 Wie funktioniert "Text-to-Speech" ?
Wie funktioniert "Text-to-Speech" ?
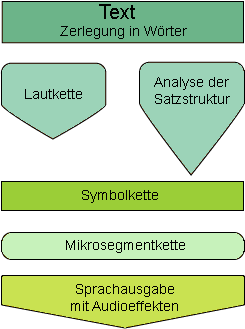
Bei diesem Verfahren der Sprachausgabe wird der Text zunächst in einzelne Wörter zerteilt und anschließend Wort für Wort weiterverarbeitet. Durch spezielle Lexika wird jeweils ein Wort in seine Aussprache umgewandelt. Zudem werden die Wörter in Wortarten eingeteilt, so dass im folgenden Schritt die Satzstruktur analysiert werden kann, um einen Betonungsverlauf zu erzeugen. Anschließend werden die "Ausspracheformen" durch ein Regelwerk in eine Folge von Mikrosegmenten umgesetzt. Den Mikrosegmentfolgen werden die jeweiligen Mikrosegmentdateien mit ihren resynthetisierten akustischen Eigenschaften zugeordnet und dann an ein Ausgabegerät (z.B. Lautsprecher) hörbar gemacht.
|
 |