Speechlabs
Sprachsynthese
Bei der Sprachsynthese wird ein geschriebener Text mittels maschineller Verfahren in sprachliche Laute umgewandelt. Bei modernen Text-to-Speech-Systemen unterscheidet man zwei große Bestandteile eines Systems.
- Die Umwandlung von Text in eine lautsymbolische Repräsentation.
- Die Umwandlung dieser lautsymbolischen Repräsentation in Sprachschall
(= Synthetisator).
Im ersten Teil wird ein Text in einzelne Wörter zerlegt. Dann wird die Aussprache der Worte ermittelt und es wird eine Analyse der sprachlichen Struktur vorgenommen. Durch diese Analyse werden dann die Sprechmelodie, der Sprechrhythmus und die Pausierung bestimmt. Die Resultate der Textanalyse werden in symbolischer Form in den eigentlichen Sprachsynthetisator eingegeben und dort in Sprachschall umgesetzt. Dazu gibt es mehrere Verfahren, die im nächsten Abschnitt näher erläutert werden.
- Verfahren der Sprachsynthese
- Geschichte der Sprachsynthese
- Die Logox-Technologie
- Die Sprechmelodie
- Die Entstehung einer Logoxstimme
- Stationen im Ablauf von Text-to-Speech
 Verfahren der Sprachsynthese
Verfahren der Sprachsynthese
Die Sprachsynthese überführt mittels eines maschinellen Verfahrens geschriebenen Text in gesprochene Sprache. Eine Analyse des Textes ergibt dessen Aussprache und die sprecherischen Eigenschaften. Für die Umwandlung in Sprachschall gibt es folgende Verfahren:
![]() 1. Formant- oder Regelsynthese:
1. Formant- oder Regelsynthese:
Eine "einfache" Wellenform wird durch nachgeschaltete Filter so moduliert, dass Sprachlaute entstehen. Dieses Verfahren benötigt sehr viele Regeln welche Laute in welchen Kontexten wie realisiert werden. Da alle Parameter des Systems durch Regeln zugänglich sind, lassen sich z.B. Intonation und Lautdauer leicht steuern. Dadurch kann man sehr variationsreiche Sprache generieren. Der größte Nachteil dieser Systeme ist die mangelnde Natürlichkeit der Stimme.
Englische Sprachausgaben, die mit Formantsynthese arbeiten sind: DecTalk und Eloquent.
![]() 2. Konkatenationssynthese:
2. Konkatenationssynthese:
Fast alle derzeit verwendeten Sprachausgabesysteme - auch Logox - arbeiten mit diesem Verfahren. Dabei werden sprachliche Äußerungen aufgenommen, es werden Teile daraus ausgeschnitten und wieder zu neuen Äußerungen zusammengesetzt (engl. to concatenate). Die Größe dieser Teile reicht von ganzen Wörtern und Phrasen (z.B. Ansage der Flüge im Flughafen Frankfurt) bis zu Einheiten, die kleiner als Laute sind (z.B. Mikrosegmente). Die größeren Einheiten bieten eine hohe Natürlichkeit, können aber nur bei eingeschränktem Vokabular eingesetzt werden. Kleinere Einheiten wie Halbsilben, Diphone und Laute (Allophone) können für beliebige Texte mit unbeschränktem Vokabular eingesetzt werden, wobei die Natürlichkeit leidet. Die am häufigsten verwendete Einheit ist das Diphon, das von der Mitte eines Lautes bis zur Mitte des nächsten reicht. Für jede Lautkombination gibt es ein Diphon, was im Deutschen zu einem Inventar von ca. 1600 bis 2500 Diphonen führt. Die von Logox verwendeten Mikrosegmente fassen etliche Lautkombinationen zusammen, wodurch eine Reduktion auf ca. 400 Mikrosegmente erreicht wurde, die meist kleiner sind als Diphone. Dadurch wurde eine Reduktion der Daten auf ca. 1/8 des Speicherbedarfs gegenüber Diphonsynthesen erreicht.
Ein grundsätzliches Problem bei allen konkatenativen Verfahren ist, dass die aufgenommenen Sprachbausteine sich nicht so leicht in Dauer und Tonhöhe verändern lassen. Die technischen Verfahren, die dies ermöglichen sind rechenintensiv, gehen immer mit Qualitätseinbußen bei der Sprachqualität einher und/oder führen zu einer unnatürlicheren Stimme. Das Verfahren, das bei Logox verwendet wird, beruht auf der sorgfältigen Überprüfung und Annotation des Sprachsignals, wodurch aufwendige Berechnungen entfallen.
Konkatenative Verfahren zeichnen sich durch eine natürliche Stimmqualität aus und oft sind die Menschen, die dahinterstecken, wiederzuerkennen.
![]() 3. Artikulatorische Synthese:
3. Artikulatorische Synthese:
Dieses Verfahren ist sehr rechenintensiv und wird nur zu Forschungszwecken verwendet. Die Bewegungen der "Sprechorgane" beim Sprechen werden modellhaft nachgebildet und basierend auf der Positionierung der "Sprechorgane" werden die Resonanzeigenschaften im Rachen-, Mund- und Nasenraum berechnet.
| Konkatenationssynthese | ||
| Formantsynthese | Diphonsynthese | Mikrosegmentsynthese |
| Vorteile geringer Speicherplatzbedarf einfache Veränderung akustischer Parameter |
Vorteile Wiedererkennbare Stimme einfache Regeln zur Stimmgenerierung |
Vorteile Wiedererkennbare Stimme einfache Stimmgenerierungsregeln geringer Speicherplatzbedarf Prosodiesteuerung im Zeitbereich wenige Mikrosegmente schnelle Entwicklung neuer Stimmen |
| Nachteile Synthetischer Klang aufwendige Regelsätze |
Nachteile hoher Speicherplatzbedarf aufwendige Resyntheseverfahren zur Prosodiemodellierung eingeschränkte Veränderung akustischer Parameter |
Nachteile eingeschränkte Veränderung akustischer Parameter |
Links zu guten Forschungsseiten (Sprachsynthese, Grammatik, Intonation)
Überblick über Sprachsynthese von D. Zboril, München
http://www.phonetik.uni-muenchen.de/HS/Synthese.html
Geschichte der Sprachsynthese von H. Traunmüller
http://www.ling.su.se/staff/hartmut/kempln.htm
Englische Seiten:
FAQ der newsgroup comp.speech:
http://svr-www.eng.cam.ac.uk/comp.speech/
Milesstones in speech synthesis. Demos by Dennis Klatt
http://www.icsi.berkeley.edu/eecs225d/klatt.html
HAL's Legacy. Sammlung von Artikeln zur Sprachtechnologie.
http://mitpress.mit.edu/e-books/Hal/
Geschichte der Sprachsynthese
Bereits die antiken Griechen verfügten über sprechende Statuen. Ein Schlauch führte vom Mund des Sprechers zum Mund der Statue. Priester beeindruckten derart die Seelen der armen Sterblichen.
Die ersten Versuche, menschliche Sprache maschinell zu erzeugen, wurden in der zweiten Hälfte des 18. Jahrhunderts unternommen. Ch. G. Kratzenstein, Professor der Physiologie in Kopenhagen, vorher in Halle und Petersburg, gelang es, mit an Orgelpfeifen angeschlossenen Resonanzröhren Vokale hervorzubringen (1773). Um diese Zeit hatte auch Wolfgang von Kempelen schon mit Versuchen begonnen, die ihn zum Bau einer sprechenden Maschine führten. Von Kempelen war ein Ingenius im Dienste von Maria Theresia in Wien. Er wurde 1734 in Pressburg, der damaligen Hauptstadt von Ungarn, geboren und starb 1804 in Wien. In seinem Buch "Mechanismus der menschlichen Sprache nebst Beschreibung einer sprechenden Maschine" (1791) beschrieb er auch seine Sprachmaschine ganz detailliert, damit andere sie nachbauen und verbessern mögen.
Mehr Info: http://www.ling.su.se/staff/hartmut/kempln.htm
Der "Voder" von Homer Dudley war das erste elektrische Gerät, mit dem ähnlich wie auf einem Musikinstrument, Sprache erzeugt werden konnte. Mit einer Tastatur konnte man die Resonanzfrequenzen der Sprachlaute verändern und ein Fußpedal diente dazu die Tonhöhe zu variieren. Der "Voder" wurde 1939 auf der Weltausstellung in New York dem staunenden Publikum vorgestellt.
Mehr Info: http://www.haskins.yale.edu/haskins/HEADS/SIMULACRA/voder.html (English)
Frank Cooper entwickelte ein Verfahren namens "PatternPlayback", das auf der Basis einer Spektralanalyse Laute künstlich erzeugen konnte. Ein Lichtstrahl wurde gebündelt und durch ein Tonrad moduliert. Die Modulationen wurden auf lichtempfindlichen Rollen aufgezeichnet und so reproduzierbar gemacht.
Mehr Info: http://www.haskins.yale.edu/Haskins/MISC/PP/pp.html (English)
Keines der bisher genannten Systeme konnte Texte als Eingabe automatisch verarbeiten.
Die Mikrosegmentsynthese
Mikrosegmente sind die Sprachbausteine, die für eine korrekte Aussprache von Wörtern und Sätzen nötig sind. Es handelt sich dabei um Teile von Lauten oder auch um ganze Laute, die sich je nach Kontext unterscheiden. Als oberstes Prinzip gilt dabei, die Mikrosegmente so häufig wie möglich zu verwenden. Die Generalisierungsprinzipien hinter der mehrfachen Verwendung sind sprachlich und sprecherisch motiviert. Dadurch konnte eine starke Reduktion des Speicherplatzbedarfs erreicht werden ohne eine klangliche Verschlechterung gegenüber Systemen mit 5 - 10mal größeren Sprachdaten.
Die Sprechmelodie
Der Tonhöhenverlauf beim Sprechen wird auch Intonation genannt. Bei der Sprachsynthese gibt es zwei Aspekte der Intonation: 1. Die Herleitung der Sprechmelodie aus dem Text und
2. die Umsetzung der Sprechmelodie.
In den schriftlichen Aufzeichnungen eines Textes gibt es keine klaren Angaben darüber, mit welcher Intonation ein Text vorgelesen werden soll. Sie muss aus einer Reihe von kleinen Hinweisen aus dem Kontext erschlossen werden. Viele dieser Hinweise sind durch mehr oder weniger komplexe Analyseverfahren zugänglich, andere werden auch auf längere Zeit auf einem einfachen PC nicht verwendbar sein (z.B. die Einbindung von Wissen über die Welt). Logox verfügt über eine ausgereifte Satz- und Textanalyse, in der die Position von akzentuierten Wörtern und Grenzen von sprechrhythmischen und intonatorischen Einheiten zuverlässig aus der Satzstruktur abgeleitet werden. Die Melodie kann man mit Steuerzeichen (Speechtags) im Text beeinflussen. Man kann Akzente hinzufügen oder löschen, neue Töne vergeben usw.
Die Entstehung einer Logoxstimme
Eine Logoxstimme basiert auf den gesprochenen Worten eines Menschen. Ein Sprecher liest eine Liste mit Wörtern vor. Aus den digitalisierten Aufnahmen werden Bruchstücke aus Lauten herausgeschnitten. Diese Bruchstücke nennen wir Mikrosegmente. Alle Mikrosegmente müssen so sorgfältig ausgewählt werden, dass sie bei der Verkettung in neuen Kombinationen gut zusammenpassen. Bei der Aneinanderreihung der Mikrosegmente, können alle Lautfolgen, die im Deutschen vorkommen, erzeugt werden. Insgesamt müssen etwa 350 - 400 Mikrosegmente ausgewählt werden. Bei der Auswahl werden die neuesten sprachtechnologischen Analysetools verwendet. Nach der Auswahl der ersten Mikrosegmente wird die Klangqualität ausgiebig getestet und einzelne Mikrosegmente müssen ersetzt werden. Erst dann wird die Stimme veröffentlicht.
Stationen im Ablauf von Text-to-Speech
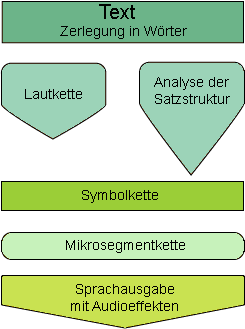 Logox übernimmt einen Text und zerlegt ihn in einzelne Wörter. Zunächst werden die geschriebenen Formen bestimmter Ausdrücke wie Geldbeträge, Einheiten, Uhrzeiten, Zahlen usw. in die Wortfolgen umgewandelt, die man beim Sprechen verwendet. So wird z.B. aus 2,48 DM die Wortfolge "Zweimarkachtundvierzig". Für jedes Wort wird eine Aussprache per Lexikon oder falls nicht vorhanden per Ausspracheregel ermittelt. Außerdem werden durch eine komplexe Analyse der Sätze die Sprechmelodie und der Sprechrhythmus bestimmt. Alle Informationen werden in eine Symbolkette kodiert, die dann an den eigentlichen Sprachgenerator übergeben wird. Dort wird diese Symbolkette mit einem Regelsatz in eine Abfolge von Mikrosegmenten umgewandelt, die erforderlichen Mikrosegmente werden ausgewählt, verknüpft und über die Soundkarte ausgegeben. Der Computer spricht.
Logox übernimmt einen Text und zerlegt ihn in einzelne Wörter. Zunächst werden die geschriebenen Formen bestimmter Ausdrücke wie Geldbeträge, Einheiten, Uhrzeiten, Zahlen usw. in die Wortfolgen umgewandelt, die man beim Sprechen verwendet. So wird z.B. aus 2,48 DM die Wortfolge "Zweimarkachtundvierzig". Für jedes Wort wird eine Aussprache per Lexikon oder falls nicht vorhanden per Ausspracheregel ermittelt. Außerdem werden durch eine komplexe Analyse der Sätze die Sprechmelodie und der Sprechrhythmus bestimmt. Alle Informationen werden in eine Symbolkette kodiert, die dann an den eigentlichen Sprachgenerator übergeben wird. Dort wird diese Symbolkette mit einem Regelsatz in eine Abfolge von Mikrosegmenten umgewandelt, die erforderlichen Mikrosegmente werden ausgewählt, verknüpft und über die Soundkarte ausgegeben. Der Computer spricht.