Mensch nichts gemacht hat.
write (Write Message)
Mit diesem Kommando kann man einem anderen Benutzer, der gerade am
Rechner arbeitet, eine Nachricht auf den Bildschirm schicken (Nachrichten
an nicht eingeloggte Benutzer später). Die Nachricht erscheint sofort
auf dem Bildschirm des Partners. Als Parameter wird der Benutzername des
Partners angegeben. Anschließend kann der Text zeilenweise eingegeben
werden. Abgeschlossen wird die Eingaben mit den EOF-Zeichen CTRL-D.
Zum Beispiel:
$ write karl Lieber Karl, dieGeburtstagsfeier für den Boss fängt schon in einer halben Stunde an! Mach Dich rechtzeitig auf die Socken! Gruss, Markus <CTRL-D-Taste>
Bei Karl erscheint dann auf dem Bildschirm:
Message from markus tty16 [Tue Jul 23 14:05:00] Lieber Karl, die Geburtstagsfeier für den Boss fängt schon in einer halben Stunde an! Mach Dich rechtzeitig auf die Socken! Gruss,Markus
mesg (Message) Solche Nachrichten sind zwar recht nützlich, können aber auch stören - wenn man z. B. gerade Texte schreibt. Denn die Nachricht zerstört ja das Bild auf dem Schirm. Mit dem mesg-Kommando kann man das Terminal gegen Nachrichten von außen sperren.mesg n sperrt das Terminal mesg y gibt das Terminal frei.
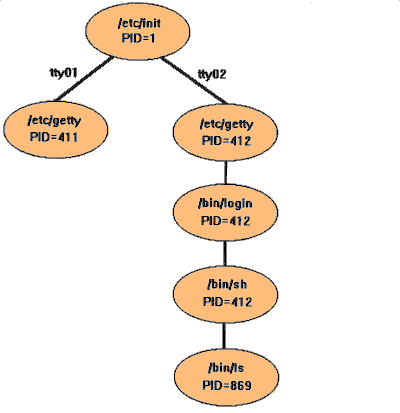
Ein neuer Prozess kann nur von einem bereits laufenden Prozess erzeugt werden. Dadurch werden, ähnlich wie beim Dateibaum, die einzelnen Prozesse im Betriebssystemkern in einer baumartigen, hierarchischen Struktur verwaltet. Jeder Kind-Prozess ist genau einem Eltern-Prozess untergeordnet. Ein Eltern-Prozess kann jedoch beliebig viele Kind-Prozesse besitzen. Die Wurzel der Prozessstruktur wird durch den Systemstart geschaffen und als init-Prozess (PID 1) bezeichnet.
In der Regel wartet der Eltern-Prozess auf die Beendigung seiner Kind-Prozesse. Diese Art der Prozesssynchronisation wird als synchrone Ausführung bezeichnet, der Kind-Prozess wird als Vordergrundprozess ausgeführt. Bezogen auf einen Benutzer ist die Shell (Login-Shell) der Eltern-Prozess. Alle Kommandos, die der Benutzer startet, sind Kind-Prozesse. Während diese abgearbeitet werden ruht der Eltern-Prozess. Als asynchroner Prozess oder Hintergrundprozess werden solche Prozesse bezeichnet, bei denen der Eltern-Prozess nicht auf das Ende seines Kind-Prozesses wartet, sondern parallel (quasiparallel auf einer Ein-Prozessor-Maschine) asynchron weiterläuft. Auf der Shell-Ebene kann jeder Prozess durch Anfügen von '&' (kaufm. UND) in der Kommandozeile als Hintergrundprozess gestartet werden.
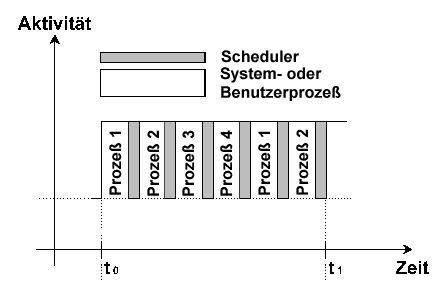
Über einen Scheduling-Algorithmus zur Berechnung der Priorität erhält jeder einzelne Prozess einen bestimmten Teil der Rechenzeit zugewiesen. D.h. der Prozess mit der zur Zeit höchsten Priorität erhalt die CPU, wird nach einen Zeitintervall suspendiert und, falls noch nicht beendet, zu einem späteren Zeitpunkt wieder reaktiviert. Die aktuelle Priorität eines Prozesses setzt sich aus dem Produkt des CPU-Faktors und der Grundpriorität zusammen.
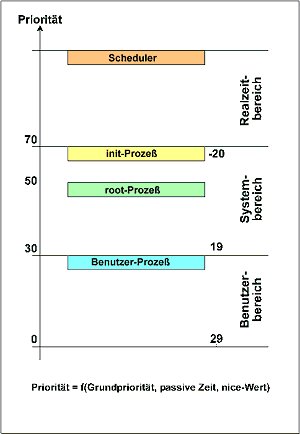
Die Prozessverwaltung und Prioritätssteuerung ist recht komplex. In Stichpunkten:
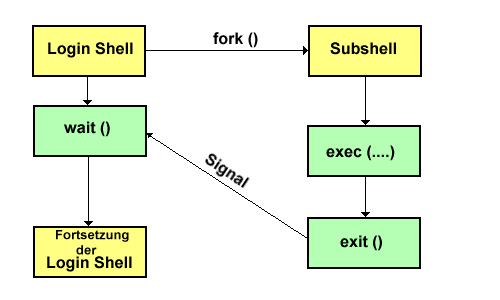
fork() erzeugt einen Kindprozess, der ein vollständiges Abbild des Elternprozesses ist und der beim gleichen Stand des Befehlszählers fortgesetzt wird. Eltern- und Kindprozess wird jedoch die Möglichkeit geboten, festzustellen, ob es sich um Eltern- oder Kindprozess handelt: Der Kindprozess bekommt als Rückgabewert 0, der ElternProzess die PID des Kindprozesses. Durch bedingte Verzweigung nach dem Schema (".. if ElternProzess then ... else ...") können beide Prozesse dann unterschiedlich weiterarbeiten.
wait() ermöglicht dem ElternProzess das Warten auf die Beendigung des/der Kindprozess(e). Der ElternProzess wird verdrängt und erst durch das Ende eines Kindprozesses wieder "aufgeweckt". Zur Unterscheidung mehrerer Kindprozesse liefert die Funktion wait() die PID des "gestorbenen" Kindprozesses zurück.
Gibt es keinen Kindprozess, ist das Ergebnis -1. Beheben des Waisenkind/Zombie-Problems:
Bei exec() wird der ursprüngliche Prozess durch einen neuen Prozess ersetzt (eine Rückkehr zum aufrufenden Prozess ist daher logischerweise nicht möglich). exec() ist der komplizierteste Aufruf, da der komplette Prozessadreßraum ersetzt werden muß. Dieser Aufruf ist auch als Kommando verfügbar (exec [Programmname]). Der Ablauf im Schema:
Schließlich gibt es noch eine Systemfunktion, welche die zeitweise Blockierung eines Prozesses erzwingt: Mit sleep() kann ein Prozess für eine definierte Zeit "eingeschläfert" werden. Nach Ablauf der vorgegebenen Zeit, wird der Prozess wieder auf "bereit" gesetzt und kann weiterlaufen. Auch sleep() ist als Kommando verfügbar (sleep [Zeit in Sekunden]).
Alle Prozesse, die auf dem Rechner laufen sind Kindprozesse von init (wobei "Kind" hier auch für alle weiteren Nachkömmlinge steht). Im Single-User-Modus werden von init nur noch einige Prozesse gestartet, im Multi-User-Modus sind wesentlich mehr Prozesse zu aktivieren (z. B. der Drucker-Spooler, die Abrechnung, etc.). Alle zu startenden Prozesse sind in der Datei /etc/inittab aufgeführt. init holt sich die Informationen über zu startende Prozesse aus der Datei /etc/inittab. Für uns ist eigentlich nur das Programm getty interessant, den dieses Programm sorgt für den Kontakt mit den Terminals. Was geschieht nun weiter?
Die Dateien im /proc-Verzeichnis sind keine echten Dateien und beanspruchen daher auch keinen Platz auf der Festplatte. Das gilt auch für die scheinbar sehr große Datei /proc/kcore, die den Arbeitsspeicher abbildet. Vielmehr handelt es sich bei diesem Verzeichnis um ein virtuelles Dateisystem, das der Linux-Kernel zur Verfügung stellt.
Die meisten der /proc-Dateien liegen im Textformat vor. Um die Dateien zu lesen, müssen Sie unter Umständen cat statt less verwenden. (Manche less-Versionen kommen mit den virtuellen Dateien des /proc-Verzeichnisses nicht zurecht.)
Ein paar interessante /proc-Dateien
/proc/bus/pccard/* ¯
/proc/n/* Informationen zum Prozess mit der PID=n
/proc/bus/usb/* USB-Informationen
/proc/bus/pci/* PCI-Informationen
/proc/cmdline LILO/GRUB-Boot-Parameter
/proc/cpuinfo CPU-Informationen
/proc/devices Nummern von aktiven Devices
/proc/ide/* IDE-Laufwerke und -Controller
/proc/interrupts Nutzung der Interrupts
/proc/iomem Nutzung des IO-Speichers
/proc/ioports Nutzung der IO-Ports
/proc/modules Aktive Module
/proc/mounts Aktive Dateisysteme
/proc/net/* Netzwerkzustand und -nutzung
/proc/partitions Partitionen der Festplatten
/proc/scsi/* SCSI-Laufwerke und -Controller
/proc/sys/* System- und Kernel-Informationen
/proc/uptime Zeit in Sekunden seit dem Rechnerstart
/proc/version Kernel-Version
über das /proc/sys-Verzeichnis können Sie sogar Kernel-Parameter im laufenden Betrieb verändern. Eine sehr ausführliche Beschreibung aller /proc-Dateien finden Sie im Buch zur Linux-Kernel-Architektur.
Beim Login (und beim Wechsel des Benutzerkennzeichens während einer Terminalsitzung) wird auf diese Dateien zugegriffen - sie sind übrigens für alle Benutzer lesbar. Schreiben darf jedoch nur der Superuser und das Programm passwd. Da passwd von jedem Benutzer aufgerufen werden kann, ergibt sich hier eigentlich ein Widerspruch. Gelöst wird das Problem durch das UID-Bit von passwd: während das Programm läuft, nimmt der Prozess die Identität seines Eigentümers an - und der darf schreiben. Anmerkung: Ab der Unix-Version System V, Version 3 steht das Paßwort nicht mehr in /etc/passwd, sondern in einer eigenen Datei /etc/shadow. Da /etc/passwd für alle lesbar sein muß (z. B. für die Anzeige des Benutzernamens im ls-Kommando), kann man mit entsprechenden Programmen versuchen, die Paßwörter zu 'knacken'. Durch die Verlagerung der Paßwortinfo in /etc/shadow, die nur von Superuser-Prozessen gelesen werden kann, wird diese Sicherheitslücke geschlossen.
Wichtig: Das Paßwort ist in der Datei /etc/passwd verschlüsselt gespeichert. Die Verschlüsselung erfolgt beim Ändern des Passworts mit dem Programm passwd oder bei der Eingabe im Login-Programm. Verglichen werden immer nur die verschlüsselten Passwörter. Auch der Superuser kann das Paßwort nicht entschlüsseln. Wenn Sie Ihr Paßwort vergessen haben, kann er nur ihr altes Paßwort löschen, damit Sie dann ein neues eintragen können. Um das "knacken" von Login-Name und Paßwort zu erschweren, fragt das Login-Programm auch dann das Paßwort ab, wenn schon der Benutzername falsch war. Außerdem wird beim Eingeben des Passworts nichts auf dem Bildschirm angezeigt.
Login-Name:Paßwort:UID:GID:Kommentar:Home-Directory:Programm
Beispiel für einen Eintrag in /etc/passwd:
karl:x:235:100:Karl Müller:/home/karl:/bin/sh
Die Zeitdauer wird in Wochen gezählt; der Punkt "." bedeutet 0 Wochen, der Schrägstrich "/" 1 Woche, dann folgen Ziffern und Buchstaben:
Sonderfälle:
Gruppenname:Paßwort:GID:Benutzernamen
Beispiel für einen Eintrag in /etc/group:
dozenten::200:kristl,plate,rother,ries,thomas
Name:Paßwort:letzte Änderung:Min:Max:Vorwarnzeit:Inaktiv:Verfall:Kennzeichen
/etc/default/passwd:
Standardwerte für das Paßwort
und seine Gültigkeitsdauer. Einige wichtige Werte sind:
useradd [-u uid [-o]] [-g group,..] [-G group]
[-d home] [-s Shell] [-c Comment]
[-m [-k template]] [-f inactive]
[-e expire] [-p passwd]
Username
oder
useradd -D [-g group] [-b base] [-s Shell]
[-f inactive] [-e expire]
Der Befehl legt, basierend auf den angegebenen Werten in der Befehlszeile und
den Standardwerten des Systems, einen neuen User-Account an. Dabei wird der
neue Berutzer in /etc/passwd und /etc/group eingetragen und es wird ggf. ein
neues Heimatverzeichnis erstellt. Je nach Einstelleung lassen sich auch gleich noch
Dateien in das Benutzerverzeichnis kopieren. Mit dem zweiten Kommandoaufruf
(Parameter -D) lassen sich auch die Voreinstellungen für die angegebnen
Parameter ändern und man braucht diese nicht jedesmal mit angeben. Die
Konfiguration wird in der Datei /etc/default/useradd gespeichert.
| Option | Beschreibung |
|---|---|
| -u | UID Numerische User-Kennung UID. Wir normalwerweise weggelassen (es wird dann die nächsthöhere Userkennung aus der Datei /etc/passwd verwendet). Wird sie angegeben, muss der Wert positiv und einmalig sein, es sei denn die Option -o wird mit angegeben. Normalerweise werden auch Werte größer 100 verwendet, da der untere Bereich (insbesondere Werte kleiner als 100) in der Regel für System-Accounts reserviert ist. |
| -o | Erlaubt es, mehreren Benutzern die gleiche UID zu geben. |
| -g Gruppe | Definiert die primäre Gruppe, der der User angehört. Fehlt die Option, wird die Standardgruppe verwendet. |
| -G Gruppe,... | Legt weitere Gruppen fest, denen der Benutzer ebenfalls angehört. Einträge werden durch Kommata getrennt und dürfen keine Leerzeichen enthalten. |
| -c Bemerkung | Hier werden Kommentare zum jeweiligen User eingetragen. In der Regel der Klartextname und weitere Angaben. Dieses Feld wird auch von vielen Programmen genutzt (z. B. vom E-Mail-Client). Die Angaben sollten in "..." eingeschlossen werden. |
| -d Home | Heimatverzeichnis des Users, welches ggf. neu erstellt wird. Fehlt die Option wird das Standardverzeichnis (in der Regel /home/Username) verwendet. |
| -e Datum | Das Datum, an dem der Useraccount ungültig werden soll. Dieses Datum wird im Format JJJJ-MM-TT angegeben. |
| -f Zeit | Die Anzahl von Tagen, nach dem Auslaufen des Accounts, bis der Account permanent gesperrt wird. Ein Wert von 0 bedeutet keine Pufferzeit, ein Wert von -1 schaltet dieses Feature ab. Der voreingestellte Wert ist -1. |
| -k Vorlage | Legt das Verzeichnis fest, in dem die Standarddateien liegen, die ins Home-Verzeichnis des Users kopiert werden. Wird kein Verzeichnis angegeben, werden die Standarddateien aus /etc/skel verwendet. |
| -m | Legt fest, dass das Heimatverzeichnis des Users erstellt werden soll, falls es nicht schon existiert und es werden die Vorlagedateien (siehe -k) hineinkopiert. Ohne die Angabe von -m wird weder das Homeverzeichnis erstellt, noch werden irgendwelche Dateien kopiert. |
| -s Shell | Loginshell des Benutzers. Fehlt diese Option, wird die Standard-Login-Shell (/bin/sh oder /bin/bash) verwendet. |
Normalerweise ist der Account nach dem Anlegen noch gesperrt, indem ein * oder ! im Passwortfeld des /etc/shadow-Eintrags eingetragen wurde. Man muss also noch perr passwd-Kommando ein Passwort vergeben. Bei useradd kann zwar mittels der Option -p ein Passwort eingetragen werden, aber es muss sich dabei schon um das verschlüsselte Passwort handeln - wenig praktikabel.
adduser UsernameBei Systemen, die auf Debian-Linux basieren gibt es noch eine interaktive Alternative (genauer ein interaktives Frontend) für useradd: Mit diesem Kommando wird ein neuer Benutzer ohne weitere Kommandozeilenoptionen angelegt, wobei das Programm während der Erstellung des Benutzeraccounts alle wichtigen Daten interaktiv abfragt. Weitere Unterschiede zwischen beiden Programmen bestehen darin, dass man bei adduser auch ohne Options-Liste einen kompletten Account bekommt (für Anfänger ideal). Dabei erhält der neu erstellte Benutzer eine eigene Gruppe, deren Name mit dem Usernamen identisch ist. Auch wird in jedem Fall ein Heimatverzeichnis angelegt, wenn es nicht schon existiert. Ebenso wird auch die Vorlage für neue Home-Verzeichnisse aus /etc/skel ins Heimatverzeichnis kopiert und mit den Benutzer- und Gruppenrechten des neuen Users versehen. Während der Erstellung des Accounts wird man aufgefordert, das neue Passwort einzugeben (inklusiver Wiederholung gegen Tippfehler). Alle Einstellungen für Defaultwerte werden in der Konfigurationsdatei /etc/adduser.conf eingetragen. Diese Datei ist gut dokumentiert (inklusive Manpage zur Syntax). Das folgende Listing zeigt ein Aufrufbeispiel:
# adduser schnucki
Adding user `schnucki'...
Adding new group `schnucki' (1010).
Adding new user `schnucki' (1010) with group `schnucki'.
Creating home directory `/home/schnucki'.
Copying files from `/etc/skel'
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Changing the user information for schnucki
Enter the new value, or press ENTER for the default
Full Name []: Lanzelot Schnucki
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [y/N] y
Einziger Nachteil ist, dass die Kommentarzeile anschliessend einige Kommata und
Leerzeichen enthält, die dann doch von Hand weggeputzt werden sollten:
schnucki:x:1010:1010:Lanzelot Schnucki, , , ,:/home/schnucki:/bin/bash
usermod [-u uid [ -o]] [-g group] [-G group,...]
[-d home] [-s Shell] [-c Comment]
[-m [-k template]] [-f inactive]
[-e expire] [-l Login Name]
Username
Neu ist eigentlich nur die Option -l, die nur den Loginnamen ändert, aber sonst
keine weiteren Änderungen (wie etwa der Name des Homeverzeichnisses) automatisch
vornimmt. Der Benuter darf nicht eingeloggt sein, wenn das Kommando ausgeführt
wird.
Um alle Dateien (nicht Directories) eines Benutzers zu löschen, kann das Kommando find (siehe später) verwendet werden (für UID wird die User-ID des Benutzers eingesetzt):
find / -user UID -type f -exec rm -f {} ";"
Probleme können durch Dateien des zu löschenden Benutzers verursacht werden, auf die andere Benutzer ein Link gesetzt haben. Man kann diese Dateien z. B. den betroffenen Benutzern zuordnen.
| Option | Beschreibung |
|---|---|
| --remove-home | Das Home-Verzeichnis des zu löschenden Benutzers entfernen. |
| --remove-all-files | Löschen aller Dateien des Benutzers, nicht nur das Home-Verzeichnis und die Mail-Dateien. Mit dieser Option muss gleichzeitig --remove-home angegeben werden. |
| --backup | Fertigt vorher ein Backup der zu löschenden Dateien in Form einer komprimierten Datei an, die ins aktuelle Verzeichnis abgelegt wird. |
| 0 | Power-Down: Ausschalten des Rechners |
| 1 | Administrativer Level: z. B. Einrichten neu eingebauter Platten oder andere Hardware-Initialisierungen. Oft auch "s" oder "S" (Singleuser = Einzelbenutzer-Modus). |
| 2 | Multiuser-Modus ohne Netzwerkanbindung |
| 3 | Multiuser-Modus mit Netzwerkanbindung (Normal-Level) |
| 4 | Frei für benutzerdefinierten Modus |
| 5 | Firmware-Modus: z. B. Diagnose und Wartung; oft nur mit spezieller Floppy zu starten |
| 6 | Shutdown und Reboot: Wechsel zu Level 0 und dann sofortiges Hochlaufen |
Die Zuordnung der Level kann auch von der oben angeführten abweichen. Der Wechsel des Levels wird durch spezielle Kommandos erreicht, z. B. shutdown, telinit, (re)boot oder halt. So ist beispielsweise auch ein Bootstrap von einem bestimmten Datenträger (Floppy, CD-ROM, ...) möglich.
Beispiel: Reboot des Systems nach 2 Minuten (Solaris): shutdown -g120 -i6 -y Shutdown sendet eine Nachricht an alle eingeloggten Benutzer, bevor der eigentliche Prozess beginnt.
Nach dem Einschalten des Rechners und dem Durchlaufen des Power On Self Test wird normalerweise der Bootsektor der ersten Festplatte ausgeführt. Unter Linux wird hierfür meistens der Bootmanager GRUB verwendet. Dieser Bootmanager kann auch unterschiedliche Betriebssysteme von beliebigen Festplatten oder anderen Speichermedien (CD-ROM, DVD etc.) starten.
Bei Linux ist der Ablauf noch etwas komplexer. Der Bootmanager lädt den zu bootenden Kernel. Dieser braucht zum Fortsetzen des Bootvorgangs ein Root-Dateisystem. Deshalb legt er eine "initiale Ramdisk" an, indem die Datei initrd in den Speicher geladen und als Dateisystem montiert wird. (Ja, Linux kann eine Datei als "Hülle" eines Dateisystems verwenden und wie eine Platte bzw. Plattenpartition verwenden.) Damit läft ein minimales Linux, das nun alle folgenden Aufgaben ausführen kann.
Egal, ob der Reboot-Vorgang durch einen Shutdown oder durch Einschalten des Rechners ausgelöst wurde, sind die Systemaktivitäten im Prinzip immer gleich:
Diese doch relativ komplexen Aktionen werden wieder über spezielle Shell-Scripts gesteuert. Bei BSD-Unix war der Aufbau dieser Scripts relativ einfach. Die Datei /etc/rc enthält alle beim Systemstart auszuführenden Kommandos. Innerhalb von rc werden eventuell weitere rc-Dateien aufgerufen, z. B.:
| /etc/rc.local | Start lokaler Software |
| /etc/rc.net | Start der Netzwerksoftware |
| /etc/rc.single | Start im Single-User-Modus |
Später wurde das System dahingehend erweitert, daß es für jeden Runlevel eine eigene rc-Datei gab (rc0, rc1, rc2, usw.). Ab System V ist das System der rc-Dateien vereinheitlicht worden. Für jeden Runlevel exisitiert ein Verzeichnis unter /etc, wobei der Name der Verzeichnisse einheitlich /etc/rcx.d ist (x steht für den Runlevel, es gibt also rc0.d, rcs.d, rc2.d, usw.). Im Verzeichnis /etc/init.d (manchmal auch /sbin/init.d) sind alle Programme (oder Shell-Scripts) gespeichert, die beim System-Boot aufgerufen werden könnten. In den Verzeichnissen rcx.d sind nun nur noch Links auf diese Programme enthalten. Alle Links folgen ebenfalls einer festen Namenskonvention:
Die so entstandenen rc-Scripts werden in lexikalischer Reihenfolge aufgerufen und zwar zuerst die K-Dateien, dann die S-Dateien. Die Zahl im Namen legt also die Reihenfolge innerhalb der K- oder S-Gruppe fest. Die K-Dateien dienen zum Löschen (Kill) von Prozessen, die S-Dateien zum Starten von Prozessen. Angenommen, es existieren folgende Dateien in /etc/rc.d:
Dann ist die Aufruf-Reihenfolge:
K30tcp K40nfs S20sysetup S30tcp S40nfs S75cron S85lp
Dabei sind K-und S-Dateien mit ansonsten gleichem Namen lediglich Hinweise darauf, dasselbe Programm aufzurufen. So wird z. B. bei den Dateien K30tcp und S30tcp das Programm oder Script /etc/init.d/tcp einmal mit dem Parameter "stop" und einmal mit dem Parameter "start" aufgerufen. Man kann also durch Anlegen von Links das Hochfahren des Systems sehr gezielt steuern. Das entsprechende rc-Script wird dann auch sehr einfach, es läßt sich folgendermaßen skizzieren:
#!/bin/sh # Wenn Directory /etc/rc2.d vorhanden ist if [ -d /etc/rc2.d] ; then # K-Files bearbeiten for f in /etc/rc2.d/K* ; do if [ -s $f ]; then /bin/sh $f stop fi done # S-Files bearbeiten for f in /etc/rc2.d/S*; do if [ -s $f ] ; then /bin/sh $f start fi done fi
Ein von der rc-Datei aufgerufenens Script in /etc/init.d könnte dann z. B. so aussehen:
#!/bin/sh
case $1 in
'start')
# aufgerufen als "Kxxcron"
# Lockfilelöschen
rm -f /var/spool/cron/FIFO
if [ -x /etc/cron ] ; then
/etc/cron
fi
;;
'stop')
# aufgerufen als "Sxxcron"
pid=`/bin/ps -e | grep 'cron$' | sed -e 's/^ *//' -e 's/ .*//'`
if [ "$pid" != "" ] ; then
/bin/kill -9 $pid
fi
;;
esac
Natürlich muss es einen Prozess geben, der die Ausführung der oben beschriebenen Scriptdateien vornimmt. Dazu wird vom Kernel die Root-Partition der Platte im Read-Only-Modus montiert und dort nach dem Programm /sbin/init gesucht und ausgeführt (andere Aufgaben von init wurden jan schon besprochen). Das Init-Programm liest seine Konfiguration aus der Textdatei /etc/inittab. In dieser Datei werden der Standard-Runlevel und das Script festgelegt, das beim Starten des Rechners ausgeführt wird:
id:3:initdefault: si::sysinit:/etc/init.d/rcSDieses Script sorgt für Basisaktionen, z. B. das Überprüfen der Dateisysteme, das Montieren der Platten, das Stellen der Systemuhr usw. Anschließend folgen die Script-Aufrufe für die einzelnen Runlevel, der jeweils in der zweiten Spalte angegeben ist. Dabei können auch mehrere Runlevel bei einem Startscript angegeben werden.
Die inittab enthält auch die Startbefehle fü die sechs virtuellen Konsolen:
1:2345:respawn:/sbin/getty 38400 tty1 2:23:respawn:/sbin/getty 38400 tty2 ...Sie erinnern sich, "respawn" heißt für init, daß der getty-Prozess nach seiner Terminierung neu gestartet werden soll.
In der Datei /etc/inittab können prinzipiell beliebige Programme gestartet oder auch das Verhalten beim Drücken der als "Affengriff" bekannten Tastenkombination [Strg]+[Alt]+[Entf] geregelt werden:
ca:12345:ctrlaltdel:/sbin/shutdown -h nowEs geht sogar noch weiter. Bei Embedded Systems (etwa einem DSL-Router) kann anstelle von init gleich die (einzige) Anwendung gestartet werden. Das Booten erfolgt in diesem Fall aus dem ROM und das ganze System läuft in der Ramdisk ab. Es sind auch alle Zwischenstufen zwischen diesem Minimalsystem und dem Standard-Desktop-System möglich, etwa ein System, das zwar mit init startet, aber dann nicht als Multiusersystem weiterbootet.
Mit den Kommandos init <Runlevel> oder telinit <Runlevel> kann der Runlevel gewechselt werden. Dazu fährt init den aktuellen Runlevel herunter (Ausführen aller K-Scripten) und dann den neuen Runlevel hoch (Ausführen aller S-Scripten). Der aktuelle Runlevel kann mit dem Befehl /sbin/runlevel abgefragt werden.
Aufgrund seiner Konzeption startet der SysV-Init die Prozesse immer in einer vorgegebenen Reihenfolge und er startet einen Prozess fast immer erst, wenn der vorherige Prozess fertig abgeschlossen wurde. Dieses schrittweise Vorgehen macht den Bootvorgang zwar zuverlässig, aber auch relativ langsam. Inzwischen werden beim Bootewn eies Unix- oder Linux-Systems so viele Dienste gestartet, dass der Bootvorgang relativ lange dauert. Man kann natürlich die nicht notwendigen Dinge lahmlegen, indem man einfach das entsprechende Script in /etc/init.d umbenennt (z. B. durch Anhägen von ".inaktiv").
Schon seit einiger Zeit gibt es Versuche, dieses Konzept zu überarbeiten oder wenigstens zu modifizieren. So werden zum Beispiel bei einigen Linux-Distributionen alle Prozesse in einem Runlevel gleichzeitig gestartet. Alternativen zu init waren u. a. InitNG, eINIT und Launchd in Mac OS X. All diese Konzepte haben eines gemeinsam: sie sind zielorientiert. Es wird also vorher festgelegt, welche Dienste am Ende des Startvorganges laufen sollen. Die Abhängigkeiten werden durch eine sinnvolle Startreihenfolge definiert.
Upstart ist ein Ubuntu-Projekt, das den Systemstart von Ubuntu (bzw. Linux) beschleunigt. Upstart verwendet dabei einen neuen Ansatz. Programme und Dienste werden nicht mehr zielorientiert, sondern ereignisbasiert geladen und gestartet, wodurch mehrere Dienste parallel und voneinander unabhängig gestartet werden können. Hierdurch wird die Startgeschwindigkeit verbessert. Dabei ersetzt Upstart den klassischen Init-Prozess. Mittel- bis langfristig soll Upstart zum zentralen System von Ubuntu zur Verwaltung von Ereignissen ausgebaut werden. Dann könnte Upstart auch andere ereignisbasierte Dienste wie at oder cron ablösen. Sowohl Upstart als auch SysV-Init werden vom Kernel als erster Prozess mit der Id 1 gestartet, sobald dieser gebootet und etwaige Boot-Skripte aus der Initial Ramdisk abgearbeitet hat.
Viele Dienste hängen vom Funktionieren bestimmter Hardware ab. So können manche Dienste erst gestartet werden, wenn die dazu nötige Hardware intitalisiert wurde. Oder es können, um ein anderes Beispiel zu nehmen, Netzdienste erst gestartet werden, wenn die Verbindung zum Netzwerk steht. Die Entwicklung steht noch am Anfang, aber Ubuntu verwendet Upstart schon seit einiger Zeit und auch die "testing"-Version von Debian setzt es ein. Um den reibungslosen Betrieb der Distributionen zu ermöglichen, erfolgen etliche Teile der Initialisierung mit Hilfe des Kompatibilitätsscriptes in /etc/init.d/rc durch die üblichen Init-Dateien. Die Ausweitung auf Teile des Systemstarts erfolgt kontinuierlich in jeder neuen Ubuntu-Versionen, wobei temporale Events noch nicht integriert sind.
Upstart wartet also auf bestimmte Events. Sobald ein Ereignis eintritt, führt Upstart alle passenden Aktionen in der Form spezieller Scripten aus. Diese wecken wiederum alle notwendigen Dienste oder richten die Hardware ein. Die einzelnen Scripte, die beim Eintreffen eines Events ausgeführt werden sollen, werden bei Upstart "Jobs" genannt und enden in der Regel auf ".conf". Die Scripte befinden sich alle im Verzeichnis /etc/init (anfangs in /etc/event.d). Wie beim Init wird auch bei Upstart das Programm /sbin/init als erster Prozess gestartet. Die Datei /etc/inittab gibt es bei Upstart nicht mehr. Viele der Upstart-Scripte sind noch im Kompatibilitätsmodus geschrieben. So wird man bei vielen Job-Scripte (Runlevel-Scripte), derzeit feststellen, dass sie nichts anderes tun, als das entsprechende rc-Skript aufzurufen. Das zentrale Werkzeug ist nun initctl, das Init-Jobs startet oder stoppt, Signale verschickt und den Status abfragt. So gibt beispielsweise der Befehl initctl list eine Liste aller Init-Jobs und deren Status aus. Mit initctl [start | stop] Job werden Init-Jobs gestartet bzw. beendet.
Wie sieht nun ein solcher Job aus? Im Prinzip handelt es sich natürlich wieder um eine Art Shellscript - jedoch mit einigen Besonderheiten. Das sieht man am Besten an einem Beispiel:
# /hallo_welt.conf: # Experimente mit Upstart # Eine Beschreibung mitgeben: description "Popliges Upstart-Beispiel" # wann starten bzw. stoppen (das "!" bedeutet "NOT"): start on runlevel [23] stop on runlevel [!23] env enabled=1 PATH_BIN=/bin/bash exec echo "Bonjour Monde" > /var/log/Bonjour.logHiermit wird einfach der Text "Bonjour Monde" in die Datei /var/log/HalloWelt.log geschrieben. Die Bedingungen fü den Event sind hier sehr einfach, bei Runlevel 2 und 3 wird es gestartet und beim Wechsel in einen anderen Runlevel beendet. Beachten Sie, dass in die eigentlich Aufgabe (im Beispiel echo) per exec gewechselt wird. In einer Upstart-Job-Description steht hinter den Schlüsselworten "start on" das Ereignis, bei dem das hinter exec eingetragene Programm startet. Die Prozesse laufen allesamt im Vordergrund und nicht wie bei SysV-Init im Hintergrund. Umgekehrt werden die Prozesse gestoppt, wenn die Bedingung hinter "stop on" erfüt ist.
Es lassen sich auch mehrere Events, auf die der Job reagieren soll, logisch miteinander verknüpfen, z. B.:
start on (runlevel [123] and (stopped kdm or stopped gdm))
Vor bzw. nach der eigentlichen Ausführung des Scripts lassen sich noch beliebige Befehle einfügen, die zwischen "pre-start script" und "end script" hinterlegt werden. Auch für die Ausführung nach dem Starten des Haupt-Scripts lassen sich auf die gleiche Weise Befehle zwischen "post-start script" und "end script" unterbringen. Fall nun jemand einwirft, dass nach einem exec das Script verlassen wurde: Das exec läuft unter der Kontrolle von Upstart ab.
Mit Hilfe der Schlüsselwörter "pre-stop script" und "post-stop script" lassen sich Befehle angeben, die Upstart vor und nach dem Beenden des Dienstes ausführen soll - etwa für Aufräumarbeiten, z. B.:
post-stop exec rm -f /var/run/hello.pidFür unser Bonjour-Script hätte ich beispielsweise noch für das Vorhandensein der Datei sorgen können:
pre-start script touch /var/log/Bonjour.log end script
Beim Stoppen eines Jobs bearbeitet Upstart nur den per exec gestarteten Prozess. Dieser erhält zuerst ein Terminate-Signal (SIGTERM). Beendet sich der Prozess nicht, wird er kurz danach per Kill-Signal (SIGKILL) abgebrochen.
Da es /etc/inittab nicht mehr gibt, müssen auch die Terminalkonsolen per Upstart eingerichtet werden. Deshalb gibt es auch hier ein "respawn". Da der Job rc, nach dem Aufruf der Init-Skripte des jeweiligen Runlevels terminiert, starten die tty-Jobs nach Beenden des rc-Jobs und nicht etwa bei dessen Start, z. B.:
start on stopped rc stop on runlevel [!2345] respawn exec /sbin/getty -8 19200 tty1Das Programm getty läuft im Vordergrund und wird (wie früher von Init) von Upstart überwacht. Durch das Schlüsselwort "respawn" weiss Upstart, das der Prozess immer wieder neu gestartet werden muss, wenn er sich beendet. Um eine Überlastung des Systems zu verhindern, wenn ein Prozess amok läuft und immer wieder startet, kann die "Startgeschwindigkeit" beschränkt werden:
start on stopped rc stop on runlevel [!2345] respawn respawn limit 10 120 exec /sbin/getty -8 19200 tty1Das Limit für den Neustart wird hier mit "respawn limit" auf 10 Versuche innerhalb von 120 Sekunden festgelegt.
Dabei können Client und Server über ein Netzwerk miteinander kommunizieren. Es ist also unerheblich, ob die Informationen, die auf einem Bildschirm dargestellt werden, auf dem lokalen Rechner laufen oder auf einem anderen Rechner im Netz.
Client und Server verständigen sich mit einem Protokoll, dem sogenannten X-Protokoll. Dieses Protokoll nutzt als Transportbasis meist TCP/IP, aber der Betrieb auf reinen Unix-Sockets ist ebenso möglich (lokaler Betrieb). Technisch gesehen ist das X-Protokoll die eigentliche Definition des X-Window-System.
Zur Verdeutlichung noch ein Hinweis: bei den meisten anderen Client-Server Systemen (beispielsweise Datenbanksystem, Mailsystem usw.) befindet sich der Client näher am Benutzer als der Server. Bei X ist das naturgemäß umgekehrt, da der Server Tastatur und Bildschirm verwaltet und den Clients zur Verfügung stellt.
X begann auch als Protokollspezifikation. Nachdem vor einigen Jahren immer schnellere Rechner mit Bitmap-Grafikdisplays erhältlich waren, ging das MIT mit der Unterstützung von einigen Firmen (dem X Consortium) daran, das Windowsystem für die Zukunft zu spezifizieren. Es wurde dabei zuerst ein Protokoll festgelegt. Danach begann das MIT mit einer Beispielimplementierung des Protokolls, um zu zeigen, wie es funktioniert und welche Möglichkeiten es bietet. Nach einigen Jahren begannen dann Firmen mit dem Vertrieb von kommerziellen Implementierungen des X Protokolls.
Da das Protokoll allerdings recht aufwendig war - es teilt sich der Klarheit wegen in mehrere streng getrennte Schichten - waren die anfänglichen Implementierungen relativ langsam. Wesentlich langsamer jedenfalls als solche Windowsysteme, die direkt auf das Bitmap-Display zugreifen. Es folgten dann immer mehr Programme, die auf dem X Window System aufbauen.
Das X Window System ist jedoch keine einheitliche Benutzeroberfläche, die ein bestimmtes "Look-and-Feel" bietet. X könnte aussehen wie der Macintosh Finder oder wie Microsoft Windows. Dieses deshalb, weil das X-Protokoll sehr einfach ist. Man kann lediglich grafische Elemente (Linien, Kreise, Widgets etc.) und Zeichen auf dem Bildschirm anzeigen. Das Protokoll enthält keine komplexeren Grafikelemente wie Buttons oder Menus. Deshalb gibt es auch keine Aussagen über Aussehen von Anwendungsprogrammen (Style Guide), so daß sich mehrere Standards gebildet haben.
Möchte man zum Beispiel einen Knopf (Button) mit einer Aufschrift, so muß dieser aus Linien und Text selbst zusammengesetzt werden. Dies kann dem Programmierer aber auch durch ein Toolkit abgenommen werden. Diese Toolkits bestimmen dann hauptsächlich das Look-and-Feel.
Das Pointing-Device muß nur zum Zeigen auf Punkte fähig sein. Es könnte zum Beispiel auch ein Touch-Screen sein. Oder eine Maus mit nur einer Taste. Soll ein Programm konform zur X-Spezifikation sein, müssen alle Funktionen mit nur einer Maustaste ausführbar sein. Dies kann man z. B. erreichen, indem man beim Drücken der Maustaste auch noch gleichzeitig gedrückte Tasten (Control, Meta, etc.) abfragt.
Softwareseitig gibt es folgende Prozesse:
| X Server |
Der X-Server ist - wie gesagt - das Programm, das alle Bildschirmausgaben übernimmt und
alle Eingaben von der Tastatur und der Maus verarbeitet. Daher ist ein Teil des
X-Servers sehr an die Hardware des Rechners gebunden (Farb- oder
Schwarzweiß-Bildschirm, Art der Tastatur, Anzahl der Maustasten,
Bildschirmgröße ...). Ein Programm, das etwas auf dem Bildschirm
ausgeben will, schickt einen diesbezüglichen Auftrag an den X-Server, der
daraufhin eine Linie zeichnet, einen Text ausgibt oder tut, was immer das
Programm von ihm verlangt. In der anderen Richtung gibt der X-Server Meldungen
an die X-Clients, wann immer der Benutzer eine Eingabe getätigt hat, sei es
das Bewegen der Maus, das Drücken einer Maustaste oder eine Eingabe
über die Tastatur. Die Programme können dann entscheiden, was sie mit
dieser Eingabe anfangen und wie (oder ob überhaupt) sie darauf reagieren.
Vorteil dieser Konfiguration ist, daß nur der X-Server über die
Möglichkeiten der vorhandenen Hardware informiert sein muß. Die Clients
können diese Information vom Server erfragen, wenn sie sie brauchen,
müssen sich ansonsten aber nicht darum kümmern.
| ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X Clients | Jedes Programm, das auf einem X-Bildschirm ein Fenster darstellen will, ist ein X-Client. Der X-Client bittet den Server, gewisse Aufgaben (eben das Zeichnen des Fensters) für ihn zu übernehmen. Sie müssen dazu Aufträge im X Protokoll an den Server schicken. | ||||||||||||||
| Window-Manager |
Ein Client hat den anderen gegenüber einen gewissen Sonderstatus: der
Window-Manager, hier heißt er ctwm. Er stellt dem Benutzer Mittel
zur Verfügung, mit deren Hilfe dieser das Aussehen seiner
Benutzeroberfläche bestimmen kann. Insbesondere kann der Window-Manager die
Größe und die Position der Fenster anderer Clients beeinflussen. Die
Clients können dem Window-Manager Hinweise geben, wo und in welcher
Größe sie ihre Fenster plaziert haben wollen. Der Window-Manager
muß diese Hinweise zwar nicht berücksichtigen, die meisten gängigen
Systeme tun dies aber. Durch die Funktion des Window-Managers ergibt sich,
daß es zumindest problematisch ist, zwei Window-Manager für einen
Bildschirm zu starten. Daher prüfen Window-Manager beim Start in der Regel,
ob bereits ein anderer Window-Manager für den Bildschirm existiert und
brechen in diesem Fall die Arbeit ab.
Die Rahmen und Titelbalken, die die einzelnen Fenster verzieren, sind nicht Teil des jeweiligen Clients, sondern werden vom Windowmanager um die Fenster herumgezeichnet, damit durch ihre Betätigung Funktionen des Windowmanagers ausgelöst werden können. Der Windowmanager bestimmt somit auch "look-and-feel" der Benutzeroberfläche. Beachten Sie aber, daß der Window-Manager aber auch nur ein ClientProzess ist. Es gibt alle möglichen Window-Manager:
| ||||||||||||||
| Desktop Environment | Ein Desktop-Environment (Schreibtischoberfläche) ist eine grafische Arbeits-
bzw. Benutzerumgebung von Betriebssystemen in Form einer grafischen Shell
(ein Eingabe-Ausgabe-System oder Mensch-Maschine-Schnittstelle), bei der
die grafische Benutzeroberfläche die Schreibtischmetapher umsetzt. Die
Fenster-Hintergrundebene wird dabei als "Desktop" oder "Schreibtisch"
bezeichnet. Auf ihr können geschlossene Dokumente abgelegt werden und
über ihr schweben die Programm-Fenster, die den Schreibtisch teilweise
oder ganz überdecken und geöffnete Dokumente darstellen. Die Desktop-Umgebung
ist entweder vom Hersteller des Betriebssystems vorgegeben (Windows, macOS)
oder kann vom Benutzer frei ausgewählt werden (bei Unix-, BSD-, Linux-Systemen).
Weit verbreitete Desktop-Umgebungen auf unixoiden Systemen sind CDE (Common Desktop Environment), Gnome, KDE (K Desktop Environment) Plasma, Xfce, Unity, LXDE (Lightweight X11 Desktop Environment), Cinnamon oder MATE. Sie alle können auch parallel installiert werden. In der Regel bringt ein Desktop-Environment auch noch ein Paket von Anwendungen mit. Ursprünglich beschrieb der Begriff "Desktop Environment" ein Framework aus Softwarebibliotheken, das Werkzeuge u. a. zur grafischen Wiedergabe von typischen Elementen des Desktop-Environments bereitstellt, zum Beispiel Fenster mit Titelleisten, Schaltflächen, Menüs und anderen Steuerelementen. Durch Verwendung dieser Elemente durch mehrere Anwendungsprogramme erhält die grafische Benutzeroberfläche (GUI) ein einheitliches Erscheinungsbild und Bedienkonzept. Man spricht auch von einem "Look and Feel" der Benutzeroberfläche. Anmerkung:"Cut-and-Paste" konnte X schon immer. Einfach in einem Fenster den Text markieren und dann im anderen Fenster die mittlere Maustaste drücken - geht immer und überall. |
X ist netzwerkfähig. Clients können ihre Grafikausgabe auch auf Server machen, die auf anderen Rechnern im Netz laufen. Als Netzwerkprotokolle können dabei verschiedene Protokolle eingesetzt werden. Bei Unix ist dies meist TCP/IP.
Auf dem Zielrechner muß dem Server mitgeteilt werden, daß er Requests vom Senderechner zulassen darf. Das geschieht mit dem Kommando:
xhost +senderechnerAuf dem Senderechner muß man dem Client mitteilen, daß die Ausgabe nicht auf dem eigenen Display erscheinen soll, sondern beim Zielrechner. Dazu setzt man entweder die Environment-Variable
export DISPLAY=zielrechner:0oder man schreibt beim Aufruf des Programms
clientprogramm -display zielrechner:0Zum Beispiel startet man auf einem fernen Rechner in einem Terminal mit dem Kommando
firefox -display myhost:0.0 &den Browser und leitet dessen Ausgabe auf den eigenen Bildschirm (myhost:0.0).
Die Zahl hinter dem Rechnernamen gibt die Nummer des Displays an. Sie kann auch eine Nachkommastelle haben, z.B. 0.0. Normalerweise haben aber die Rechner nur ein Display mit der Nummer 0.
Noch einfacher geht es mit SSH. Ein xterm mit einer Shell auf einem Remote-Rechner erhält man mit dem Kommando: ssh -X [SSH_OPTIONS] [USER@]HOST SSH regelt automatisch die Verwendung von X-Window. Man muß also auf dem Remote-Rechner weder eine X-Window-Authorisierung noch die Environment-Variable DISPLAY setzen.
Der Mechanismus funktioniert folgendermaßen: von Systemprozessen wird eine Prozedur aufgerufen, welche die Session steuert. Wenn sich die Prozedur beendet, übernehmen wieder die Systemprozesse die Steuerung.
process xdm is
while (true)
do
xlogin;
if (Benutzer hat eigene Session-Prozedur)
then fuehre Benutzer-Session-Prozedur aus
else if (Benutzer hat zusätzliche Session-Prozedur)
then fuehre zusätzliche Session-Prozedur im Hintergrund aus
fi;
starte xterm im Hintergrund;
starte xclock im Hintergrund;
starte twm;
fi
done
endprocess
Bei xdm heißt die Benutzer-Session-Prozedur ".xsession" und die zusätzliche
Session-Prozedur ".xsession+". Man sollte darauf achten, daß diese Dateien
ausführbar sind. Außerdem wird die Session beendet, wenn sich die
Prozedur beendet. In der Prozedur sollten also alle Kommandos im Hintergrund
gestartet werden, außer dem letzten, das während der gesamten Session
laufen muß. Dies ist meist der Window-Manager. Wird dieser dann mit Exit
beendet, wird auch die Session mit allen anderen Clients beendet.
Ein anderes Problem liegt am Konzept des TCP/IP-Protokolls. Da nicht alle Rechnertypen, die am Internet hängen, das Konzept einer Benutzer-ID haben, ist diese auch bei TCP/IP nicht vorgesehen. Auf den X-Server kann also nicht nur der augenblickliche Benutzer der Konsole zugreifen, sondern alle Benutzer des Rechners. Und das in beliebiger Form. Ein anderer Benutzer kann zum Beispiel den gesamten Bildschirminhalt überschreiben.
Bei jedem Anmelden an einem Rechner generiert das Programm xdm, das die Anmeldemaske zur Verfügung stellt, einen Schlüssel und legt ihn in der Datei .Xauthority im HOME-Verzeichnis des Benutzers ab. Jedes X-Programm, das der Benutzer dann startet, sucht in dieser Datei nach dem Schlüssel und gibt ihn dem Server beim Aufbau der Verbindung an. Nur wenn dieser Schlüssel mit dem übereinstimmt, der beim Login generiert wurde, wird die Verbindung tatsächlich aufgebaut, ansonsten wird der Aufbauversuch vom Server zurückgewiesen. Auf diese Art wird verhindert, daß jeder Benutzer seine Fenster auf den Bildschirm eines anderen Benutzers legen und diesen dadurch bei seiner Arbeit behindern kann. Voraussetzung für die Sicherheit des Systems ist natürlich, daß die Rechte für die Datei .Xauthority richtig gesetzt sind. Nur der Eigentümer der Datei darf dafür das Lese- und Schreibrecht haben, alle anderen Benutzer nicht einmal das Leserecht, da sie sonst den Schlüssel aus der Datei herauslesen könnten.
X ermöglicht unter anderem jedem Programm, das eine Verbindung zum X-Server aufbauen kann, das Mitlesen von Tastatureingaben, die auf dem Rechner vorgenommen werden. Darunter können natürlich auch Paßworteingaben sein (zum Beispiel bei einem rlogin). Daher darf der Zugriff auf den Server auf keinen Fall unkontrolliert freigegeben werden.
xterm [Optionen]
oder
xterm [Optionen] & (als Hintergrundprozess)
Optionen:
breite x höhe +xkoord +ykoord
'breite' und 'höhe' geben die Fenstergröße (in Buchstaben) an, 'xkoord' und 'ykoord' die Position (in Pixeln). Ein xterm-Fenster hat gemäß Voreinstellung 24 Zeilen mit 80 Zeichen Breite.
Rechnername [Benutzer]
Die Auswahl der Schriftart erfolgt mit dem Parameter -fn. Die Schriftnamen unter X11 sind etwas komplex; weiter unten wird diese Nomenklatur noch etwas erlätert.Momentan genügt das Wissen, dass es ein Programm gibt, das alle im System vorhandenen Schriften auflistet: xlsfonts. Sein Aufruf listet alle Schriften auf:
-adobe-courier-bold-o-normal--10-100-75-75-m-60-iso8859-1
-adobe-courier-bold-o-normal--11-80-100-100-m-60-iso8859-1
-adobe-courier-bold-o-normal--12-120-75-75-m-70-iso8859-1
...
Mit xfontsel kann man sich die Schriften sogar ansehen.
Um ein xterm mit einer bestimmten Schrift zu starten, ruft man es mit Parameter auf:
xterm -fn adobe-courier-bold-o-normal--10-100-75-75-m-60-iso8859-1 &X11 verwaltet den Bildschirm als zweidimensionale Fläche mit kartesischem Koordinatensystem. Die obere linke Ecke entspricht der Position 0,0. Die untere, linke Ecke wird durch die maximale Auflösung bestimmt. Ein X-Client kann mit dem Parameter -geometry Größe und Position des Fensters auf dem Schirm angeben. Beginnen wir mit der Größe. Das xterm-Fenster soll anstatt der Standardgröße von 80 Spalten und 24 Zeilen nun 90 Spalten und 30 Zeilen besitzen:
xterm -geometry 90x30 &Nach dem -geometry folgt die Angabe von Spalten und Zeilen (mit einem "x" dazwischen). Wem das Wort "geometry" zu lang ist, kann es auch mit "g" abkürzen (meistens).
Achtung: Die Angabe von Zeilen und Spalten bezieht sich beim xterm auf Zeichen, nicht auf Pixel. Graphikorientierte Programme rechnen hier mit Pixeln, zeichenorientierte Programme mit Zeichen. Um also etwa ein Programm wie xclock in der Größe zu ändern, muss in Pixeln gerechnet werden.
Die zweite Aufgabe von -geometry ist die Positionierung eines Fensters auf dem Schirm. Dazu wird der Offset zum Rand des Schirms angegeben, ein Pluszeichen meint den oberen bzw. den linken Rand, ein Minuszeichen den unteren bzw. rechten. Je nach verwendeten Zeichen + oder - ergibt sich die Ecke des Bildschirms und des Fensters, auf die sich die Koordinaten jeweils beziehen. Es gibt vier Möglichkeiten:
xterm -geometry +10+50 &positioniert die obere linke Ecke des Terminalfensters 10 Pixel vom linken Rand und 50 Pixel vom oberen Rand entfernt. Bei dieser Angabe sind übrigens immer Pixel die Masseinheit. Um sich z. B. auf die untere linke Ecke zu beziehen schreiben Sie:
xterm -geometry -10-50 &Es ist sogar möglich, die Bezugskanten zu mischen. Die Zeile
xterm -geometry +10-100 &positioniert das Fenster so, dass sein linker Rand 10 Pixel vom linken Rand des Bildschirms entfernt ist und seine untere Begrenzung 100 Pixel vom unteren Rand.
Die Angaben von Größe und Position lassen sich kombinieren, wobei immer die Größe zuerst angegeben wird, danach folgt (ohne Leerzeichen aber mit Vorzeichen + oder -) die Positionsangaben. Um ein xterm mit 90 Spalten und 30 Zeilen an der Position 10,100 zu erhalten schreiben Sie:
xterm -geometry 90x30+10+100 &Wird keine Angabe zur Position gemacht, so übernimmt der Window-Manager die Positionierung.
Zur Einstellung der Farbe dienen in der Regel die Parameter -fg für die Vordergrundfarbe (foreground) und -bg für den Hintergrund (background). Das Farbmodell von X wird weiter unten besprochen. Auch hier existiert ein Programm, das die Namen aller bekannten Farben auflistet: showrgb. Es liest einfach nur die Datei /var/X11R6/lib/rgb.txt, in der die Farbnamen und Farben definiert sind. Um ein xterm mit blauem Hintergrund und gelber Schrift zu erhalten, geben Sie folgendes Kommando ein:
xterm -bg blue -fg yellow &Mit Font, Geometrie und Farben kann man schon sehr viel Individualität in seine X-Oberfläche bringen. Die Festlegung der Programmeigenschaften über die Kommandozeile kann zu recht langen Kommandos füren, wie das folgende Beispiel zeigt:
xterm -geometry 90x30-10-10 \
-fn -adobe-courier-bold-o-normal--10-100-75-75-m-60-iso8859-1 \
-fg blue -bg Yellow &
Deshalb gibt es noch einen andere Möglichkeit:
XTerm*font: -adobe-courier-bold-o-normal--10-100-75-75-m-60-iso8859-1 XTerm*Background: yellow XTerm*Foreground: blue XTerm*geometry: 90x40Die Analogie zu der Kommandozeile im Beispiel oben ist offensichtlich. Die Ressource-Werte werden dann beim nächsten Start des X11-Servers in den Speicher geladen und aktiviert. Jedesmal, wenn Sie jetzt xterm ohne Parameter aufrufen erscheint ein Fenster mit dem entsprechenden Aussehen.
Ressourcen sind hierarchisch aufgebaut. Jedes Programm greift auf eine Klasse von Resourcen zu (xterm zum Beispiel auf Xterm). Darunter können sich Komponenten des Programms befinden und am Ende der Hierarchie stehen Eigenschaften. Teile der Hierarchie können auch durch Wildcards ('*') ersetzt werden.
Was kann man nun überhaupt mit Ressourcen festlegen? Eigentlich alles! Welche Ressourcen ein Client versteht, kann in der Regel in seiner Manualpage nachgelesen werden. Die grundsätzliche Form eines Eintrags ist immer die Gleiche:
Clientname*Resource: Wert
Es gibt noch einen netten Trick, für ein Programm mehrere Alternativ-Ressourcen zu erstellen: die Verwendung von symbolischen Links. Sie können beispielsweise folgende Zeilen in der Datei .Xresources aufnehmen:
gelbterm*font: -adobe-courier-bold-o-normal--10-100-75-75-m-60-iso8859-1 gelbterm*Background: yellow gelbterm*Foreground: black gruenterm*font: -adobe-courier-bold-o-normal--10-100-75-75-m-60-iso8859-1 gruenterm*Background: green gruenterm*Foreground: blackJetzt erstellen Sie noch zwei symbolische Links auf /usr/X11R6/bin/xterm:
ln -s /usr/X11R6/bin/xterm /usr/X11R6/bin/gelbterm ln -s /usr/X11R6/bin/xterm /usr/X11R6/bin/gruentermDamit gibt es nun zwei neue Programme, gelbterm und gruenterm. Nachdem die Datei .Xresources neu geladen wurde (Neustart des X-Servers oder Aufruf von xrdb -merge .Xresources) können Sie die Programme aufrufen.
In der Regel haben Clients sehr viele Resourcen, wesentlich mehr als mögliche Kommandozeilenparameter. So kann einem Xterm beispielsweise durch die Resource XTerm*scrollbar:true eine Scrollbar hinzugefügt werden.
Damit alle diese Resourcen auch über die Kommandozeile möglich sind, gibt es den Parameter -xrm, dem ein Resourcenstring folgen kann. Damit ist es möglich, Programmeinstellungen über die Kommandozeile vorzunehmen, für die es zwar Resourcen gibt aber keine Parameter.
#RGB #RRGGBB #RRRGGGBBB #RRRRGGGGBBBBwobei R, G und B die hexadezimalen Werte für die FarbenrRot,grün und blau bedeuten. An jeder Stelle, an der Farbangaben gemacht werden können können auch diese Werte statt Farbnamen stehen - zum Beispiel würde xterm -bg #B7BB6E ein Terminalfenster öffnen, dessen Hintergrundfarbe ein hässliches Grün wäre. Es gibt auch die Möglichkeit, Farbnamen zu definieren. In der Datei /var/X11R6/lib/rgb.txt sind 738 fest definierte Farben enthalten, jeweils mit ihren numerischen Werten und einem Namen.
Diese Datei hat ein leicht zu überblickendes Format. Jede Zeile repräsentiert eine Farbe, die ersten drei Felder der Zeile enthalten die dezimalen Werte für die Rot-, Grün- und Blauanteile, das vierte Feld den Namen der Farbe. Jeder Wert für die Farbanteile kann von 0 bis 255 reichen (24-Bit-Darstellung mit 16 Millionen Farben). Bei Grafikmodi mit weniger möglichen Farben werden die Werte umgerechnet. Zum Beispiel:
250 235 215 AntiqueWhite 255 239 213 papaya whip 255 239 213 PapayaWhip 255 235 205 blanched almond 255 235 205 BlanchedAlmond 255 228 196 bisque
Um eigene Farben zu definieren, müssen Sie nur diese Datei entsprechend erweitern. Nach einem Neustart des X-Servers existiert die neue Farbe. Zum Beispiel fügen Sie die fiolgende Zeile hinzu:
183 187 110 KotzeGruenNach einem Neustart des Display-Servers kann nun mit xterm -bg KotzeGruen ein X-Terminal aufgerufen werden, dessen Hintergrund in dieser Farbe gestaltet ist. Im gesamten X11-System steht diese Farbe jetzt zur Verfügung. Aber Vorsicht: Sollte einmal eine Anwendung auf einem anderen Server laufen, dessen Datei rgb.txt diese Zeile nicht enthält, kann er mit der Farbe nichts anfangen.
Hersteller Gewicht Breite Pixels XAufl Sp Zeichensatz
| | | | | | |
-b&h-lucida-medium-r-normal-sans-18-180-75-75-p-106-iso8859-1
| | | | | | |
Schriftart Neigung Stil Punkte YAufl Durchschn. Optionen des
Zeichen- Zeichensatzes
breite
Dabei bedeuten im Einzelnen:
Oft werden statt einzelner Angaben auch ein Sternchen angegeben, dann wird die erste passende Einstellung genommen. So wird ein * bei der Angabe der Neigung automatisch zu einem "i".
In der Regel werden Daemons nicht durch einen Benutzer gestartet, sondern automatisch beim Wechsel in einen anderen Runlevel oder beim Systemstart. Dadurch stellen Daemons einen wesentlichen Anteil des Bootprozesses dar, da bei den meisten UNIX-Systemen. Typische Daemon-Programme sind bei auch Prozesse, die die Hardwarekonfiguration bzw. -Überwachung vornehmen. Auch periodische Aufgaben oder zu festgelegten Zeiten anfallende Aufgaben werden mit Hilfe von Daemons realisiert (crond). Es gibt beim BSD-UNIX ein Bild des BSD-Daemons (Teufelchen mit Turnschuhen und Dreizack), das auch die Titelleiste dieses Skripts ziert.
Das Wort leitet sich vom griechischen Wort "Daimon" ab. "Daimon" stand in der griechischen Mythologie für "Geist der Abgeschiedenen". Bei den alten Griechen und auch bei den frühen Christen waren Dämonen Schutzgeiser und Zuteiler des Schicksals, weshalb man "eudaimon" (glücklich) und "kakodaimon" (unglücklich) sein konnte. Erst im frühen Mittelalter wurden die Dämonen "damonisiert", als verteufelt. In ganz ähnlicher Bedeutung existiert im Deutschen das nur selten gebrauchte Wort "Schemen" für Geister, Gespenster und Spukgestalten.
Der Dämon ist auch verwandt mit "daimonion", dem Gewissen oder Schicksal. Interessant sind die weiteren Beziehungen von "daimon": einerseits zu dem griechischen Wort für Volk "dämos", was eigentlich "abgeteiltes Gebiet" bedeutet. Wir finden es als Wortstamm wieder im deutschen Wort "Demokratie".
 Zum Inhaltsverzeichnis Zum Inhaltsverzeichnis |
 Zum nächsten Abschnitt Zum nächsten Abschnitt |
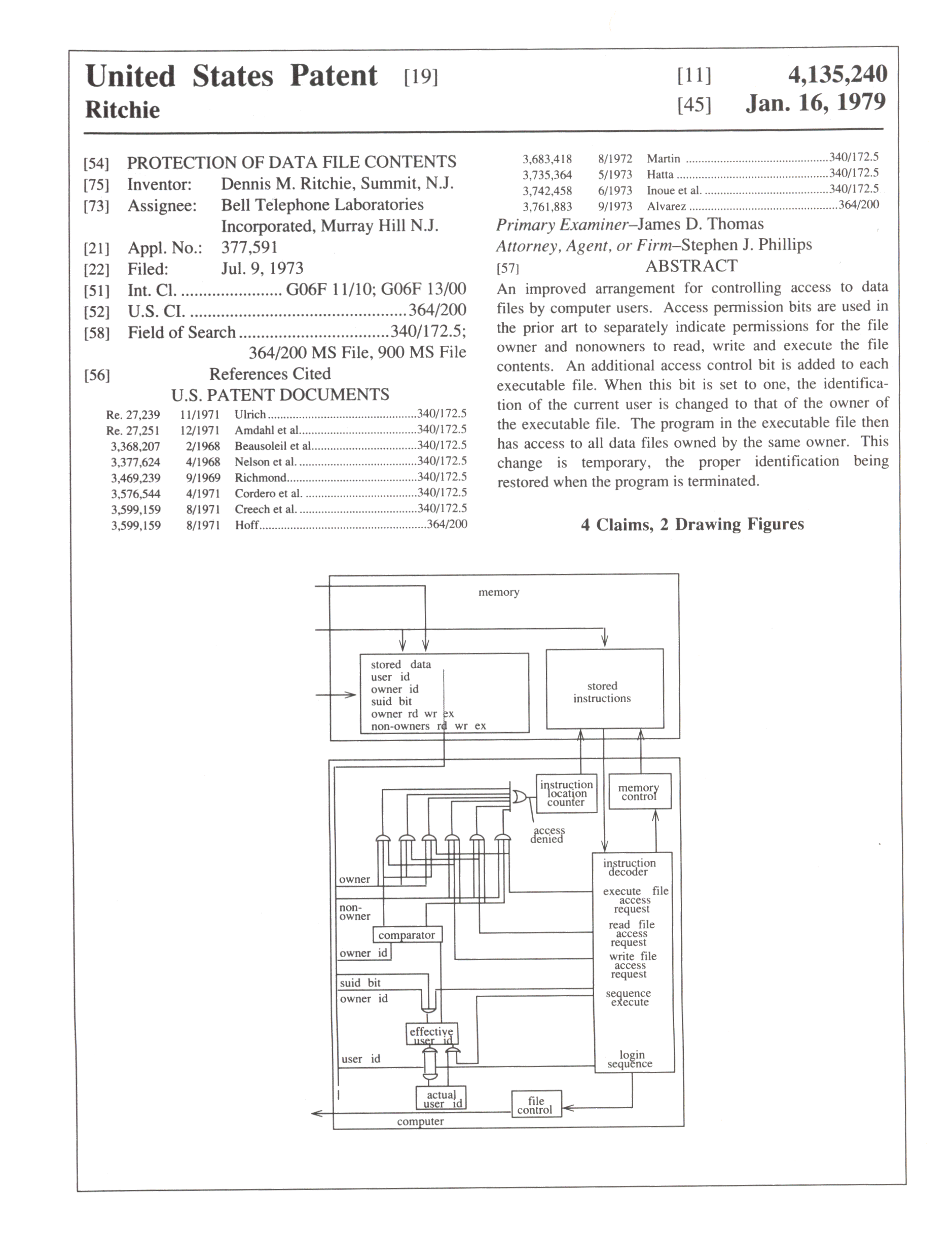{kind=link}