 |
INTERNET - Möglichkeiten und DiensteProf. Jürgen Plate |
|
INTERNET - Möglichkeiten und DiensteProf. Jürgen Plate |
"Auf lange Sicht gesehen mag der Aspekt, die
zwischenmenschliche Kommunikation zu fördern,
sogar wichtiger werden als technische Ziele"
Andrew S. Tanenbaum in seinem Buch 'Computer-Netzwerke'.
"Das Internet ist für uns alle Neuland."
Bundeskanzlerin Dr. Angela Merkel am 19.6.2013
(ca. 40 Jahre nach der Geburt des Internets und
ca. 20 Jahre nach der Erfindung des World Wide Web)
 Pioniere des Internet: Jon Postel, Steve Crocker und Vint Cerf (v.l.n.r.) |
Das sogenannte 'Internet' ist in erster Linie eine
technische Möglichkeit, mit vielen Partnern weltweit die
unterschiedlichsten Informationen auszutauschen. Wie das
genau geschieht, was technisch dahinter steckt und was man
alles machen kann, soll nun ein wenig durchleuchtet werden.
|
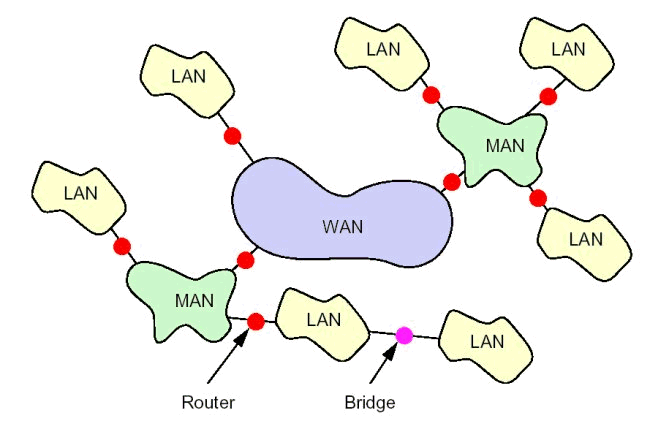
Das Internet ist also ein Verbund von kleineren Netzen - bis hinab zu einem lokalen Netz (LAN), das beispielsweise einer Firma gehört. Alle Rechner eines Netzes können mit allen Rechnern aller anderen am Internet angeschlosssenen Netze kommunizieren. Durch den Anschluß weiterer Netze entsteht ein größeres Netz. Dies hat zu einer weltweiten Vernetzung von Rechnern mit TCP/IP geführt, die unter dem Namen Internet läuft. Es gibt jedoch niemanden, der für das Internet verantwortlich ist, vielmehr tragen die Betreiber der einzelnen Teilnetze Verantwortung für ihr Netz und die Verbindung zu einigen Nachbarn. Jeder erbringt freiwillig auch Leistungen für das gesamte Netz (z. B. Mail-Weiterleitung), die teils kostenlos sind, teils einer gegenseitigen Abrechnung der Leistungen unterliegen. Auf diese Weise kann man von jedem Rechner im Internet zu jedem anderen angeschlossenen Rechner gelangen.
Basis des Netzes bilden die Leitungen der verschiedenen Telekom-Gesellschaften auf der Welt, die ihre Leitungen oder Leitungskapazitäten für die Verbindung der einzelnen Netze vermieten. Aber nicht nur Firmen mieten Leitungen von den TK-Gesellschaften, sondern auch die sogenannten 'Internet-Provider'. Diese Provider bieten dann ihrerseits einen Internet-Zugang für Firmen oder Privatleute an. Später mehr dazu.
Oft wird das reine Transportmedium Internet mit seinen Anwendungen gleichgestellt, z. B. werden vielfach Internet und WWW als identisch betrachtet. Damit wird man diesem Medium aber nicht gerecht, denn es gibt viele Anwendungen, die das Internet nutzen, z. B. Elektronische Post (E-Mail), Dateiübertragung (FTP), Terminalzugriff auf ferne Rechner (Telnet), Diskussionsforen (News), Online-Diskussionen (Chat), Synchronisation der Uhrzeit, Internet-Telefonie und vieles mehr.
Das Internet wurde vor etwa 20 Jahren aus einem dieser Forschungsprojekte des ARPA geboren. Das Ziel dieses experimentellen Projektes war, ein Netzsystem zu entwickeln, das auch partielle Ausfälle verkraften konnte. Kommunikation sollte immer nur zwischen einem Sender und einem Empfänger stattfinden. Das Netz dazwischen wurde als unsicher angesehen. Jegliche Verantwortung für die richtige Datenübertragung wurde den beiden Endpunkten der Kommunikation, Sender und Empfänger, auferlegt. Dabei sollte jeder Rechner auf dem Netz mit jedem anderen kommunizieren können.
Um die geforderte Zuverlässigkeit eines nicht-hierarchischen Netzes zu erreichen, sollte das Netz als ein paketvermitteltes Netz (packet-switched network) gestaltet werden. Bei der Paketvermittlung werden zwei Partner während der Kommunikation nur virtuell miteinander verbunden. Die zu übertragenden Daten werden vom Absender in Stücke variabler oder fester Länge zerlegt und über die virtuelle Verbindung übertragen; vom Empfänger werden diese Stücke nach dem Eintreffen wieder zusammengesetzt. Im Gegensatz dazu werden bei der Leitungsvermittlung (circuit switching) für die Dauer der Datenübertragung die Kommunikationspartner fest miteinander verbunden. Hierzu entstand 1961 die "Paket Theorie" von Leonard Kleinrock. Dieses Verfahren wurde allerdings bei dem ersten Wide Area Network der Welt 1965 noch nicht angewandt. Hier wurden die Rechner TX-2 vom MIT und Q-32 von System Development Corporation in Santa Monica direkt verbunden.
Daraufhin wurde 1967 das erste Designpapier über das ARPANET von Lawrence G. Roberts veröffentlicht und ein Jahr später wird das Konzept der Paket-vermittelnden Netze der ARPA präsentiert.
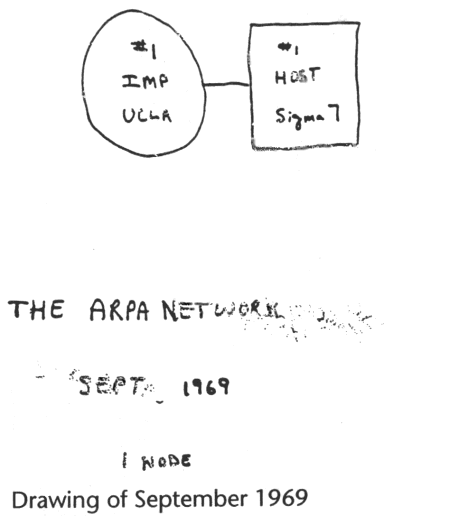 Richtig begonnen hatte alles möglicherweise am 2. September 1969? An diesem Tag wurde
im Labor von Leonard Kleinrock an der Universität von Kalifornien in Los Angeles
(UCLA) der erste Computer an einen Interface Message Processor (IMP) angeschlossen.
"Wir hielten das nicht gerade für einen historischen Moment", erinnerte
sich Kleinrock gegenüber einem AP-Reporter. "Wir hatten nicht einmal eine
Kamera dabei. Aber es war die Geburtsstunde des Internet". Der IMP war ein
mächtiger Klotz von einem Spezialrechner, der nach militärischen Normen
von der Firma Bolt, Beranek & Newmann (BBN) gebaut worden war.
Seine einzige Aufgabe bestand darin, Daten zu senden und zu empfangen, den Empfang
zu überprüfen und das Senden zu wiederholen, wenn etwas nicht geklappt
hatte. Ein IMP sollte einem Computer vorgeschaltet sein und rund um die Uhr laufen
können - eine beträchtliche Anforderung zu einer Zeit, in der Rechner
jede Woche für einige Stunden gewartet werden mußten. Der Bau des IMP durch
BBN erfolgte nach einer Ausschreibung der Forschungsabteilung im Verteidigungsministerium,
die an 140 Firmen geschickt wurde. Damals führende Firmen wie IBM und Control Data
lehnten die Ausschreibung als "nicht realisierbar" ab, nur die kleine BBN wagte
es, die vier IMPs anzubieten. Sie wurden kurzerhand auf Basis eines Honeywell 516 von
Grund auf neu konstruiert.
Richtig begonnen hatte alles möglicherweise am 2. September 1969? An diesem Tag wurde
im Labor von Leonard Kleinrock an der Universität von Kalifornien in Los Angeles
(UCLA) der erste Computer an einen Interface Message Processor (IMP) angeschlossen.
"Wir hielten das nicht gerade für einen historischen Moment", erinnerte
sich Kleinrock gegenüber einem AP-Reporter. "Wir hatten nicht einmal eine
Kamera dabei. Aber es war die Geburtsstunde des Internet". Der IMP war ein
mächtiger Klotz von einem Spezialrechner, der nach militärischen Normen
von der Firma Bolt, Beranek & Newmann (BBN) gebaut worden war.
Seine einzige Aufgabe bestand darin, Daten zu senden und zu empfangen, den Empfang
zu überprüfen und das Senden zu wiederholen, wenn etwas nicht geklappt
hatte. Ein IMP sollte einem Computer vorgeschaltet sein und rund um die Uhr laufen
können - eine beträchtliche Anforderung zu einer Zeit, in der Rechner
jede Woche für einige Stunden gewartet werden mußten. Der Bau des IMP durch
BBN erfolgte nach einer Ausschreibung der Forschungsabteilung im Verteidigungsministerium,
die an 140 Firmen geschickt wurde. Damals führende Firmen wie IBM und Control Data
lehnten die Ausschreibung als "nicht realisierbar" ab, nur die kleine BBN wagte
es, die vier IMPs anzubieten. Sie wurden kurzerhand auf Basis eines Honeywell 516 von
Grund auf neu konstruiert.
 Frank Heart war der leitende Ingenieur beim Bau der IMPs: "Wir haben das Internet
bei BBN überhaupt realisiert. Es ist wie mit Einstein. Der erzählt etwas von
e=mc2 und die Leute vom Alamos Project bauen die Bombe.", erklärte
Heart gegenüber Reuters.
Frank Heart war der leitende Ingenieur beim Bau der IMPs: "Wir haben das Internet
bei BBN überhaupt realisiert. Es ist wie mit Einstein. Der erzählt etwas von
e=mc2 und die Leute vom Alamos Project bauen die Bombe.", erklärte
Heart gegenüber Reuters.
Eigentlich begann die Geschichte damit, dass sich Bob Taylor von der ARPA darüber ärgerte, dass er drei verschiedene Terminals brauchte, um mit drei Universitäten zu kommunizieren, die für die ARPA militärische Grundlagenforschungen betrieben. Dieser Wunsch nach einem -- wie man heute sagen würde -- einheitlichen Kommunikationsprotokoll wurde von J.C.R. Licklider und Bob Taylor aufgegriffen, die 1968 das bahnbrechende Papier {\it The Computer as Communications Device} veröffentlichten. Es sollte aber noch einige Jahre dauern, bis man das Vernetzungsprojekt weit genug gediehen war.
Frank Heart, Ben Barker, Bernie Cosell, Will Crowther, Robertob Kahn, Severo Ornstein und Dave Walden bideten dann das Software-Team für die Programmierung der IMPs. Diese Gruppe bildete später die "`Network Working Group"'. Die Implementierung in Form einer Reihe von Programmen der Netzwerk-Protokolle wurde dann als NCP (Network Control Protocol) veröffentlicht.
An der UCLA (University of Califirnia Los Angeles) arbeiteten Vint Cerf, Steve Crocker und Jon Postel zusammen mit Kleinrock an den Protokollen. am 7. 4. 1969 schickte Crocker ein Memo mit dem Titel "`Request for Comments"' herum. Dies war das erste Dokument zu Internet-Standards (RFC), von denen es heute über 7000 gibt (http://tools.ietf.org/html/rfc1).
Als der erste gelieferte IMP am 2. September 1969 mit einem Computer in Kleinrocks
Büro Daten austauschte, war die Geburt des Internet noch nicht ganz zu Ende.
BBN mußte drei weitere IMPs liefern, die peu à peu in Stanford, Santa Barbara
und Salt Lake City aufgestellt wurden. Zwischen dem Büro von Kleinrock und dem
Stanford Research Institute wurde das erste Ping durch die Leitung geschickt.
Danach entspann sich an jenem 10. Oktober 1969 ein bizarrer Dialog, den viele für
die wahre Geburtsstunde des Internets halten. Kleinrock wollte sich über die beiden
existierenden IMPs mit seinem Computer auf dem Computer in Stanford einloggen; dazu
mußte er den Login-Befehl absetzen. "Wir tippten also das L ein und fragten am
Telefon "Seht ihr das L?" "Wir sehen es", war die Antwort. Wir
tippten das O ein und fragten "Seht ihr das O?" "Ja, wir sehen das O!"
Wir tippten das G ein ... und die Maschine stürzte ab." Doch ein paar Stunden
später war der digitale Schluckauf behoben, der Versuch
wurde wiederholt - und diesmal ging nichts schief: Zwischen Stanford und Los Angeles
lief das erste funktionsfähige Wide-Area-Network (WAN): Das Internet war geboren.
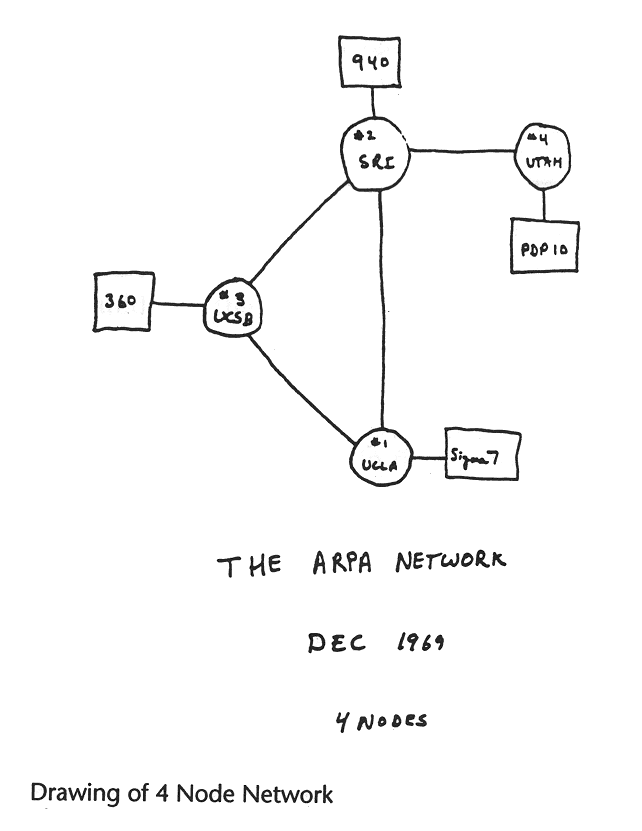
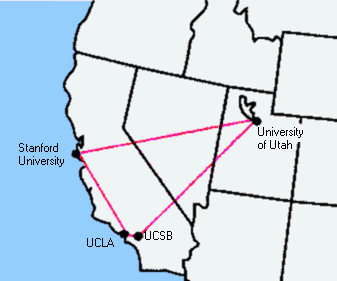 Ende 1969 wurde dann von der University of California Los Angeles (UCLA), der University
of California Santa Barbara (UCSB), dem Stanford Research Institute (SRI) und der
University of Utah ein experimentelles Netz, das ARPA-Net, mit vier Knoten in Betrieb
genommen. Diese vier Universitäten wurden von der ARPA gewählt, da sie
bereits eine große Anzahl von ARPA-Verträgen hatten.
Keine andere technische Entwicklung in diesem Jahrhundert hat eine derartige Erfolgsgeschichte
wie dieses inzwischen erdballumspannende Netzwerk, keine andere einen derart
vielschichtig verzweigten Einfluß auf alle denkbaren Aspekte des gesellschaftlichen
und privaten Lebens.
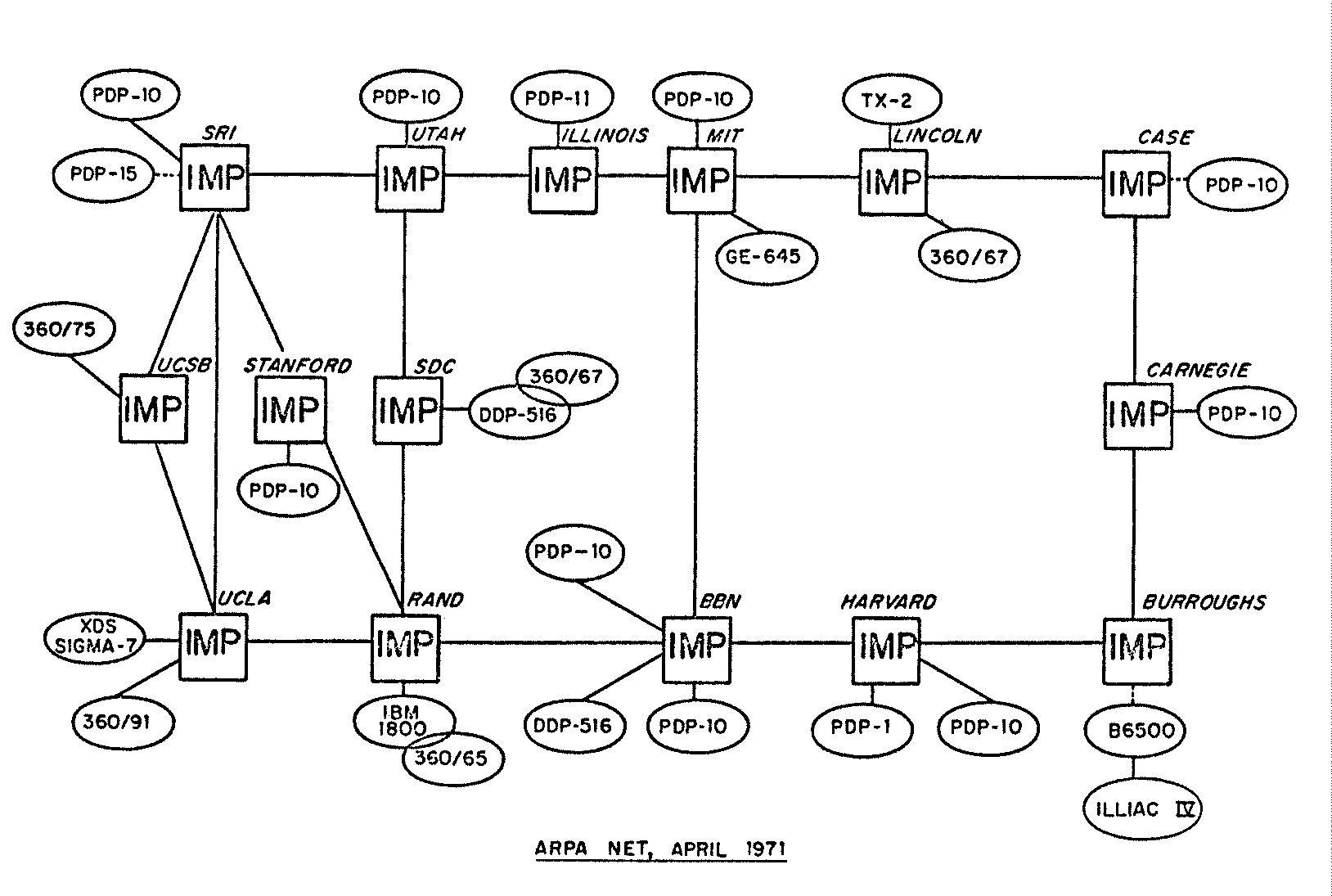
Die Konturen des Internet wurden erst 1971 sichtbar, als das Forschungsprojekt unter dem
Namen ARPAnet mit 15 IMPs erstmals der Öffentlichkeit vorgestellt wurde.
Ende 1969 wurde dann von der University of California Los Angeles (UCLA), der University
of California Santa Barbara (UCSB), dem Stanford Research Institute (SRI) und der
University of Utah ein experimentelles Netz, das ARPA-Net, mit vier Knoten in Betrieb
genommen. Diese vier Universitäten wurden von der ARPA gewählt, da sie
bereits eine große Anzahl von ARPA-Verträgen hatten.
Keine andere technische Entwicklung in diesem Jahrhundert hat eine derartige Erfolgsgeschichte
wie dieses inzwischen erdballumspannende Netzwerk, keine andere einen derart
vielschichtig verzweigten Einfluß auf alle denkbaren Aspekte des gesellschaftlichen
und privaten Lebens.
Die Konturen des Internet wurden erst 1971 sichtbar, als das Forschungsprojekt unter dem
Namen ARPAnet mit 15 IMPs erstmals der Öffentlichkeit vorgestellt wurde.
Erst zu diesem Zeitpunkt hatte das Netz ungefähr die Dimensionen, die in den ersten
Netzskizzen des Informatikers Larry Roberts anno 1966 schon eingezeichnet waren, der die
Idee des dezentral verknüpften Netzwerks entwickelte. Heute ist Roberts einer der
Väter, die am stärksten gegen die Idee vom kriegssicheren Internet polemisieren:
"Es ist ein Gerücht, daß das Internet entwickelt wurde, um einen nuklearen
Krieg auszuhalten. Das ist total falsch. Wir wollten ein effizientes Netz aufbauen."
Erst später sei das Argument eines Atomschlags hinzugekommen - das erwies sich beim
Lockermachen weiterer Forschungsgelder als äußerst nützlich.
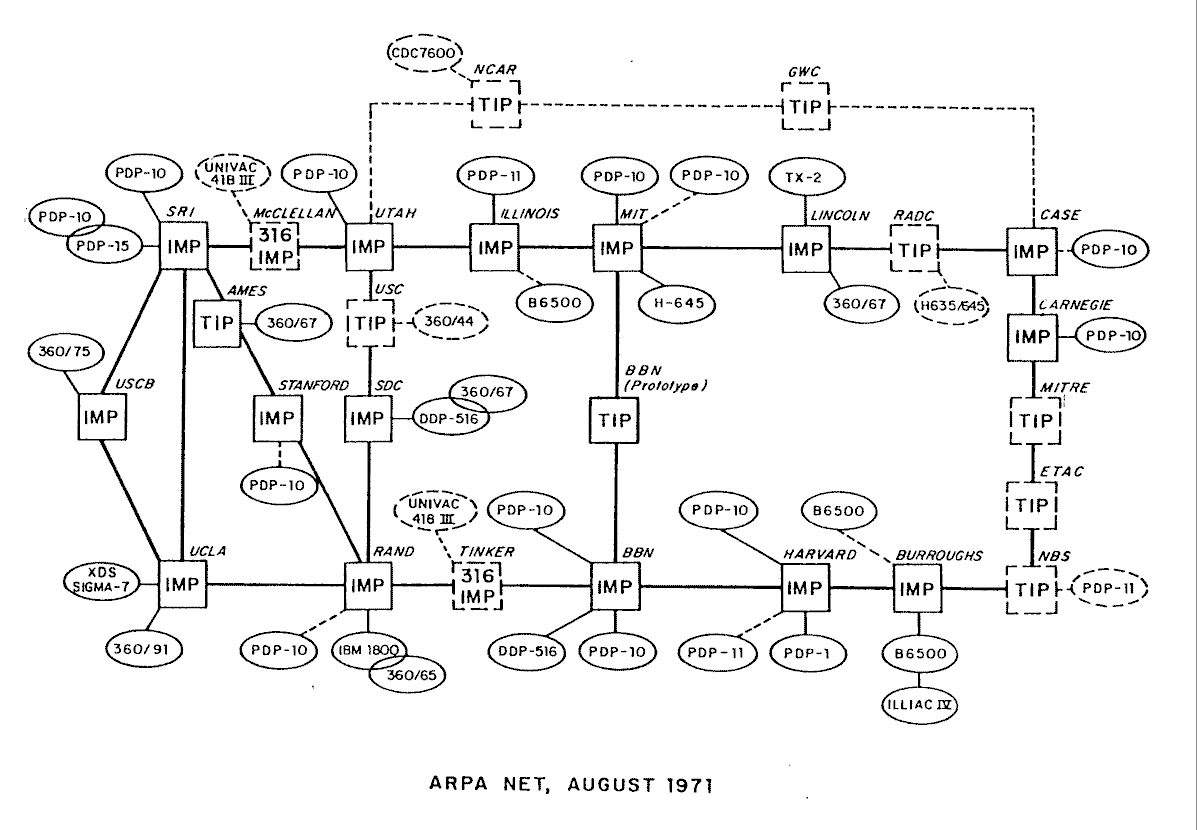
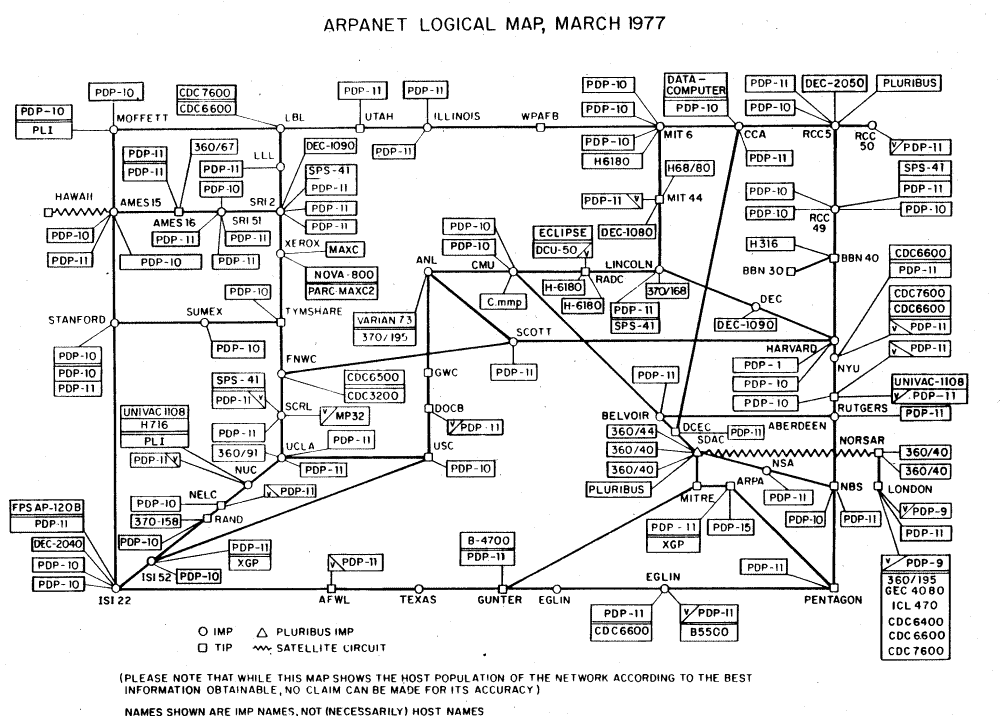
Das ARPA-Netz wuchs rasant und überspannte bald ein großes Gebiet der
Vereinigten Staaten.
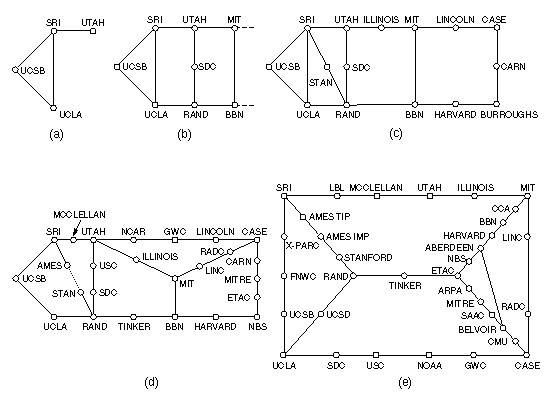
Wachstum des ARPA-Net (Quelle: A. S. Tanenbaum: Computernetworks)
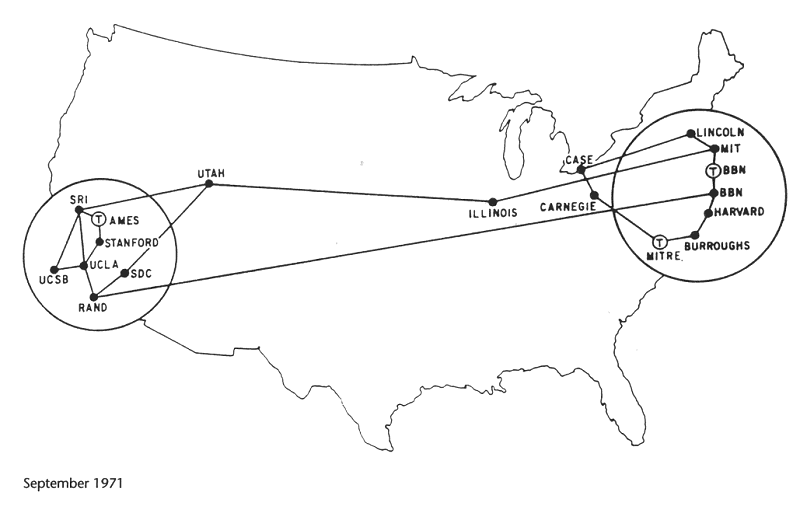
Anfang der Siebziger kam die Idee auf, daß die IMPs von Computern abgelöst werden könnten, die keine Spezialrechner waren. Im Jahre 1972 beschäftigte sich der Xerox-Informatiker Bob Metcalfe damit, das hausinterne Netzwerk MAXC an das ARPAnet zu hängen. Dabei erfand er eine Übertragungstechnik, die er Ethernet nannte. Zeitgleich wurde der erste "Request for Comment" (RFC) veröffentlicht. Der Inhalt ist Host Software. Im Laufe der nächsten Jahre wurden immer mehr Rechner an das ARPANET angeschlossen, 1973 die Universität "Collage of London". Dies war die erste internationale Anbindung an das ARPANET.
Die Erfindung erregte das Interesse von Bob Kahn und Vint Cerf, die 1974 den ersten Vorschlag für ein einheitliches Rechnerprotokoll machten: "A Protocol for Paket Network Intercommunication". Dieses Papier beschreibt im Detail das Design des "Transmission Control Protocols" (TCP). Dieses Protokoll wurde TCP/IP genannt und am 1. Januar 1983 in den Rang eines offiziellen Standards erhoben: Viele Netzwerker halten denn auch dieses Datum für den offiziellen Geburtstag des Internet.
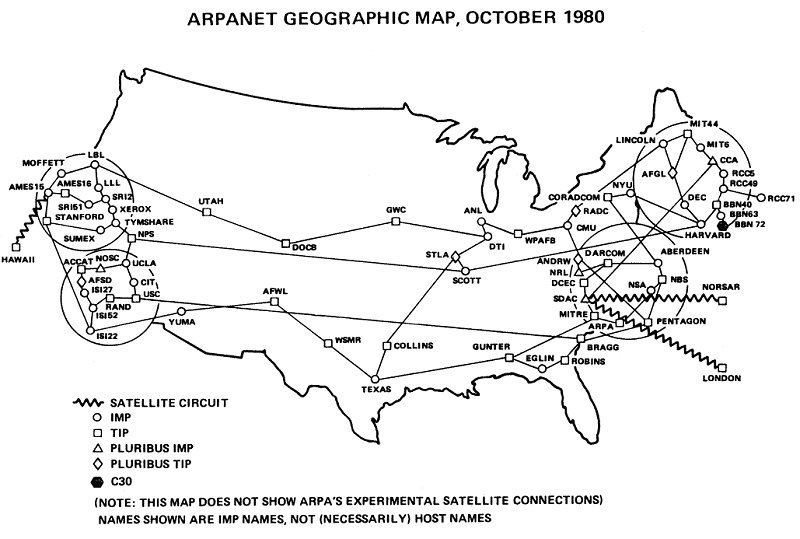
Selbst heute, 30 Jahre später, ist die Bedeutung der kulturtechnischen Leistung "Internet" erst in Umrissen erahnbar. Der weitere Ausbau verlief langsam und gemächlich, auch nach mehr als 10 Jahren arbeiteten gerade mal rund 200 Systeme (Hosts) im ARPA-Net zusammen. Schon zu diesem Zeitpunkt war das ARPA-Net kein Netzwerk wie jedes andere auch, sondern definierte eine Kommunikationsstruktur. jeder Host im ARPA-Net konnte ein Zentralcomputer in einem lokalen Netzwerk sein, so daß das ARPA-Net ein Netzwerk aus Netzwerken bildete eben ein "Internet". Dieses Internet wucherte unaufhaltsam weiter und allmählich beschleunigte sich das Wachstum und nahm einen exponentiellen Verlauf. Im Oktober 1984 zählte man rund 1000 Hosts, 1987 waren es etwa 10000 und 1989, zwei Jahre später, über 100 000.
Mit der Zeit und dem Wachstum des ARPA-Net wurde klar, daß die bis dahin gewählten Protokolle nicht mehr für den Betrieb eines größeren Netzes, das auch mehrere (Teil)Netze miteinander verband, geeignet war. Aus diesem Grund wurden schließlich weitere Forschungsarbeiten initiiert, die 1974 zur Entwicklung der TCP/IP-Protokolle führten. TCP/IP wurde mit mit der Zielsetzung entwickelt, mehrere verschiedenartige Netze zur Datenübertragung miteinander zu verbinden. Da etwa zur gleichen Zeit an der University of California an einem neuen Betriebssystem mit Namen UNIX entwickelt wurde, beauftragte die (D)ARPA die Firma Bolt, Beranek & Newman (BBN) und die University of California at Berkeley zur Integration von TCP/IP in UNIX. Dies bildete auch den Grundstein des Erfolges von TCP/IP in der UNIX-Welt. Ein weiterer Meilenstein beim Aufbau des Internet war die Gründung des NSFNET der National Science Foundation (NSF) Ende der achtziger Jahre, die damit fünf neu gegründete Super Computer Centers den amerikanischen Hochschulen zugänglich machte. Dies war ein wichtiger Schritt, da bis zu diesem Zeitpunkt Super Computer nur der militärischen Forschung und einigen wenigen Anwendern sehr großer Firmen zur Verfügung standen.
Parallel zu den Entwicklungen im ARPAnet und NSFNET arbeitete die ISO (International Standards Organisation) seit den achtziger Jahren an der Standardisierung der Rechner-Kommunikation. Die Arbeiten mündeten in der Definition des ISO/OSI Referenzmodells. Die Entwicklung entsprechender OSI-Protokolle und -Anwendungen gestaltete sich aber als ein äußerst zäher Prozeß, der bis heute nicht als abgeschlossen anzusehen ist. Hersteller und Anwender konnten darauf natürlich nicht warten und so wurde die Internet Protokoll-Familie TCP/IP im Lauf der Zeit in immer mehr Betriebssystemen implementiert. TCP/IP entwickelte sich so unabhängig von den offiziellen Standardisierungsbestrebungen zum Quasi-Standard.
Im Jahr 1983 wurde das ARPA-Net schließlich von der Defence Communications Agency (DCA), welche die Verwaltung des ARPA-Net von der (D)ARPA übernahm, aufgeteilt. Der militärische Teil des ARPA-Net, wurde in ein separates Teilnetz, das MILNET, abgetrennt, das durch streng kontrollierte Gateways vom Rest des ARPA-Net - dem Forschungsteil - separiert wurde. Nachdem TCP/IP das einzige offizielle Protokoll des ARPA-Net wurde, nahm die Zahl der angeschlossenen Netze und Hosts rapide zu. Das ARPA-Net wurde von Entwicklungen, die es selber hervorgebracht hatte, überrannt. Das ARPA-Net in seiner ursprünglichen Form existiert heute nicht mehr, das MILNET ist aber noch in Betrieb.
Das Jahr 1989 markiert einen Wendepunkt. Zum einen wurde zum 20. Geburtstag des ARPA-Net seine Auflösung beschlossen - es ging in das 1986 gegründete Netzwerk der National Science Foundation (NSF) über - zum anderen schrieb Tim Berners-Lee am Genfer Kernforschungszentrum CERN ein Diskussionspapier mit dem Titel "Information Management: A Proposal", mit dem er den Kommunikationsprozeß am CERN verbessern wollte. Aus diesem Vorschlag entwickelt sich in den nächsten Monaten das "World Wide Web" (WWW). Das System leistete erheblich mehr als geplant - es entpuppte sich als als das einfachste, effizienteste und flexibelste Verfahren, um beliebige Informationen im Internet zu publizieren. Die Einführung des WWW sorgte für den bis dato kräftigsten Wachstumsschub des Internet. Dauerte es von 1969 bis 1989 immerhin 20 Jahre, bis mehr als 100 000 Hosts zusammengeschlossen waren, so waren es 1990 bereits über 300000 und 1992 wurde die Millionengrenze überschritten. Der Durchbruch und die selbst erfahrene Netzveteranen überraschende explosionsartige Verbreitung des Internet und des WWW setzte 1993 ein, als Marc Andreessen sein Programm "MosaiC herausbrachte, mit dem auch der unizeschulte Computerlaie auf früher kryptische Kommandos und ein erhebliches Spezialwissen nötig war, genügte nun ein einfacher Mausklick. Aus Mosaic wurde ein Jahr später Netscape und - "the rest is history".
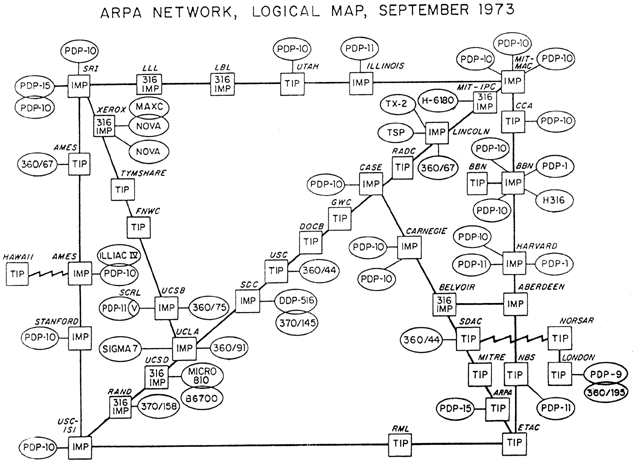
Keiner der ARPAnet-Entwickler war sich bewusst, mit seiner Arbeit ein wichtiges Stück Technikgeschichte zu schreiben. Alle waren sie damit befasst, knifflige technische oder programmiertechnische Probleme zu lösen. Mitunter waren es sogar persönliche Probleme: Len Kleinrock schilderte seine Version des Aufkommens von E-Mail als erste illegale Nutzung der neuen Technik. Kleinrock entdeckte im September 1973, daß er seinen Rasierer in England vergessen hatte. Dort fand eine Konferenz über das ARPAnet statt, die er vorzeitig verlassen mußte. Kleinrock setzte sich an ein Terminal und stellte eine Verbindung zu einem Konferenzteilnehmer her, der gerade online war. Zwei Tage später war der Rasierer bei ihm. Und schon 1972 führte Ray Tomlinson den Klammeraffen @ als Teil der User-Adressen eines Programms ein, mit dem sich Nachrichten verschicken ließen - einfach deswegen, weil er das Zeichen auf seinem 33-Tasten-Keyboard sonst am wenigsten benötigte.
Im Jahre 1998 lud die Internet Society die Protagonisten der ersten Stunde zu einem Panel mit dem hübschen Titel Unexpected Outcomes of Technology, Perspectives on the Development of the Internet. Alle Beteiligten bekundeten in fröhlicher Einigkeit, daß sie die Idee eines weltumspannenden Kommunikationsnetzes für alle Erdenbürger bis Anfang der 90er für eine Idee von Verrückten gehalten hätten. "Man muß es einfach so sehen: Wir waren von unserem Netzwerk überzeugt. Wir haben unverdrossen nach Lösungen gesucht und waren damit erfolgreich. Außenstehende mögen uns für verrückt gehalten haben. Wir fanden eher, das wir positiv plemplem waren", erklärte Jon Postel in einem seiner letzten Interviews. Er muß es wissen: Ist er doch auch einer der Väter des Internet und war bis zu seinem Tod lange Jahre verantwortlich für die RFCs (Request for Comments), in denen die Internet-Standards festgeschrieben sind.
Die Genialität, die man den Entwicklern des Internet aus heutiger Sicht zuschreibt, wird von den Technikern eher spöttisch kommentiert. Ken Klingenstein, der für die Simplizität des von ihm entwickelten SNMP (Simple Network Management Protocol) geehrt wurde, klärte den genialen Wurf im Interview auf: "Mir kam die Idee zu SNMP in einer Bar auf dem Weg nach Hause. Ich nahm die Serviette des Drinks und schrieb alle Befehle auf. Es mußten einfach wenige sein, weil die Serviette so klein war."
Ähnlich war es um TCP/IP bestellt: Vint Cerf brachte eine der ersten Skizzen zum Kommunikationsprotokoll der Internet-Welt auf der Rückseite der Bedienungsanleitung seines Hörgeräts zu Papier. In einer Forschungsgruppe befaßt sich der PR-erfahrene Cerf inzwischen publikumswirksam mit dem transgalaktischen Protokoll: dem technischen Problem, wie die langen Laufzeiten von Datenpaketen bei der Kommunikation zwischen Mars und Erde optimal überbrückt werden können.
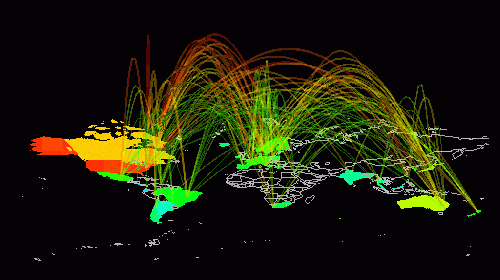
In den 70er Jahren wurden auch die ersten Dienste für das ARPANET entwickelt. Im Jahr 1971 entwickelte von Ray Tomlinson das erste Programm für den E-Mail-Dienst. Es basierte auf einem rechnerinternen Mail-Programm und einer experimentellen FTP-Version. Ray ist auch verantwortlich für die Verwendung des "@". Erst sechs Jahre später wurde E-Mail erstmals im RFC 733 spezifiziert. 1979 kam Kevin MacKenzie auf die Idee, Emotionen im Text auszudrücken. Hierzu erfand er die ersten Smilies :-)
Ein Jahr nach dem ersten E-Mail-Programm wurde Telnet im RFC 318 spezifiziert. Wieder ein Jahre später gab es dann die Standardisierung des "File Transfer Protocol" im RFC 454. Etwa gleichzeitig wurde der RFC 741 geschrieben, in dem die Spezifikation des "Network Voice Protocol" stand. Auf der Basis dieser Dienste und dem Versuch des ARPANETs gibt BBN 1974 "Telenet" frei, eine kommerzielle Version des ARPANETs. Es ist das erste kommerzielle, paketorientierte Netz.
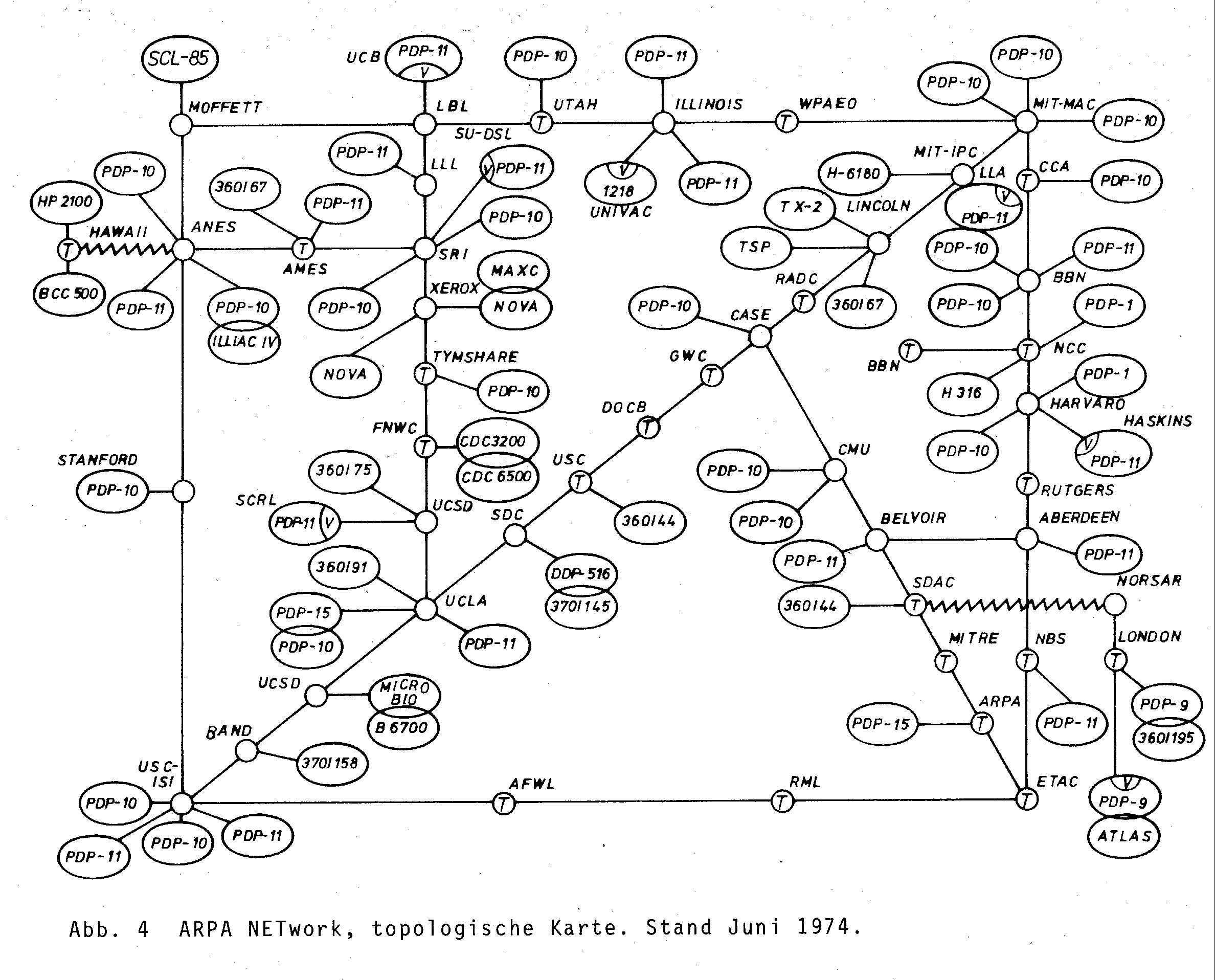
1982 entsteht durch die Implementierung der TCP/IP-Protokollfamilie und deren Einsatz im ARPANET der Begriff "Internet". Ein Jahr später kommen Workstations mit Berkley UNIX 4.2 (BSD) auf den Markt, dem ersten UNIX mit eingebauter TCP/IP-Unterstützung. Im darauffolgenden Jahr wird das Name-Server-Konzept entworfen und 1984 eingeführt. Die erste registrierte Domain war 1985 symbolics.com. Zu dieser Zeit gab es schon über 1000 Hosts.
1986 wurde das Nation Science Foundation Network (NSFNET)
gegründet. Es hatte eine Backbone-Geschwindigkeit von 56 KBit/s und
verband vorwiegend Universitäten und dazugehörige Institutionen.
Dieses Netz wurde in den darauffolgenden Jahren ständig erweitert.
1988 wird das Backbone auf T1-Leitung (1,544 MBit/s) erweitert und
1989 wird auch Deutschland an das NSFNET angeschlossen.
Durch den Erfolg des NSFNET stieg auch die Zahl der Hosts im
Internet auf 1987 über 10000. Zwei Jahre später waren es dann
schon über 100.000.
Durch das starke Wachstum wurde 1991 das Backbone des NSFNET auf T3
(44,736 Mb/s) erweitert. Die Kapazität überschreitet erstmals 1
Billionen Bytes bzw. 10 Milliarden Pakete pro Monat. Auch die Anzahl
der Hosts übersteigt 1992 erstmals die 1.000.000 Marke.
Auch 1991 veröffentlichte CERN das von Tim Berners-Lee entwickelte World-Wide Web (WWW).
Der spätere Gründer von Netscape, Marc Andreesen, war der Entwickler des 1993
veröffentlichten Browsers namens "Mosaic".
Heute werden "World Wide Web" und "Internet" vielfach synonym
gebraucht und die Größe des Internets verdoppelte sich alle 12 bis 18 Monate.
Die neuesten Schätzungen gehen von über 43 Millionen angeschlossenen Systemen
aus, die Anzahl der Menschen, die Zugriff auf Informationen im Internet haben, wird auf
über 160 Millionen geschätzt, davon sind etwa 36 Millionen in Europa. In
Deutschland ermittelte 1999 die GfK 8,4 Millionen.
Allerdings sind derartige Zahlen und Erhebungen nur mit großer Vorsicht zu
genießen. Schon die technische Messung der Hostzahlen ist alles andere als
trivial und in hohem Maße interpretationsbedürftig. Nur eines ist wirklich
sicher: Das Internet und das WWW breiten sich seit Jahren mit schwindelerregender
Geschwindigkeit aus.
Wer mehr über die Geschichte des Internets erfahren möchte, sollte Hobbes' Internet Timeline, lesen. Dieses Dokument wurde 1998 als RFC 2235 veröffentlicht.
Zum Wachstum des Internet in Deutschland siehe:
http://www.nic.de/Netcount/netStatHosts.html
Weitere Quellen zur Geschichte des Internet:
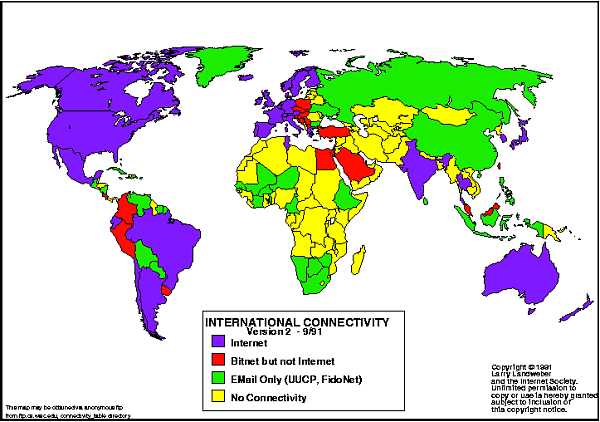
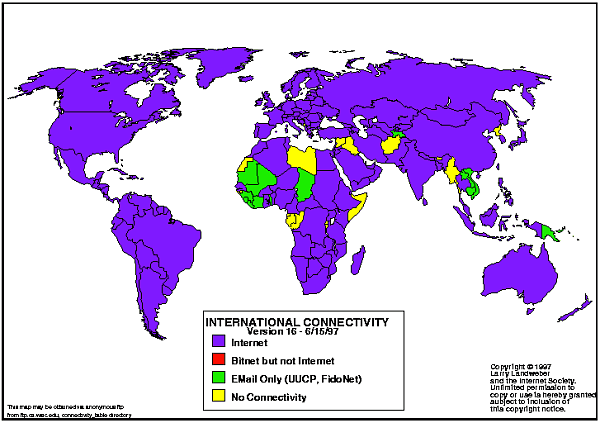
Weiter Karten zur Ausdehnung des ARPA-Netzes:
Für Kaffeetrinker ist auch noch der RFC 2324 (erschienen 1. April 1998) interessant. Er handelt vom Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0).
Wie schwer es für frühere Generationen war, ins Internet zu kommen, dokumentieren die folgenden Videos aus der Sendereihe "Computer Chronicles", die bei Youtobe zu finden sind:
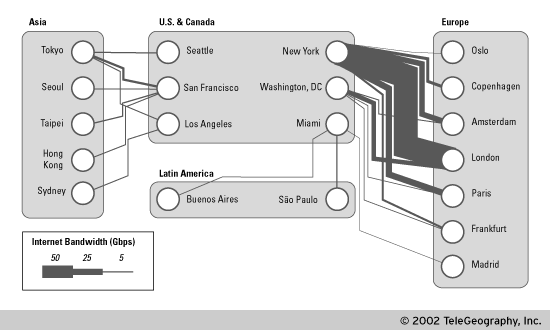
Die Frage, wer nun zum Internet gehört und wer nicht, ist schwer zu beantworten. Bis vor einigen Jahren war die Antwort, daß jedes Gerät, welches die TCP/IP-Protokolle beherrschte und Verbindung zum 'Rest der Welt' hatte, zum Internet zu zählen war. Inzwischen wurden in anderen großen Netzwerken(Bitnet, DECnet, ...) Methoden entwickelt, um Daten mit dem Internet über sogenannte Gateways auszutauschen. Diese Techniken wurden inzwischen derart verfeinert, daß Übergänge zwischen diesen Netzwelten und dem Internet für den Benutzer teilweise vollkommen transparent vonstatten gehen. Offiziell ist nicht geklärt, ob diese Netze nun zum Internet gehören oder nicht. Ein Rechner wird allgemein dann als zum Internet gehörend angesehen, wenn:
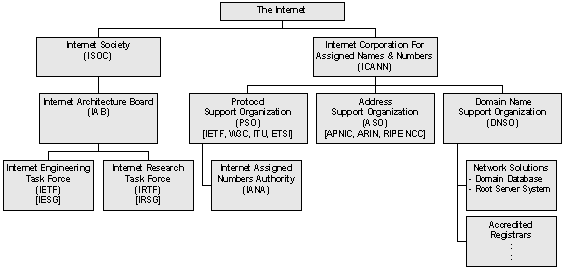
Die ISOC, die Internet Society, ist die Dachorganisation untergeordneter netzbezogener Organisationen. Sie umfasst mehrere Hundert Organisationen und eine lange Reihe von Privatpersonen und ist aufgeteilt in Unterorganisationen (Chapters), z. B. nach Themen oder Regionen. Sie richtet die alljährliche Internetkonferenz aus und kümmert sich beispielsweise auch darum, daß der Begriff 'Internet' ein frei verfügbarer Begriff wird und nicht als Wortmarke oder sonst wie geschützter Begriff in das Eigentum von Privatpersonen übergeht. Die ISOC befasst sich mit:
Das IAB (Internet Architecture Board) ist das höchste Gremium im Internet. Es segnet Entscheidungen über Standards und Adressvergabe ab und läßt diese Entscheidungen bekanntgeben. Es dokumentiert die gültigen Protokolle des Internet, ernennt die Mitglieder der IESG (Internet Engineering Steering Group) und setzt die Vorsitze der IANA (Internet Assigned Numbers Authority) ein. Außerdem leitet es das RFC-System, mit dem die Fortschreibung der Protokolle und Richtlinien des Internet realisiert wird. Alle Entscheidungen, die das IAB trifft, werden in den sogenannten Request for Comments (RFC) veröffentlicht. Das IAB umfasst zwei spezialisierte Untergruppen, die Internet Engineering Task Force (IETF) und die Internet Research Task Force(IRTF). Diese beiden Gremien sind für die Weiterentwicklung und Definition der kurz- und mittelfristigen Internet-Protokolle und -Architekturen für die Bereiche Applikationen, Host- und Benutzerservice, Internet-Service, Routing, Adressierung, Netzwerkmanagement, Operations, Security und OSI-Integration verantwortlich. Sie erarbeiten die für das IAB zum Entscheid notwendigen Grundlagen. Das IAB ist eine technische Beratungsgruppe der ISOC. Seine Verantwortungen schliessen ein:
Die IANA (Internet Assigned Numbers Authority), deren Vorstand J. Postel war, ist zuständig für alle eindeutigen Ressourcen im Netz, also Netzadresse, Domainnamen und Portnummern.
Technische und betriebliche Probleme werden zuvor in der IETF (Internet
Engineering Task Force) behandelt, eine offene Vereinigung von Administratoren,
Technikern, Forschern und Softwareproduzenten, die die Weiterentwicklung von
Protokollen, Sicherheitsrichtlinien, Routing etc. des Internet betreibt. Ihre Treffen
sind für jedermann offen. Sie fördert auch den Technologie- und Wissenstransfer
zwischen der IRTF (Internet Research Task Force) und leistet somit Vermittlung
und Koordination zwischen Forschung und Praxis (wobei auch der zeitliche Rahmen eine
Rolle spielt: während die IETF kurz- und mittelfristig die Standards definiert, ist
die Aufgabe der IRTF die langfristige Kursbestimmung und Forschung).
Die Standards werden dann in sogenannten RFCs (Request for Comments) niedergelegt.
Das ISC (Internet Software Consortium) ist zuständig für die
Referenzimplementierung der zentralen Internetprotokolle.
Standards von Protokollen oder sonstigen netzrelevanten Vereinbarungen können an die
zuständigen Gruppen der IETF, ISOC oder inzwischen auch der ICANN eingereicht werden,
welche dann die Probleme je nach betreffendem Fachgebiet in lokale Arbeitsgruppen
(Working Groups, WGs) weitergeben. Die anstehende Standardisierung wird als Internet
Draft bezeichnet und hat vorerst überhaupt keine Geltungsmacht. Die Erörterung des Themas
und die Einigung auf die besten Möglichkeiten finden über Mailinglisten statt. Treffen
werden jährlich mehrmals organisiert, in denen dann auf Konsensebene die Ergebnisse
zusammengefasst werden und in die RFC's eingehen. Trotz der inzwischen häufigen
Zugehörigkeit der Mitglieder zu Industrieunternehmen wiegt technische Angemessenheit,
Kompetenz und Engagement mehr wiegt als das Vertreten von Konzerninteressen. Ebenso ist
eine starke 'Dienstaltershierarchie' feststellbar. Leute wie Cerf oder Kleinrock, die als
'Väter' des Internet gelten, genießen in Kreisen von Netztechnikern hohes Ansehen und
werden eher wahrgenommen. Deutlich erkennbar ist auch die allgegenwärtige Verehrung des
inzwischen verstorbenen Jon Postel, der die längste Zeit das RFC-System administriert hat.
Die IETF wird in folgende acht funktionale Gebiete eingeteilt:
Die Internet Research Steering Group (IRSG) "steuert" die Arbeiten der IRTF. Die Mitgliedschaft der IRSG beinhaltet den Vorsitzenden des IRTF, die Vorsitzenden der verschiedenen Forschungsgruppen und möglicherweise einzelne weitere Personen der Forschungsgemeinschaft (members at large).
Ziel der Internet Research Task Force (IRTF) ist die Förderung der Forschung im Hinblick auf das Wachstum und die Zukunft des Internets. Dazu werden kleine langfristige Forschungsgruppen gebildet, die auf gezielten Forschungsgebieten, wie Internet Protokolle, Applikationen, Architektur und Technologie arbeiten. Folgende Forschungsgruppen sind derzeit gebildet:
Die Internet Assigned Numbers Authority (IANA) ist die zentrale
Koordinationsstelle für die Zuweisung von eindeutigen Parameterwerten
für Internet-Protokolle. Das heisst, sie ist für die Vergabe
von IP-Adressen und Domain-Namen verantwortlich.
In der Vergangenheit, wurden die Aktivitäten der IANA durch die
Regierung der USA unterstützt. Dies ist nun nicht mehr möglich
oder angemessen. Die USA haben nicht vor, in der Zukunft weiter (Geld-)Mittel
bereitzustellen und so muss sich die IANA auf ihre Organisationen verlassen
können. Das Internet ist von einem Forschungsnetz für Hochschulen
zu einem multimedialen Netz für die Allgemeinheit geworden, das von
Leuten über alle Welt benutzt wird. Diese Veränderung in Funktion
und in der Anwenderbasis fordert nach einer neuen standfesten Institution mit
einer breiten Gemeinschaftsvertretung aller Benutzer.
Dieses neue IANA ist zur Zeit gerade im Begriff zu entstehen. Das alte
IANA stand noch unter der Leitung von Dr. Jon Postel vom Information Sciences
Institute der University of Southern California. Das neue IANA heisst
Internet Corporation for Assigned Names and Numbers (ICANN) und wird als
Non-Profit-Organisation von einem internationalen Verwaltungsrat bestehend aus
Repräsentanten einer Wählerschaft und weiteren internationalen
Repräsentanten geführt.
Mit der ICANN (Internet Corporation for Assigned Names and Numbers), wurde eine Organisation neuen Typs geschaffen, die den Anspruch hat, supranational und demokratisch zu funktionieren und die Schnittbereiche zwischen Internet und nationalen und internationalen Rechtsräumen zu regulieren. Während der populärste Gegenstand der Steuerung der IETF IP6 ist, schneidet sich die bekannteste Aufgabe der ICANN, nämlich die Vergabe von Domänennamen (insbesondere Top Level Domains), mit bestehenden Gesetzen wie Marken- und Urheberrecht. Diese Situation ist als solche nicht unvermeidlich, der Diskurs dreht sich im Allgemeinen aber nicht mehr um das 'ob', sondern das 'wie' der Umsetzung des Marken- und Urheberrechts im Internet.
Das W3C (World Wide Web Consortium) kümmert sich um die verbindlichen Standards
des HTTP (HyperText Transfer Protocol), über welches Webseiten transferiert werden,
und um die Weiterentwicklung des HTML-Standards. Im Unterschied zu staatlich unterstützten
Gremien wie der ISO haben sich die angeführten Gremien selbst gebildet und sind nicht
staatlich legitimiert.
Das Konsortium bietet Informationen über das WWW und Standards
für Entwickler und Benutzer, Referenzcode und -Implementationen, um
die Standards zu umzusetzen und zu befördern, verschiedene Prototypen
und Beispiel-Anwendungen, um den Gebrauch der neuen Technologie
zu demonstrieren.
Das Konsortium wird geführt durch Tim Berners-Lee, Direktor und
Erfinder des World Wide Web, und Jean-François Abramatic, als Chairman.
W3C wird durch Mitgliedsorganisationen unterstützt und ist
firmenneutral. Es erarbeitet mit der Web-Gemeinschaft gemeinsam
Produktespezifikationen und Referenzsoftware, welche weltweit
frei zur Verfügung gestellt wird.
Als ausführende Institutionen arbeiten sogenannte NICs (Network
Information Centers) und NOCs (Network Operation Centers), welche auf
weltweiter, kontinentaler, nationaler und regionaler Ebene existieren. Die
Aufgabe des NIC ist die Vergabe und Koordination von eindeutigen Adressen und
Namen im Internet. z. B. vergibt das zentrale InterNIC in USA ganze Adressbereiche
an das europäische NIC (das RIPE-NCC (Reseaux IP Europeens - Network Coordination
Center), welches seinerseits die deutsche Organisation, das DE-NIC, mit einem Teil
dieses Adressbereiches beglückt. Das DE-NIC hat dann die Möglichkeit,
eigenständig aus diesem Bereich Adressen zu vergeben, z. B. an einen Provider,
der die Adressen an seine Endbenutzer weiterverteilt.
Die NOCs kümmern sich um den Betrieb des Netzes. Dazu gehören die Konfiguration
der Netzkomponenten, die Behebung von Netzfehlern und die Beratung und Koordination der
Netzteilnehmer.
Mitglied der IETF oder der ISOC kann prinzipiell jeder werden, Zugangsschwellen sind weniger die Zugehörigkeit zu Wirtschafts- oder Regierungsinstitutionen als vielmehr Expertenstatus und Engagement.

Die Übertragung erfolgt fast so, wie Pakete von der Post transportiert werden. Wenn Informationsübertragung ansteht, wird ein Paket gepackt und mit einer Adresse versehen. Sodann wird dieses Informationspaket dem Netz überlassen, indem man es am Schalter abgibt. Das örtliche Postamt entscheidet dann aufgrund der Empfängeradresse, ob das Paket direkt an den Empfänger (wenn dieser also im Versorgungsbereich dieses Postamtes wohnt) auszuliefern ist, oder durch Einschalten von mehr oder weniger Zwischenstationen. In der Regel findet das Paket dann ein Postamt, das die Auslieferung an den Empfänger aufgrund der Adresse vornehmen kann. Schwierigkeiten bei der Auslieferung können dem Absender aufgrund der Absendeadresse mitgeteilt werden. Die einzelnen Teilnetze des Internet sind durch Geräte verbunden, die 'Router' genannt werden. Diese übernehmen die Funktion von Vermittlungsstellen und der ausliefernden 'Postämter'. Das folgende Beispiel-'Internet' verbindet vier Netze miteinander:
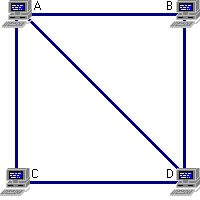
In den Adressen stecken Anteile, die das Empfänger-Postamt
charakterisieren (Postleitzahl, Ort) und Anteile, die den
Empfänger im Bereich dieses Postamtes festlegen. Diese Art
der Informationsübertragung hat große Parallelen zur
paketvermittelten Kommunikation im Internet.
Die Adressen, die im Internet verwendet werden,
bestehen aus einer 32 Bit langen Zahl. Damit sich die Zahl leichter
darstellen läßt, unterteilt man sie in 4 Bytes (zu je 8 Bit).
Diese Bytes werden dezimal notiert und durch Punkte getrennt (a.b.c.d).
Zum Beispiel:
141.84.101.2
129.187.10.25
Bei dieser Adresse werden zwei Teile unterscheiden, die Netzwerkadresse und
die Rechneradresse, wobei unterschiedlich viele Bytes für beide Adressen
verwendet werden:
| Netz-Klasse | Netzwerkadresse | Host-Adresse | Bereich binär |
|---|---|---|---|
| A | a b.c.d | 1 - 126 | 01xxxxxx |
| B | a.b c.d | 128 - 191 | 10xxxxxx |
| C | a.b.c d | 192 - 223 | 11xxxxxx |
Die Netzadressen von 224.x.x.x bis 254.x.x.x werden für besondere Zwecke verwendet, z. B. 224.x.x.x für Multicast-Anwendungen.
Grundsätzlich gilt:
Jedes Datenpaket steckt quasi in einem 'Umschlag', der
Absende- und Empfängeradressen enthält. Diese Adressen-Information
wird den Nutzdaten vorangestellt, so daß jede
Komponente im Netz, die das Protokoll TCP/IP beherrscht,
aus dem Anfang des Datenpaketes herauslesen kann, woher das
Paket kommt und wohin es soll. Komponenten, die das können
und die zusätzlich die Möglichkeit haben, Datenpakete auf
verschiedenen Wegen weiterzuschicken, sind die obengenannten Router.
Diese nehmen von den Adressen immer erst die
Netzanteile und entscheiden, ob das Netz direkt
angeschlossen ist oder, falls nicht, an welchen nächsten
Router es zu schicken ist.
Ein weiterer großer Vorteil des IP-Protokolls ist seine
Unabhängigkeit vom tatsächlichen Datentransport. Die
Datenpakete können über ein Ethernet, eine serielle
Modemverbindung oder ein anderes Medium laufen. Für serielle
Verbindungen, die häufig für die letzten Kilometer bis zum
heimischen Rechner verwendet werden, gibt es spezielle IP-Protokolle.
Angefangen hat es mit SLIP (Serial Line Internet Protocol), das heute
weitgehend durch PPP (Point to Point Protocol) abgelöst ist.
Das Internet Protocol IP ist also hauptverantwortlich
dafür, daß Daten den richtigen Weg im Internet finden. Wenn
ein Datenpaket nur korrekt in einen 'IP-Briefumschlag'
gesteckt wird, kann es beruhigt dem Netz übergeben werden.
Was aber ist, wenn mal ein Datenpaket verloren geht? Wie
versendet man überhaupt mehr Daten als die maximale
Paketgröße von 1500 Bytes? Was passiert, wenn auf einer
größeren Maschine, die mehrere Benutzer gleichzeitig haben
kann, Datenpakete für verschiedene Benutzer eintreffen?
Hierfür gibt es die Transportprotokolle TCP und UDP.
In Kapitel 6 wird noch genauer auf die Protokolle und den Datentransport eingegangen.
Die Namen im DNS sind hierarchisch aufgebaut. Das gesamte Internet ist in Domains aufgeteilt, welche wieder durch Subdomains strukturiert werden. In den Subdomains setzt sich die Strukturierung fort. Diese Hierarchie spiegelt sich im Namen wieder. Die entsprechenden Domains werden durch Punkt getrennt. Beispiele:
| Generische TLDs | |
|---|---|
| com | Kommerzielle Organisationen |
| edu | (education) Schulen und Hochschulen |
| gov | (government) Regierungsinstitutionen |
| mil | militärische Einrichtungen |
| net | Netzwerk betreffende Organisationen |
| org | Nichtkommerzielle Organisationen |
| int | Internationale Organisationen |
arpa | und das alte ARPA-Net bzw. Rückwärts-Auflösung von Adressen |
Ende 2000 sind neue TLDs von der ICANN genehmigt worden:
| Generische TLDs | |
|---|---|
| pro | Ärzte, Rechtsanwälte und andere Freiberufler |
| biz | Business (frei für alle) |
| info | Informationsanbieter (frei für alle) |
| name | Private Homepages (frei für alle, aber nur dreistufige Domains der Form <Vorname>.<Name>.name) |
| Generische, geförderte TLDs | |
| aero | Luftfahrtindustrie |
| coop | Firmen-Kooperationen |
| museum | Museen |
| jobs | Stellenangebote |
| travel | Reisen |
Unterhalb der Top-Level Domain treten dann Domains wie
'fh-muenchen' auf, die sich im Rahmen ihrer Organisationen
auf diesen Namen geeinigt haben müssen, wie auch über die
weitere Strukturierung des Namensraumes, etwa daß
Fachbereiche einen Subdomain-Namen bilden (z. B. e-technik).
Diese werden wieder strukturiert durch die Namen
der einzelnen Lehrstühle und Institute. Als letztes Glied
wird der einzelne Rechner mit seinem Hostnamen
spezifiziert.
Für die Aufnahme einer Verbindung zwischen zwei Rechnern
muß in jedem Fall der Rechnername in eine zugehörige IP-
Adresse umgewandelt werden. Aus Sicherheitsaspekten ist es
manchmal wünschenswert, auch den umgekehrten Weg zu gehen,
nämlich zu einer sich meldenden Adresse den Namen und damit
die organisatorische Zugehörigkeit offenzulegen.
Kennt man die Domänenadresse eines Rechners, dann hängt
man diese einfach an den Usernamen mit einem At-Zeichen '@'
dahinter, z. B.:
| Stefan Meier | entspricht de Benutzerpseudonym (meier) |
| bei Huber | entspricht dem Rechner (mail) |
| Beispielweg 5 | entspricht der (Sub-) Domain (e-technik) |
| 81234 München | entspricht der (Sub-) Domain (fh-muenchen) |
| West-Germany | entspricht der (Toplevel-) Domain (de) |
Damit das DNS funktioniert muß es Instanzen geben, die Namen in IP-Adressen und IP-Adressen in Namen umwandeln ('auflösen') können. Diese Instanzen sind durch Programme realisiert, die an größeren Maschinen ständig (meist im Hintergrund) im Betrieb sind und 'Nameserver' heißen. Jeder Rechner, der an das Internet angeschlossen wird, muß die Adresse eines oder mehrerer Nameserver wissen, damit die Anwendungen auf diesem Rechner mit Namen benutzt werden können. Die Nameserver sind für bestimmte Bereiche, sogenannte 'domains' oder 'Zonen', zuständig (Institute, Organisationen, Regionen) und haben Kontakt zu anderen Nameservern, so daß jeder Name aufgelöst werden kann.
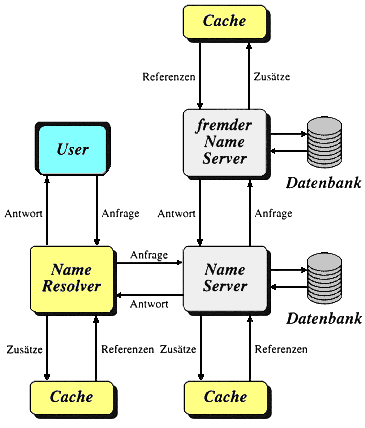
Die Baumstruktur des DNS soll nun im weiteren untersucht werden. Ausgehend von der Wurzel (Root) folgen die Toplevel Domains. Diese Toplevel Domains spalten sich in weiteren Unterdomains auf.
Der Nameserver des DNS verwaltet also einzelne Zonen, die einen Knoten im DNS-Baum und alle darunterliegenden Zweige beinhalten. Auf jeder Ebene des DNS-Baums kann es Namesever geben, wobei jeder Nameserver seinen nächsthöheren und nächstniedrigeren Nachbarn kennt. Aus Sicherheitsgründen gibt es für jede Zone in der Regel mindestens zwei Nameserver (primary und secondary), wobei beide die gleiche Information halten. Nameservereinträge können nicht nur die Zuordnung Rechnername - IP-Adresse enthalten, sondern (neben anderem) auch weitere Namenseinträge für einen einzigen Rechner und Angaben für Postverwaltungsrechner einer Domain (MX, mail exchange).
Basis des Nameservice bilden die "Root-Nameserver", die für die Top-Level-Domains zuständig sind. Die Mehrheit dieser Server ist in den USA beheimatet:
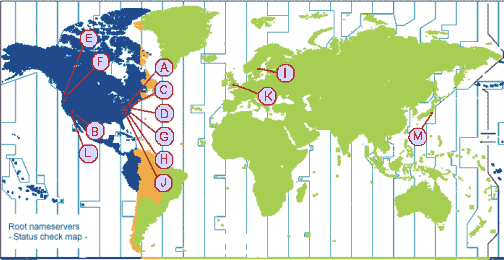
| Name | Typ | Betreiber | URL |
|---|---|---|---|
| a | com | InterNic | http://www.internic.org |
| b | edu | ISI | http://www.isi.edu |
| c | com | PSINet | http://www.psi.net |
| d | edu | UMD | http://www.umd.edu |
| e | usg | NASA | http://www.nasa.gov |
| f | com | ISC | http://www.isc.org |
| g | usg | DISA | http://nic.mil |
| h | usg | ARL | http://www.arl.mil |
| i | int | NordUnet | http://www.nordu.net |
| j | ( ) | (TBD) | http://www.iana.org |
| k | int | RIPE | http://www.ripe.net |
| l | ( ) | (TBD) | http://www.iana.org |
| m | int | WIDE | http://www.wide.ad.jp |
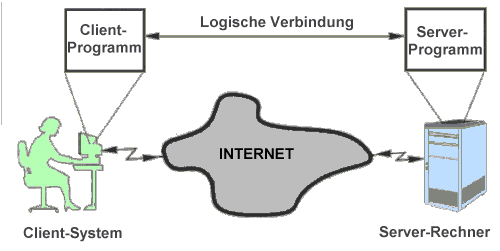
Der Server (bzw. das Server-Programm) stellt einen Dienst zur Verfügung, der vom Client angefordert werden kann. So gibt es z. B. spezielle Server(-programme) für den Datenaustausch über FFP, zum Abruf von WWWW-Dokumenten, oder Mail-Server, welche vom Mail-Client abgesendete Post entgegennehmen und weiterleiten und ankommende Post annehmen und ablegen, bis man sie mit dem Mail-Client abruft. Client und Server unterhalten sich dabei in einer speziellen Sprache - dem entsprechenden Dienstprotokoll. So gibt es ein Protokoll zwischen dem Mail-Server und dem Mail-Client (z.B. SMTP oder POP3), eines für den Dateiaustausch zwischen FTP-Client und FFP-Server, ein weiteres für WWW u.s.w. Manche Server bedienen sich zur Ausführung von Aufträgen wieder weiterer Server: Der Name-Server beispielsweise setzt die textuelle Internet-Adresse in eine numerische Adresse um.
| Required | Recommended | Elective | Limited Use | Not Recommended | |
| Standard | o | * | * | ||
| Draft | o | o | * | ||
| Proposal | o | * | o | o | |
| Experimental | o | * | o | ||
| Historic | o | * |
Legende: * bevorzugter Zustand, o möglicher Zustand
Irgendwann entdeckte Morris im Berkley UNIX zwei Fehler, die nicht autorisierten Zugriff auf Maschinen im gesamten Internet ermöglichten. Damals umfaßte das Netz schon zirka 60.000 Computer. Wieso Morris den Wurm geschrieben hat, ist nicht klar. Auch wurde nicht untersucht, ob es sich nur einen verunglückten Test oder böse Absicht handelte.
Technisch betrachtet bestand der Internet-Wurm aus zwei Programmen:
Um den nicht autorisierten Zugriff zu neuen Computern zu bekommen, um dort dann das Bootstrap-Programm zu compilieren und zu starten, hatte der Internet-Wurm vier Methoden:
Die Entdeckung des Wurm beruht auf einem kleine Denkfehler von Morris. Der Wurm hat so gearbeitet, daß er nur Computer angriff, die nicht schon vom Wurm befallen waren. In einem von 15 Fällen sollte trotzdem ein Wurm gestartet werden, um sicherzustellen, daß der Wurm nicht stirbt (z. B. bei Vortäuschung eines Wurmbefalls). Leider wurde in 14 von 15 Fällen der Wurm repliziert, so daß einige Computer so stark an Leistung verloren, daß die Administratoren aufmerksam wurden.
Gefaßt wurde Morris durch einen Versprecher einer seiner Freunde während eines Interviews. Dieser erzählt dem Reporter von der New York Times, daß der Wurm nur ein Unfall war und es dem Autor leid tut. Dabei rutscht ihm der Benutzername heraus, so daß es nicht mehr schwer war, den wirklichen Namen zu ermitteln. Das Gericht verurteilte Morris zu $ 10000 Strafe, 3 Jahren Haft und 400 Stunden gemeinnützige Arbeit. Zusätzlich entstanden $ 150.000 Gerichtskosten.
Nach der Verurteilung von Morris gab es eine große Kontroverse. Teils wurde
die Meinung vertreten, er sei intelligenter Student, der nur etwas gespielt habe.
Von anderen wurde er für einen Kriminellen gehalten, der ins Gefängnis müsse.
Als unmittelbare Folge wurde im Dezember 1988 ein sogenanntes "Computer Emergency
Response Team" (CERT) ins Leben gerufen. Heute kontrolliert das CERT Coordination
Center die Tätigkeit verschiedener CERTs. Es gibt eine Telefon-Hotline und
verschiedene Publikationsorgane, die auf Sicherheitslücken hinweisen und den
Anwendern Hilfestellung geben. Nach dem Vorbild der CERTs wurden seitdem weltweit
ähnliche Gruppen aufgebaut.
Auch von mir noch ein paar Bemerkungen (2008):
Es sind einige Dienste verschwunden bzw. vom World Wide Web "aufgesogen" worden (inzwischen wird ja oft "Internet" und "WWW" als Synonym betrachtet), z. B. Archie, Gopher, Wais. Im Grunde gibt es auch nur noch einen Suchdienst: Google. Mit Apples Bindung der Kunden an das System ist auch die Zensur wieder da - was an Literatur, Musik, Filmen und Apps für iPad und iPhone angeboten werden darf, bestimmt Apple.
Aus dieser Isolation heraus entstanden dann einerseits Onlinedienste wie Compuserve, die weltweit Rechner unterhalten (Einwählpunkte, "Points of Presence"). Die Daten laufen aber in einer Zentrale zusammen. Einen anderen Weg, die lokale Begrenzung zu überwinden, sind die Mailboxnetze wie z. B. Fidonetz, Zerberusnetz oder Mausnetz (von Spöttern als "Tiernetze" tituliert). Hier tauschten die Mailboxrechner nachts oder sogar stündlich die neuen Mitteilungen vollautomatisch untereinander aus.
Ein weiterer Unterschied vieler Mailboxnetze ist die Form der Datenweitergabe von Einträgen in 'schwarzen Brettern' und E-Mail. Beim Fidonetz werden die Daten grundsätzlich nach dem gleichen Verfahren transportiert, es wird hier in "personal mail" (entpricht E-Mail) und "netmail" (entspricht News) unterschieden. Später wurde bei fast allen größeren Mailboxen neben den lokalen Informationen auch ein Zugang zum Internet in Form von News und E-Mail geboten. Außerdem gibt es Übergänge (Gateways) zwischen den Netzen.
Die verschiedenen Online-Dienste zeichneten sich durch teilweise sehr unterschiedliche Angebote aus. Die beiden größten in Deutschland waren AOL und T-Online. Sie boten alle ein großes Angebot an Tagesinformationen (Agenturnachrichten, Börseninformationen etc.), Computerinformationen und elektronischen Treffpunkten (Diskussionsforen und Konferenzen). Erst sehr spät kam Microsoft mit seinem "Microsoft Network" (MSN) hinzu, das beim Launch von Windows 95 noch heftig beworben wurde. Aber inzwischen war der Internetzug unaufhaltsam am Rollen und die Truppe von Billiboy schaffte es gerade noch mit Hängen und Würgen, aufzuspringen. Heute sind MSN nur noch ein Portal, ALO eher ein Filmproduzent, T-Online wieder in T-Com eingegliedert und Compuserve gänzlich verschwunden.
Im weitesten Sinn gehörte auch das deutsche Bildschirmtext-System zu den Mailboxen (aber eben vom Hoheitsträger betrieben). Die Deutsche Bundespost startete einen interaktiven Online-Dienst, der anfangs ein spezielles Btx-Gerät erforderte. 1993 wurde BTX Bestandteil des neu geschaffenen Dienstes "Datex-J". BTX verlor zunehmend seine Bedeutung aufgrund der Konkurrenz durch das offene Internet. In Deutschland wurde BTX im Mai 2007 endgültig eingestellt. Der Dienst wurde auch in Österreich und der Schweiz angeboten, bei den Franzosen führte man einen ähnlichen Dienst durch die Hintertür ein, es gab nämlich einfach statt des Telefonbuchs ein Minitel-Terminal und einen entsprechenden Account.
Vorgestellt wurde Btx bereits 1977 bei der Internationalen Funkausstellung in Berlin. Erst 1980 startete ein Feldversuch mit jeweils etwa 2000 Teilnehmern in Düsseldorf und Berlin. Die erwarteten Nutzerzahlen nach dem offiziellen Start 1983 wurden allerdings nie erreicht. So sollten es 1986 rund eine Million sein, tatsächlich waren es aber nur 60 000. Die Million wurde erst zehn Jahre später erreicht, nachdem Btx ab 1995 mit dem neuen T-Online-Angebot inklusive E-Mail und Internet-Zugang gekoppelt worden war. Am 31. Dezember 2001 wurde der ursprüngliche Btx-Dienst offiziell abgeschaltet und nur noch eine abgespeckte Variante für Online-Banking bis zum 10. Mai 2007 betrieben.
 Zum Inhaltsverzeichnis
Zum Inhaltsverzeichnis
 Zum nächsten Abschnitt
Zum nächsten Abschnitt
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}