 |
Vorlesung "UNIX"von Prof. Jürgen Plate |
|
Vorlesung "UNIX"von Prof. Jürgen Plate |
Jetzt erscheint auch die Notwendigkeit des ps-Kommandos unter anderem Licht - man kann sich so über laufende Hintergrundprozesse informieren. In der Regel werden Hintergrundprozesse abgebrochen, wenn sich der Benutzer am Terminal abmeldet (Logoff), denn sie sind ja Kindprozesse des aktuellen Shell-Prozesses. Es gibt jedoch Möglichkeiten, Prozesse auch nach dem Logoff "am Leben" zu erhalten. UNIX kennt recht mächtige Möglichkeiten für Hintergrundprozesse:
find / -user markus -print &
2354
Es wird die Nummer (PID) des neu erzeugten Prozesses ausgegeben (2354) und die
Shell meldet sich sofort wieder mit dem Eingabeprompt. So wie das Kommando oben
eingegeben wurde, hat es aber noch einen Nachteil:
Alle Ausgaben von find, auch die Fehlerausgaben, gelangen nach wie vor
auf den Bildschirm, was u. U. die Arbeit im Vordergrund empfindlich stört.
Durch Ein-/Ausgabeumleitung kann der Hintergrundprozeß zum Schweigen gebracht
werden:
find / -user markus -print > liste 2> /dev/null &
2354
Weitere Kommandos für den Start von Hintergrundprozessen sind:
(No Hang Up) Dieses Kommando ermöglicht es, einen Prozeß nach dem Logoff weiterlaufen zu lassen. Wenn die Ausgaben nicht explizit umgelenkt wurden, werden Standardausgabe und Standard-Fehlerausgabe in die Datei nohup.out im zuletzt aktuellen Verzeichnis geschrieben. Sollte dies nicht möglich sein (Zugriffsrechte nicht ausreichend), wird nohup.out im Home-Directory des Benutzers angelegt. Bei einigen Anlagen gibt es das Kommando "batch" mit analogen Eigenschaften.
Neben anderen können für kill folgende Signalnummern verwendet werden:
| 0 | SIGKILL | Terminate (beim Beenden der shell) |
| 1 | SIGHUP | Hangup (beim Beenden der Verbindung zum Terminal oder Modem) |
| 2 | SIGINT | Interrupt (wie Ctrl-C-Taste am Terminal) |
| 3 | SIGQUIT | Abbrechen (Beenden von der Tastatur aus) |
| 9 | SIGKILL | Kann nicht abgefangen werden - Beendet immer den empfangenden Prozeß |
| 15 | SIGTERM | Terminate (Software-Terminate, Voreinstellung) |
Die Datei /usr/include/Signal.h enthält eine Liste aller Signale. Später wird das Kommando trap besprochen, mit dem man innerhalb von Shell-Skripts gezielt auf einzelne Signale reagieren kann.
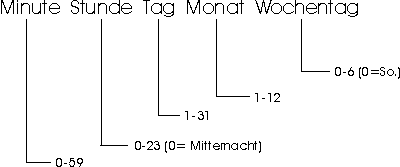
Statt einer expliziten Zahlenangabe sind auch folgende Angaben möglich:
| 0 0 * * * | Jeden Tag um Mitternacht |
| 0 9 * * 1 | Jeden Montag um 9 Uhr |
| 30 10 1 * 1 | Jeden Monatsersten und jeden Montag um 10 Uhr |
| 0,30 8-18 * * * | Täglich alle halbe Stunde aber nur zwischen 8 und 18 |
| 0,5,10,15,20,25,30,35,40,45,50,55 * * * * | Alle 5 Minuten |
| */5 * * * * | Auch alle 5 Minuten |
| Alias | Funktion | Entspricht |
|---|---|---|
| @reboot | Wird nach dem booten ausgeführt | |
| @hourly | Einmal in der Stunde | 0 * * * * |
| @daily | Einmal am Tag | z. B. 0 0 * * * |
| @midnight | Einmal am Tag um Mitternacht | 0 0 * * * |
| @weekly | Einmal in der Woche | 0 0 * * 0 |
| @monthly | Einmal im Monat | 0 0 1 * * |
| @annually | Einmal im Jahr | 0 0 1 1 * |
Die Crontab-Dateien müssen immer mit dem crontab-Kommando bearbeitet werden, denn beim Systemstart werden die Dateien vom cron-Daemon eingelesen und dieser speichert die Zeitpunkte jeder einzelnen Aktion. Sollte sich an der Zeit der letzten Veränderung der Datei /etc/crontab etwas geändert haben, aktualisiert der cron-Daemon alle Änderungen in den cron-Verzeichnissen. crontab sorgt ebenfalls dafür, dass der cron-Daemon die Daten aktualisiert.
Wenn der cron-Daemon einen bestimmten Job zu einer Zeit ausführen soll, zu der der Rechner nicht angeschalten ist, dann verfällt dieser Job. Oft ist es der Fall, dass manche tägliche cron-Jobs um zwei oder drei Uhr ausgeführt werden sollen oder die wöchentlichen am Sonntag (Tag 0). Wenn ein Rechner aber weder Sonntags, noch Nachts läuft, werden diese Jobs niemals ausgeführt. In solchen Fällen kann anachron (siehe unten) helfen.
Die Benutzung von crontab kann für bestimmte Benutzer gesperrt werden. Dazu dienen die Dateien /usr/lib/cron/cron.allow und /usr/lib/cron/cron.deny, für die gilt:
Die Tabellen (crontabs) stehen je nach UNIX-Variante in /etc/cron.d oder /usr/lib/cron. Für allgemeine cron-Jobs existiert zusätzlich die oben erwähnte Datei /etc/crontab.
Beim Erstellen von cron-Jobs (und at-Jobs, siehe unten) sollte man sich nicht darauf verlassen, daß außer ein paar Standardvariablen irgendwelche Voreinstellungen verwendbar sind. Benutzen Sie entweder nur absolute Pfade oder eine explizite Pfad-Definition. Will man keinen Output per E-Mail erhalten, muß der Output (stdout und stderr) umgeleitet werden (Man kann den Job sehr schnell von E-Mail auf Dateiausgabe umstellen, indem man alle Kommandozeilen mit geschweiften Klammern einrahmt und dahinter die Ausgabeumleitung setzt: { .... } > Datei 2>&1. Will man nur wenige Kontrollausgaben erzeugen, lassen sich auch mittels echo "..." >> logfile cron-Jobs loggen. Bei root-cron-Jobs kann dafür auch die allgemeine Logdatei /var/adm/messages (manchmal auch /var/log/messages) verwendet werden.
Des weiteren existiert zusätzlich für systemweite Jobs die Datei /etc/crontab, deren Syntax von der oben beschriebenen leicht abweicht. Nach der Zeitangabe folgt noch eine zusätzliche Spalte mit dem Namen des Users unter dessen Berechtigung der jeweilige Job ablaufen soll.
Bei Linux gibt es Erweiterungen dieser Datei: Erstens enthält die Datei /etc/crontab bereits Einträge und zweitens existieren zusätzlich die Verzeichnisse /etc/cron.daily, /etc/cron.weekly und /etc/cron.monthly. Dies soll dem ungeübten User den Umgang mit dem cron-Daemon erleichtern. Er muss einfach seine Shell-Scripte in das passende Verzeichnis kopieren und schon werden diese täglich, wöchentlich oder monatlich ausgeführt. Das ist auch der Grund, warum ein Linux-PC irgendwann nach dem Booten anfängt heftig zu arbeiten - da werden diese Scripte abgearbeitet (bevor der User wieder abschaltet).
Jedesmal, wenn anacron aufgerufen wird, liest es seine Konfigurationsdatei ein. Wenn ein Job die letzten n Tage nicht ausgeführt wurde, wobei n die angegebene Periode dieses Jobs ist, führt anacron ihn aus. Das Programm erzeugt jeweils einen Eintrag in einer speziellen Zeitmarkendatei, die es für jeden Job erstellt, so dass es immer weiss, wann der Job zuletzt ausgeführt wurde. anacron ist also kein Daemon, der die ganze Zeit läuft, sondern muss entweder über ein init-Script oder den cron-Daemon regelmässig gestartet werden.
Man kann einfach zeitgesteuerte Aufgaben in Intervallen von einem, sieben oder 30 Tagen starten um tägliche, wöchentliche oder monatliche Ausführung zu erzwingen. anacron führt seine Jobs aus, wenn der letzte Ablauf eines Jobs länger als die genannte Intervallzeit her ist. Somit wird ein Job auch dann ausgeführt, wenn der Rechner das nächste Mal angeschalten wird und nicht - wie bei crontab - wenn das nächste Wochen- oder Monatsende erreicht ist.
Jedesmal, wenn anacron aufgerufen wird, liest es seine Konfigurationsdatei /etc/anacrontab ein, in der die Aufgaben ähnlich wie bei crontab definiert sind. Wenn ein Job länger als die angegebene Perionde nicht ausgeführt wurde, führt anacron ihn aus. Das Programm erzeugt dann einen Eintrag in einer speziellen Zeitmarkendatei, die es für jeden Job erstellt, so dass es weiss, wann der Job zuletzt ausgeführt wurde. Wurden alle Kommandos ausgeführt, wird anacron beendet. anacron ist also kein Daemon, der die ganze Zeit läuft, sondern muss entweder über init-Scripts oder den cron-Daemon regelmässig gestartet werden.
Die Konfigurationsdatei von anacron ist sehr einfach aufgebaut. Sie enthält entweder Variablenzuweisungen, die der Umgebung zugewiesen werden, in der der entsprechende Befehl ausgeführt werden soll, oder Befehlszeilen der Form
Periode Delay Job-Id Kommando
Die Periode gibt die Anzahl von Tagen an, die mindestens zwischen der letzten Ausführung und
der nächsten Ausführung des Jobs vergangen sein müssen. Dabei sind auch die Aliase
@daily für 1, @weekly für 7 und @monthly für 30 zugelassen.
Delay ist ein Wert in Minuten, der verwendet werden kann, damit nicht alle anacron-Jobs
gleichzeitig gestartet werden und so den Rechner unnötig belasten. Die Job-Id ist ein
beliebiges Wort, dass alle Zeichen ausser Leerzeichen und Schrägstrich enthalten darf. Mit
Hilfe dieses Wortes wird der Dateiname der Zeitmarkendatei erstellt. Am Ende der Zeile steht dann der
auszuführende Befehl. Die folgende /etc/anacrontab-Datei würde die die tägliche,
wöchentliche und monatlichen cron-Jobs (siehe oben) ausführen:
SHELL=/bin/sh PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root #period in days delay in min. job-identifier command 1 5 cron.daily nice run-parts /etc/cron.daily 7 25 cron.weekly nice run-parts /etc/cron.weekly @monthly 45 cron.monthly nice run-parts /etc/cron.monthly
at -r Auftragsnummer(n) Löscht den genannten Auftrag
at -l [Auftragsnummer(n)] Listet die noch auszuführenden Aufträge
Fehlt bei at -l die Nummer, werden alle Aufträge gelistet.
Ein Beispiel für das at-Kommando: Am 1. Oktober um 22 Uhr wird das Ausdrucken einer langen Datei gestartet.
at 2200 Oct 1
lp -m superlangedatei.txt
CTRL-D
job 545900100.a at Tue Oct 1 22:00:00 1991
Mit at -r 545900100.a könnte man den o. g. Job wieder löschen.
Bevor sudo die Ausführung eines Programms erlaubt, muss dieses Recht für einen bestimmten Benutzer und für ein bestimmtes Programm in der Datei /etc/sudoers angegeben werden. Zum Bearbeiten der Datei muss das Programm visudo eingesetzt werden, welches das gleichzeitige Ändern der Datei von mehren Stellen aus verhindert und die gröbsten Fehler erkennt. Es ist nicht zwangsläufig an den Editor vi gebunden, sondern verwendet das Programm, das durch den Inhalt der Variablen EDITOR festgelegt ist. Hier können nicht nur einzelne User berechtig werden, bestimmte oder alle Kommandos privilegiert auszuführen (wahlweise mit oder ohne Passworteingabe), sondern es lassen sich auch Privilegien für ganze Gruppen (z. B. "admin") vergeben.
Natürlich gibt es noch weitere Kommandos für Dateisysteme, z. B. zum Partitionieren der Platte (bei Linux heißt es "fdisk", bei Sun-OS "format"). Eine neue Platte muß zuerst mit einem Dateisystem versehen ("formatiert") werden. Das Kommando dazu heißt "mkfs". Gebrauch und Parameter muß man der jeweiligen Dokumentation entnehmen. Zum Überpr&uum;fen der Platten gibt es das Kommando "fsck". Es wird normalerweise beim Booten automatisch ausgeführt. Für den Fall des manuellen Aufrufs sollte auch hier die Dokumentation des jeweiligen Systems konsultieren.
In dieser Datei werden alle Partitionen/Dateisysteme festgelegt, die beim Bootvorgang automatisch eingebunden werden sollen. Hier kann man auch Mountpoints für CD-ROMS oder USB-Sticks festlegen, die dann automatisch verwendet werden, wenn eine CD eingelegt oder ein USB-Stick eingesteckt wird. Die Definitionen werden zeilenweise angelegt und durch Leer- oder Tabulatorzeichen in sechs Abschnitte unterteilt: Dateisystem, Mountpoint, Typ, Optionen, Dump und Pass. Zum Beispiel:
# Dateisystem Mountpoint Typ Optionen Dump Pass /dev/sda1 / ext4 defaults 0 1Folgende Beispiele zeigen die Verwendung. Die einzelnen Abschnitte werden anschließend erläutert.
# Verwendung eines Labels LABEL=root / ext4 defaults 0 1 # Verwendung der UUID UUID=7388c376-7a04-4242-abcd-d3d4021d536a / ext4 defaults 0 1 # Verwendung der Gerätedatei /dev/sda1 / ext4 defaults 0 1
In den Beispielen wurde jeweils defaults als Option verwendet, für weitere Informationen siehe Optionen.
Das Dateisystem wird entweder durch ein Label, die UUID, die Gerätedatei oder ein weiteres definiertes Stichwort spezifiziert:
Der Mountpunkt bestimmt, an welcher Stelle im Verzeichnisbaum das Dateisystem eingehängt wird. Hier gibt es einen Konsens, basierend auf dem Filesystem Hierarchy Standard (FHS). Dateisysteme, die nur temporär eingebunden werden, legt man direkt unter /mnt ab. Auch, wenn das Verzeichnis /media laut FHS Unterverzeichnisse für Wechseldatenträger wie z. B. USB-Sticks oder SD-Karten vorgesehen ist, ist dort ein dauerhaftes Mounten von zusätzlichen Festplatten immer noch besser, als diese unter /mnt einzuhängen. Darüber hinaus kann man im eigenen home-Verzeichnis Unterverzeichnisse als Mountpunkte erstellen und weitere Festplatten dort einhängen. Bei Servern ist es vielfach üblich, /, /var und /home als getrennte Dateisysteme (Partitionen) zu verwenden und diese in der fstab auch so zu definieren.
Zum Mounten (deut. "montieren")eines Dateisystems muss dessen Typ angegeben werden. Es besteht ausserdem die Möglichkeit der automatischen Typ-Erkennung. Durch die Verwendung von FUSE (zum Beispiel SSHFS) können weitere Optionen verfügbar werden. Hierzu ist die Dokumentation des jeweiligen FUSE-Moduls konsultieren.
| Typ | Verwendung/Bezeichnung | Bemerkung |
|---|---|---|
| auto | Standardwerte setzen | Automatische Erkennung des Dateisystems |
| ext2/3/4 | ext-Dateisysteme | Bei Verwendung von ext2, ext3, oder ext4 |
| iso9660 | CDs und DVDs | Dateisysteme nach ISO 9660-Level 2 und 3 |
| udf | meist DVDs | Ablösung von ISO 9660 |
| jfs | Journaling File System | Vor allem für LVM interessant |
| nfs | NFS-Shares einbinden | Verwendung für das Network File System |
| ntfs/ntfs-3g | Microsoft NTFS | ntfs-3g bietet Schreibzugriff |
| reiserfs | Reiser FS | Für das Einbinden von Reiser FS 1 bis 3 |
| swap | Swap-Partitionen | Kein direkter Dateizugriff möglich, nur Swap |
| ramfs | Ramdisks | |
| tmpfs | Ramdisks | nutzt im Gegensatz zu ramfs auch den Swap-Platz |
| vfat | Microsoft FAT 12/16/32 | Meist auf USB-Sticks verwendet |
| xfs | XFS | Häufig bei NAS-Lösungen oder HDD-Recordern |
| btrfs | B-tree FS | Noch in der Entwicklung/im Betastadium |
Der Typ auto sollte nur bei Wechseldatenträgern zur Verwendung kommen, bei denen man sich nicht sicher sein kann, welches Dateisystem verwendet wird.
Die Optionen steuern den Zugriff auf das jeweilige Dateisystem. Mehrere Optionen werden durch Komma getrennt (ohne Leerzeichen!).
| Option | Wirkung |
|---|---|
| defaults | Setzt rw, suid, dev, exec, auto, nouser und async |
| dev/nodev | Gerätedateien auf dem Dateisystem werden interpretiert/nicht interpretiert. |
| exec/noexec | Das Ausführen von Dateien wird erlaubt/verboten |
| gid | Definition der Gruppen-ID mittels gid=users |
| uid | Definition der User-ID mittels uid=benutzername |
| suid/nosuid | Das SUID-Bit wird berücksichtigt/nicht berücksichtigt. |
| auto/noauto | Der Datenträger wird automatisch beim Booten eingehängt oder nicht. |
| ro/rw | Nur Lesezugriff bzw. Lese- und Schreibzugriff möglich. |
| sw | Verwendung als Swap-Dateisystem. |
| sync/async | Es wird alles direkt auf den Datenträger geschrieben (sync) bzw. der Cache verwendet (async). |
| user/nouser | Jeder Benutzer darf das Gerät einhängen (user) bzw. es darf nur root (nouser). Aushängen darf immer nur der Benutzer, der das Gerät eingehängt hat. |
| users | Jeder Benutzer darf das Gerät einhängen und aushängen. |
| umask=000 | Angabe einer user mask für den Zugriff - siehe Kommando umask. |
| noatime und nodiratime | Keine Protokollierung von Zugriffszeiten für Dateien oder Verzeichnisse in der Inodetabelle speichern. Dies reduziert die Datenträgerzugriffe. Empfehlenswert für SSDs und SD-Karten. |
| errors=remount-ro | Bei auftretenden Fehler im Betrieb wird das Dateisystem im Read-Only-Modus neu eingebunden. |
| noauto,x-systemd.automount | Automatisches Einbinden durch systemd beim ersten Zugriff. |
Die Dump-Anweisung steht heute auf 0 und wurde ursprünglich zu Backup-Zwecken verwendet. Auf aktuellen Systemen gibt es zuverlässigere und schnellere Datensicherungsmethoden, so dass dieser Wert immer auf 0 gelassen werden sollte.
Die Pass-Anweisung wird vom Dateisystem-Test ausgewertet und definiert, in welcher Reihenfolge die Dateisysteme geprüft werden sollen:
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME init 1 root cwd DIR 3,2 4096 2 / init 1 root rtd DIR 3,2 4096 2 / init 1 root txt REG 3,2 27844 1782394 /sbin/init init 1 root mem REG 3,2 90210 196307 /lib/ld-2.2.5.so init 1 root mem REG 3,2 1153784 196310 /lib/libc-2.2.5.so init 1 root 10u FIFO 3,2 2339761 /dev/initctl keventd 2 root cwd DIR 3,2 4096 2 / keventd 2 root rtd DIR 3,2 4096 2 / keventd 2 root 10u FIFO 3,2 2339761 /dev/initctl ksoftirqd 3 root cwd DIR 3,2 4096 2 / ksoftirqd 3 root rtd DIR 3,2 4096 2 / ksoftirqd 3 root 10u FIFO 3,2 2339761 /dev/initctl kswapd 4 root cwd DIR 3,2 4096 2 / kswapd 4 root rtd DIR 3,2 4096 2 / kswapd 4 root 10u FIFO 3,2 2339761 /dev/initctl bdflush 5 root cwd DIR 3,2 4096 2 / bdflush 5 root rtd DIR 3,2 4096 2 / bdflush 5 root 10u FIFO 3,2 2339761 /dev/initctl ... lsof 27430 root 2u CHR 136,1 3 /dev/pts/1 lsof 27430 root 3r DIR 0,3 0 1 /proc lsof 27430 root 4r DIR 0,3 0 1797652488 /proc/27430/fd lsof 27430 root 5w FIFO 0,6 7473007 pipe lsof 27430 root 6r FIFO 0,6 7473008 pipe lsof 27431 root cwd DIR 3,2 4096 3662907 /home/plate lsof 27431 root rtd DIR 3,2 4096 2 / lsof 27431 root txt REG 3,2 108956 1831546 /usr/sbin/lsof lsof 27431 root mem REG 3,2 90210 196307 /lib/ld-2.2.5.so lsof 27431 root mem REG 3,2 1153784 196310 /lib/libc-2.2.5.so lsof 27431 root 4r FIFO 0,6 7473007 pipe lsof 27431 root 7w FIFO 0,6 7473008 pipeMit den passenden Parametern kann man die Ausgabe auf die interessierenden Zeilen eingrenzen. Gibt man mehrere Filterkriterien an, so zeigt lsof diejenigen Zeilen an, die entweder mindestens eine oder (wenn man zusätzlich -a angibt) alle Bedingungen erfüllen.
Datei(en)
Zugriffe auf diese Datei(en) anzeigen.
Beispiel: Wer benutzt gerade bash?
# lsof /bin/bash
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 19041 holzmann txt REG 3,2 511400 2322044 /bin/bash
bash 21620 root txt REG 3,2 511400 2322044 /bin/bash
bash 26921 plate txt REG 3,2 511400 2322044 /bin/bash
bash 26937 root txt REG 3,2 511400 2322044 /bin/bash
+D Verzeichnis
Zugriffe auf die Dateien unterhalb des Verzeichnisses anzeigen.
Beispiel: Wer arbeitet mit Dateien im /home-Verzeichnis?
# lsof +D /home
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 26921 plate cwd DIR 3,2 4096 3662907 /home/plate
bash 26937 root cwd DIR 3,2 4096 3662907 /home/plate
lsof 27890 root cwd DIR 3,2 4096 3662907 /home/plate
lsof 27891 root cwd DIR 3,2 4096 3662907 /home/plate
+p PIDs
Alles anzeigen, was die Prozesse mit diesen PIDs geöffnet haben.
Um mehrere PIDs anzugeben, diese mit Komma trennen. Will man
die Prozesse namentlich angeben, verwendet man lsof -c [name].
Beispiel: Welche Dateien benötigt meine Shell?
# ps
PID TTY TIME CMD
26937 pts/1 00:00:00 bash
27899 pts/1 00:00:00 ps
# lsof +p 26937
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 26937 root cwd DIR 3,2 4096 3662907 /home/plate
bash 26937 root rtd DIR 3,2 4096 2 /
bash 26937 root txt REG 3,2 511400 2322044 /bin/bash
bash 26937 root mem REG 3,2 90210 196307 /lib/ld-2.2.5.so
bash 26937 root mem REG 3,2 248132 196280 /lib/libncurses.so.5.2
bash 26937 root mem REG 3,2 8008 196313 /lib/libdl-2.2.5.so
bash 26937 root mem REG 3,2 1153784 196310 /lib/libc-2.2.5.so
bash 26937 root mem REG 3,2 40152 196316 /lib/libnss_compat-2.2.5.so
bash 26937 root mem REG 3,2 69472 196315 /lib/libnsl-2.2.5.so
bash 26937 root 0u CHR 136,1 3 /dev/pts/1
bash 26937 root 1u CHR 136,1 3 /dev/pts/1
bash 26937 root 2u CHR 136,1 3 /dev/pts/1
bash 26937 root 255u CHR 136,1 3 /dev/pts/1
-u user[,user...]
Alles anzeigen, was die Prozesse geöffnet haben, die einem der angegebenen
Usernamen oder User-ID gehören. Um mehrere User anzugeben, diese mit Komma trennen.
Beispiel: Welche Dateien werden zurzeit von Plate benutzt?
# lsof -u plate
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 26921 plate cwd DIR 3,2 4096 3662907 /home/plate
bash 26921 plate rtd DIR 3,2 4096 2 /
bash 26921 plate txt REG 3,2 511400 2322044 /bin/bash
bash 26921 plate mem REG 3,2 90210 196307 /lib/ld-2.2.5.so
bash 26921 plate mem REG 3,2 248132 196280 /lib/libncurses.so.5.2
bash 26921 plate mem REG 3,2 8008 196313 /lib/libdl-2.2.5.so
bash 26921 plate mem REG 3,2 1153784 196310 /lib/libc-2.2.5.so
bash 26921 plate mem REG 3,2 40152 196316 /lib/libnss_compat-2.2.5.so
bash 26921 plate mem REG 3,2 69472 196315 /lib/libnsl-2.2.5.so
bash 26921 plate 0u CHR 136,1 3 /dev/pts/1
bash 26921 plate 1u CHR 136,1 3 /dev/pts/1
bash 26921 plate 2u CHR 136,1 3 /dev/pts/1
bash 26921 plate 255u CHR 136,1 3 /dev/pts/1
...
-i [TCP|UDP][@host][:ports]
Die Netzverbindungen des übergebenen Hosts und Ports anzeigen. Dabei kann der Host wahlweise als Hostname oder
IP-Adresse und die Ports als Portnummern oder Servicenamen angegeben werden. Um mehrere Ports zu betrachten, kann man
Listen (z.B. ssh,www) oder Bereiche (z.B. 1-1024) angeben.
Beispiel: Welche Prozesse kommunizieren da auf Port 80 miteinander?
menetekel:/home/plate# lsof -i :80
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
apache 11299 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 26057 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 26960 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 26961 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 27026 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 27037 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 27038 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 27383 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 27402 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 27427 root 18u IPv4 7063707 TCP *:www (LISTEN)
apache 27919 root 18u IPv4 7063707 TCP *:www (LISTEN)
Es ist möglich, einen einzelnen Prozeß oder eine ganze Prozeßfamilie zu verfolgen. Wenn die von einem verfolgten Prozeß erzeugten Kindprozesse auch verfolgt werden, setzt die Protokollierung erst ein, nachdem der das Kind erzeugende Systemaufruf zurückkehrt und die ProzeßID des Kindes an den Elternprozeß zurückgibt. Zu diesem Zeitpunkt kann der Kindprozeß bereits Systemaufrufe gemacht haben, die dann nicht protokolliert sind.
Wenn strace zu einem bereits laufenden Prozeß hinzugeschaltet wird, können nur solche Kindprozesse verfolgt werden, die nach dem Hinzuschalten erzeugt werden.
Sie können das Protokoll auch in eine Datei schreiben lassen. Wenn Sie die Kinder des verfolgten Prozesses auch verfolgen, werden die Protokolle für die Kindprozesse in separaten Dateien gespeichert, deren Namen mit dem für den Stammprozeß gewählten übereinstimmen und auf die ProzeßID des jeweiligen Kindes enden.
Optionen:
ltrace leistet Ähnliches wie strace in Bezug auf die Verwendung von dynamischen Bibliotheken (Libraries) durch Prozesse.
$ ldd /bin/bash
libncurses.so.5 => /lib/libncurses.so.5 (0x40017000)
libdl.so.2 => /lib/libdl.so.2 (0x40055000)
libc.so.6 => /lib/libc.so.6 (0x40059000)
/lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000)
$ uname -a Linux menetekel 2.4.18-bf2.4 #1 Son Apr 14 09:53:28 CEST 2002 i686 unknown
$ free
total used free shared buffers cached
Mem: 512960 506016 6944 0 51296 387396
-/+ buffers/cache: 67324 445636
Swap: 497972 1740 496232
$ uptime 17:09:18 up 143 days, 59 min, 3 users, load average: 0.07, 0.07, 0.07
Die Hardware eines Rechners ist für manchen Anwender ein Buch mit sieben Siegeln. Zwar liefert Linux eine Fülle von Informationen über die verbauten Komponenten - allerdings nicht unbedingt in einer leicht verständlichen Form. Unter /proc befinden sich beim klassischen Unix nur Informationen zu Prozessen. Bei Linux findet man jedoch noch einiges mehr. Die Informationen können ganz einfach z. B. per cat-Kommando auf der normalen Konsole angezeigt werde, da es reine (Pseudo-)Textdateien sind. Bei /proc handelt es sich nämlich um ein virtuelles Dateisystem, das der Kernel anlegt und in dem die laufenden Prozesse in Unterverzeichnisse abgebildet werden. Es beansprucht keinerlei Platz auf der Festplatte, auch wenn manche Dateien scheinbar eine enorme Größe aufweisen. Allerdings erleichtert das Proc-Verzeichnis durch eine Vielzahl von Unterverzeichnissen und teilweise auch mit vieldeutigen Verzeichnisnamen die Suche nach spezifischen Informationen nicht gerade. Auch sind nicht alle Dateien bei jeder Hardware zu finden. Unter anderem finden Sie:
| /proc/cpuinfo | Informationen zur CPU (u.a. Name, Taktfrequenz, Cache-Größe) | /proc/meminfo | Informationen über den Arbeitsspeicher (u.a. Gesamtgröße, Cache, Swap) | /proc/partitions | Informationen über Partitionen des Massenspeichers (u.a. Partitionsname, | Anzahl der Blöcke) | /proc/modules | Übersicht über die geladenen Module (u.a. Name, Speicheradresse) | /proc/devices | Übersicht über vorhandene Char- und Block-Devices | /proc/version | Informationen über die Kernelversion | /proc/loadavg | aktuelle Systemauslastung | /proc/stat | Prozesse | /proc/interrupts | Übersicht über Interrupts | /proc/net/dev | Statistik der Netzwerkgeräte (u.a. übertragene Bytes, Fehler) | /proc/bus | Informationen und Übersichten über die Busse im Rechner. | /proc/bus/*/devices | Übersichten über die jeweiligen Geräte des Bus | /proc/ide | Hier finden sich die IDE-Geräte | /proc/ide/*/model | Die Modellbezeichnung des Geräts | /proc/acpi/thermal-zone/THRG/temperature | CPU-Temperatur | /proc/acpi/battery/BAT?/state | Batteriezustand | /proc/acpi/ibm/fan | Lüfterstatus | /proc/<PID>/cmdline | Kommandozeile des Prozesses mit der Nummer PID | |
Das Programm "Hardinfo" bereit dem Durcheinander durch eine ansprechende grafische Oberfläche und eine übersichtliche Präsentation der Hardware-Informationen ein Ende. Hardinfo steht unter der GPL und kann von http://freshmeat.net/projects/hardinfo heruntergeladen werden. Danach entpacken Sie das Archiv zunächst in ein temporäres Verzeichnis:
tar xjvf hardinfo-w.x.y.z.tar.bz2beziehungsweise
tar xzvf hardinfo-w.x.y.z.tar.tar.gz(w.x.y.z steht für die gerade aktuelle Version). Dann wechseln Sie in das neu angelegte Verzeichnis und richten das Programm mit dem übliche Dreisprung
./configure && make && make installein. Versuchen Sie es vorher auf jeden Fall mit dem Paketmanager Ihrer Distribution - das geht einfacher und schneller. Bei Debian ist es beispielsweise schon verfügbar und kann mittels apt-get install hardinfo eingerichtet werden.
# iostat
Linux 2.6.32-5-686 (info) 19.09.2011 _i686_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0,02 0,00 0,01 0,01 0,00 99,97
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0,26 0,45 3,97 281194 2507152
iostat besitzt zahreiche Optionen, unter anderem:
| -d | Anzeige nur der Festplatten-Daten. |
| -c | Anzeige der reinen CPU-Daten. |
| -p | Anzeige der IO-Daten je Partition. |
| -n | Anzeige der NFS-IO-Daten. |
| -x | Erweiterte Anzeige der Festplatten-Daten. |
| -t Zahl | Angabe, nach wie vielen Sekunden die Anzeige aktualisiert werden soll. |
# mpstat Linux 2.6.32-5-686 (info) 19.09.2011 _i686_ (4 CPU) 18:08:03 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 18:08:03 all 0,01 0,00 0,01 0,01 0,00 0,00 0,00 0,00 99,97Mit der Option -A wird die Ausgabe erweitert: die Statistiken werden pro Prozessor/Core angezeigt, ausserdem werden die Interrupts pro Sekunde pro Prozessor angezeigt. Gibt man am Ende der Kommandozeile eine Zahl N an, läft mpstat dauernd und aktualisiert die Anzeige alle N Sekunden.
# pidstat Linux 2.6.32-5-686 (info) 19.09.2011 _i686_ (4 CPU) 18:14:04 PID %usr %system %guest %CPU CPU Command 18:14:04 1 0,00 0,00 0,00 0,00 1 init 18:14:04 4 0,00 0,00 0,00 0,00 0 ksoftirqd/0 18:14:04 9 0,00 0,00 0,00 0,00 2 migration/2 18:14:04 10 0,00 0,00 0,00 0,00 2 ksoftirqd/2 18:14:04 12 0,00 0,00 0,00 0,00 3 migration/3 18:14:04 15 0,00 0,00 0,00 0,00 0 events/0 18:14:04 16 0,00 0,00 0,00 0,00 1 events/1 18:14:04 17 0,00 0,00 0,00 0,00 2 events/2 18:14:04 18 0,00 0,00 0,00 0,00 3 events/3 18:14:04 24 0,00 0,00 0,00 0,00 0 sync_supers 18:14:04 25 0,00 0,00 0,00 0,00 1 bdi-default 18:14:04 37 0,00 0,00 0,00 0,00 0 kseriod 18:14:04 46 0,00 0,00 0,00 0,00 3 khungtaskd 18:14:04 217 0,00 0,00 0,00 0,00 0 scsi_eh_1 18:14:04 306 0,00 0,00 0,00 0,00 0 kjournald 18:14:04 356 0,00 0,00 0,00 0,00 2 udevd 18:14:04 494 0,00 0,00 0,00 0,00 2 edac-poller 17:02:32 2889 0,00 0,00 0,00 0,00 0 kdeinit4 ...Die Option -C gestattet die Spezifizierung der zu untersuchenden Prozesse. Mit -p kann statt des Prozess-Namens die PID definiert werden. Beispiel:
# pidstat -C bash Linux 2.6.32-5-686 (info) 19.09.2011 _i686_ (4 CPU) 18:16:12 PID %usr %system %guest %CPU CPU Command 18:16:12 3675 0,00 0,00 0,00 0,00 2 bash 18:16:12 3726 0,00 0,00 0,00 0,00 1 bashMit der Option -d werden I/O-Statistiken zu den Prozessen angezeigt und -r verschafft einen Überblick der Speicherauslastung. Auch hier kann durch eine Zahl am Ende ein Dauerbetrieb initiiert werden.
| free | Arbeitsspeicherverwendung, s. o. |
| df | Speicherplatz auf gemounteten Geräten |
| uptime | Anzeige der Systemlast und der Uptime, s. o. |
| hostname | Anzeige des Hostname |
| date | Systemzeit anzeigen |
| uname | OS-Namen anzeigen |
| ifconfig | Informationen über Netzwerkgeräte (nur als root) |
| iwconfig | desgleichen für WLAN-Benutzer |
| top | kurze Systeminformationen (Last, Speicher, etc.) und Anzeige der Prozesse z. B. top -b -n 1 |
| htop | die noch komfortablere version von top |
| ps | Anzeige der Prozesse |
| pstree | Anzeige der Prozesse in Baumform |
| hddtemp | Zeigt die Temperatur von SMART-fähigen Festplatten an |
| acpi | Bietet eine komfortable Schnittstelle zu ACPI |
| dmesg | Alle Systemstart-Informationen des Kernels (u.a. auch die Erkennung der Hardware) |
| iptraf | Viele Möglichkeiten zur Überwachung des IP-Verkehrs |
| lsof | list open files, siehe oben |
| lsmod | Module auflisten |
| lspci | PCI-Bus auflisten |
| lsusb | USB-Devices auflisten |
| lsattr | Dateisystem-Attribute auflisten |
| netstat | Informationen über Netzwerkverbindungen, Routingtabelle, etc. z. B. netstat -nt (alle tcp-Verbindungen), netstat -nlt (alle Serverprozesse) |
| arp -nav | aktuelle ARP-Tabelle |
| nmap | Portscanner |
| route | eingetragene Routen |
| mount | eingebundene Dateisysteme |
| last | Tabelle der letzten Logins |
| lastb | Tabelle der letzten fehlgeschlagenen Logins (nur als root) |
 Zum Inhaltsverzeichnis Zum Inhaltsverzeichnis |
 Zum nächsten Abschnitt Zum nächsten Abschnitt |