 |
INTERNET - Möglichkeiten und DiensteProf. Jürgen Plate |
|
INTERNET - Möglichkeiten und DiensteProf. Jürgen Plate |
"The Information Superhighway is a misnormer.
First, there's no highway - there are no roadmaps,
guides, rules. And second, it ain't super."
David Martin.
Die einzelnen Dienste, die man heute im Internet in Anspruch nehmen kann, haben sich nach und nach entwickelt. Zu Beginn wurde die Basis des Internets von den drei Diensten elektronische Post, Telnet und FTP gebildet. Später kamen dann Informationsdienste wie News, Archie, Gopher und WAIS hinzu. Der jüngste Dienst ist WWW, der nahezu alle anderen Dienste integrieren kann. Deshalb fange ich mit dem wichtigsten Basisdienst, der elektronischen Post, an und schließe mit WWW den Überblick.
E-Mail:
Inzwischen ist es schick, eine E-Mail-Adresse auf der Visitenkarte zu
haben. Auch in Veröffentlichungen in Zeitungen und Zeitschriften
finden sich Mail-Adressen der Autoren und Herausgeber als Möglichkeit
der Kontaktaufnahme. Der 'Klammeraffe' wird in Namen von Produkten, Firmen
und Zeitschriften als Ersatz für das 'a' verwendet (sprachlich ein
Paradox, denn das ASCII-Zeichen '@' wird 'at' ausgesprochen).
Bei E-Mail (auch 'Email', 'e-mail' oder schlicht nur 'Mail' genannt)
handelt es sich um einen schnellen, bequemen Weg, Nachrichten
bzw. Dokumente zwischen Rechnersystemen mit dem gewünschten
Partner auszutauschen. Obwohl E-Mail der einfachste (und auch
wohl älteste) netzübergreifende Dienst ist, will ich
ihn etwas ausführlicher behandeln. Die anderen Dienste sind dann
um so leichter zu verstehen.
Computer, die mit einem Multiuserbetriebssystem ausgestattet sind, also
Systeme, bei denen mehrere Anwender (quasi-)gleichzeitig arbeiten
können, besitzen nahezu alle die Möglichkeit, daß
sich diese Anwender auch untereinander verständigen können.
Das geschieht mittels eines kleinen Programms, das es ermöglicht,
Nachrichten zu schreiben und diese dann an einen gewünschten
Empfänger zu schicken. Der Adressat erhält dann beim
nächsten Login den Hinweis auf neu eingegangene Post. Je nach
Verbindung zu anderen Rechnern wird die Nachricht direkt zum
Empfänger geschickt oder über einige Zwischenstationen
geleitet (hier zeigt sie die Analogie zur althergebrachten Post).
Für diese Art des Versendens von Mitteilungen hat sich sehr schnell der
englische Begriff 'Mail' (auf deutsch 'Post') eingebürgert. Und
da es sich nicht um eine Post im üblichen Sinne handelt, also
auf Papier geschrieben und im Umschlag überreicht, bezeichnet
man das Ganze als 'Electronic Mail' oder kurz 'E-Mail'. Auch im
Deutschen haben sich die englischen Begriffe 'Mail' und 'E-Mail'
etabliert. Wird ein Computer an ein Netz angeschlossen, kann die
E-Mail nicht nur an Benutzer auf dem lokalen System, sondern auch an
Benutzer jedes Rechners im Netz versendet werden. Ist das Netz seinerseits
an das Internet angeschlossen, kann die E-Mail prinzipiell an jeden
Benutzer eines Rechners im Internet versendet werden.
Die E-Mail gewann in den letzten Jahren spürbar an Bedeutung,
sowohl in der Wirtschaft als auch in der Technik, da es sich gezeigt hat,
daß diese Art der Kommunikation die schnellste ist, die es gibt. Es ist
eine Tatsache, daß die Erfolgsquote bei der E-Mail sogar noch
höher liegt als beim Telefon.
Mit Erfolgsquote ist gemeint, daß man die Nachricht nach dem
Absenden vergessen kann; man muß nicht warten, bis man den
Empfänger eventuell erst nach mehreren Versuchen erreicht (z. B.
mehrmals Anrufen oder warten, bis das Faxgerät beim Empfänger
frei ist). Heutzutage ist E-Mail nicht nur mehr auf einem
Mehrbenutzer-Computersystem üblich. Man verteilt vielmehr
die Post an andere Rechner, so daß überregionale
Kommunikation per E-Mail abgewickelt werden kann.
Je nach verwendetem Mail-System gibt es meist noch weitere Funktionen,
z. B. das Weiterleiten von Nachrichten (ggf. mit Kommentar),
Versenden von Nachrichten an mehrere Empfänger,
Benachrichtigung des Versenders einer Nachricht, daß Mail
beim Empfänger angekommen und gelesen wurde. Übrigens, wenn
Sie nur den Rechner, aber nicht die genaue Benutzerkennung wissen,
dann schreiben Sie versuchsweise an den 'postmaster' des Systems. Der
'postmaster' ist die Mail-Adresse, bei der alle Fehlermeldungen, aber
auch Anfragen von außen, z. B. nach Benutzerkennungen,
anlaufen. Dahinter versteckt sich normalerweise der Systemverwalter.
Briefe, die an einen anderen Computer gehen, werden in der
Regel sofort abgeschickt, so daß sie der Empfänger im
Internet in kurzer Zeit erhält. Briefe, die innerhalb eines
Systems verschickt werden, erreichen ihren Empfänger ein
paar Sekunden nach dem Abschicken.
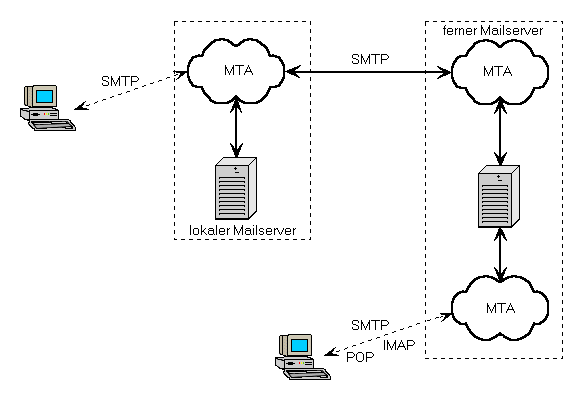
Rechner mit direkter TCP/IP-Verbindung tauschen ihre E-Mail direkt aus. Das
Protokoll heißt SMTP (Simple Mail Transfer Protocol). Hier wird
die E-Mail dem Zielrechner direkt zugestellt, mehr dazu im Kapitel 4.
Die E-Mail kann nicht nur mit über das Netz transportiert
werden, sondern auch z. B. über eine Modemverbindung über
die normale Telefonleitung, weshalb wesentlich mehr Rechner via
E-Mail erreichbar sind als im Internet existieren. Auch die Benutzer
von Mailboxnetzen wie Compuserve, AOL oder T-Online sind per E-Mail
erreichbar. Außerdem gibt es auch Erweiterungen der
Mail-Software, die das Nachsenden der elektronischen Post an jeden
Ort der Welt oder das Bereithalten zur Abholung ermöglichen. Es
gibt sogar automatische Antwortprogramme (z. B. für
Infodienste).
MIME (Multipurpose Internet Mail Extensions) fügt diesem Standard vier weitere Felder hinzu, die genauer den Inhalt des Briefes spezifizieren. Aus diesen Feldern kann das Post-Programm, so es diese berücksichtigt, entnehmen, welche anderen Programme aufzurufen sind, um z. B. ein Bild darzustellen. Das heißt nicht, daß die Daten im Brief nicht codiert würden, aber ein MIME-konformes Post-Programm bietet die Möglichkeit, alle Codierungsvorgänge zu automatisieren.
Das erste Feld, welches der MIME-Standard definiert, heißt MIME-Version:. Bislang gibt es nur die Version 1.0, so daß der Eintrag 1.0 dem Standard genügt. Mit der Verwendung dieses Feldes wird dem Post-Programm signalisiert, daß der Inhalt des Briefes mit dem MIME-Standard konform geht.
Kannte der RFC 822 zwei Teile eines Briefes, nämlich den Kopf und den Text, so können Briefe im MIME-Format aus mehreren Teilen bestehen. Die Zeile MIME-Version: 1.0 muß nur einmal im Kopf des Briefes auftauchen. Die anderen Felder, welche der MIME-Standard definiert, können öfter verwendet werden. Sie beschreiben dann jeweils die Einzelteile, aus denen der Brief besteht. Ein Beispiel:
...
MIME-Version: 1.0
Content-Type: MULTIPART/MIXED; BOUNDARY="8323328-2120168431-
824156555=:325"
--8323328-2120168431-824156555=:325
Content-Type: TEXT/PLAIN; charset=US-ASCII
Textnachricht....
--8323328-2120168431-824156555=:325
Content-Type: IMAGE/JPEG; name="teddy.jpg"
Content-Transfer-Encoding: BASE64
Content-ID: <Pine.LNX.3.91.960212212235.325B@localhost>
Content-Description:
/9j/4AAQSkZJRgABAQAAAQABAAD//gBqICBJbXBvcnRlZCBmcm9tIE1JRkYg
aW1hZ2U6IFh0ZWRkeQoKQ1JFQVRPUjogWFYgVmVyc2lvbiAzLjAwICBSZXY6
[..]
se78SaxeW7Qz3zeW33tqqu7/AHtv3qyaKmOGox96MSeSIUUUVuUFFFFABRRR
RZAFFFFABRRRTAKKKKACiiigAooooA//2Q==
--8323328-2120168431-824156555=:325--
Mit dem Feld "Content-Type:" wird der Inhalt eines Briefes beschrieben. Im Kopf
des Briefes legt das Feld "Content-Type:" den Aufbau des ganzen Briefs
fest. Das Stichwort Multipart signalisiert, daß der Brief aus mehreren
Teilen besteht. Der Untertyp von "Multipart Mixed" liefert den Hinweis, daß
der Brief aus heterogenen Teilen besteht. Der erste Teil dieses Beispiels besteht
denn auch aus Klartext, und der zweite Teil enthält ein Bild. Die einzelnen
Teile des Briefes werden durch eine Zahlenkombination eingegrenzt, die im Kopf des
Briefes im Feld "Boundary" festgelegt wurde. Diese Grenze (Boundary) ist nichts
weiter als eine eindeutig identifizierbare Zeichenfolge, anhand derer die einzelnen
Teile einer E-Mail unterschieden werden. Ein MIME-konformes Post-Programm sollte
anhand dieser Informationen jeden einzelnen Teil adäquat darstellen können.
Im Feld "Content-Type:" können sieben verschiedene Typen festgelegt werden,
die jeweils bestimmte Untertypen zur genaueren Beschreibung des Inhalts umfassen:
Dem Typ "text" kann noch der Parameter "charset:" beigefügt werden. Die Vorgabe der Programme lautet in der Regel "charset: us-ascii". Anstelle von "us-ascii" kann hier auch "iso-8859-1" oder etwas anderes eingetragen werden. Inzwischen werden auch vielfach E-Mails, markiert durch "text/html", wie HTML-Seiten codiert.
Über kurz oder lang stößt wohl jeder Benutzer der elektronischen Post auf folgende Zeichen: =E4, =F6, =FC, =C4, =D6, =DC, =DF; im Klartext: ä, ö, ü, Ä, Ö, Ü, ß. Für den Fall, daß der Brief Zeilen enthält, die länger als 76 Zeichen sind, erscheint ein "="-Zeichen am Ende der Zeile für den automatischen Zeilenumbruch. Verantwortlich für dieses Phänomen ist der Eintrag "quoted-printable" im Feld "Content-transfer-encoding". Mit der Vorgabe "quoted-printable" soll ein MIME-konformes Post-Programm alle Zeichen, deren Wert größer als 127 ist, hexadezimal mit einem vorangestellten Gleichheitszeichen darstellen, und es soll Zeilen, die länger als 76 Zeichen sind, umbrechen. Unter Umständen werden noch einige andere Zeichen codiert. Einige Post-Programme verwenden von vornherein "quoted-printable", obwohl eine andere Belegung des Feldes möglich ist; z. B.: "7bit", "8bit", "binary", "base64". Die ersten drei signalisieren allgemein, daß keine Codierung vorgenommen wurde. "7bit" signalisiert insbesondere, daß ein Brief reine ASCII-Zeichen enthält; "8bit", daß ein Brief über den ASCII-Zeichensatz hinausgeht, und "binary", daß es sich um 8-Bit-Zeichen handelt, wobei die Zeilenlänge über 1000 Zeichen hinausgehen kann. Ein mit "base64" codierte Teil des Briefes besteht nur noch aus Zeichen, die mit 7 Bit dargestellt werden können. Der Vorteil dieses Codierungsverfahrens besteht im Gegensatz zu anderen darin, daß diese Untermenge in vielen anderen Zeichensätzen ebenfalls enthalten ist. Damit wird eine fehlerfreiere Übermittlung erreicht, als mit anderen Verfahren.
| Wert | Code | Wert | Code | Wert | Code | Wert | Code |
|---|---|---|---|---|---|---|---|
| 0 | A | 17 | R | 34 | i | 51 | z |
| 1 | B | 18 | S | 35 | j | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v | ||
| 14 | O | 31 | f | 48 | w | ||
| 15 | P | 32 | g | 49 | x | ||
| 16 | Q | 33 | h | 50 | y | ||
| Padding: = | Quelle: RFC 2045 | ||||||
Der Begriff "Text" ist nicht damit gleichzusetzen, daß das Ergebnis der Codierung auf den ersten Blick lesbar ist. Die Buchstaben, Ziffern und die Zeichen "+", "/" und "=" dienen lediglich als Symbole für die entsprechenden Bitfolgen. Die Tabelle zeigt die Übersetzung gemäß "Base64", wobei die Angabe der Werte in den zu übersetzenden Bitfolgen (jeweils sechs Bit) in dezimaler Schreibweise erfolgt. Das Zeichen "=" hat eine besondere Bedeutung, denn es dient als Füllzeichen (Padding), wenn die Menge der zu übertragenden Zeichen aus den Quelldaten kein Vielfaches von vier darstellt. Die Übertragung dieser Zeichen erfolgt in Textzeilen, die maximal 76 Zeichen beinhalten. Alle nicht im Base64-Alphabet definierten Zeichen einschließlich Zeilenumbrüchen werden bei der Decodierung ignoriert.
From: Mail delivery Subsystem Subject: Returned mail: Host unknown (Name server: ns.e-technik.fh-muenchen.de: host not found)oder
From: Mail delivery Subsystem Subject: Returned mail: User unknownüberprüfen Sie nochmals die Adreßangabe. Haben Sie bei einer Mail-Adresse in einem anderen Netzwerk die Übersetzungskonventionen richtig beachtet?
begin 600 DOKUMENT.DOC
M(&=R;]]E;B!3>7-T96UE;B!J961O8V@@875C:"!I;2!G;&5I8VAE;B!L;VMA
M;&5N($YE='H@;V1E<B!S;V=A<B!A=68@9&5M(&=L96EC:&5N(%)E8VAN97(@
M=VEE(&1E<B!#;&EE;G0@87)B96ET96XN($%U9B!E:6YE;2!296-H;F5R(&OV
M;FYE;B!M96AR97)E(%-E<G9E<BU0<F]G<F%M;64@;&%U9F5N("T@96EN(%)E
M8VAN97(@:V%N;B!D86UI="!M96AR97)E(%-E<G9E<BU$:65N<W1E('IU<B!6
.....
end
Das Mailprogramm sollte mittels uuencode codierte Mail automatisch und ohne Zutun des Benutzers decodieren können. Ähnlich gelagert ist das Problem, wenn die Datei nach 'base64' codiert ist. Es handelt sich dabei um eine MIME-codierte Anlage (siehe oben). MIME-Mails sind typischerweise an den eingestreuten Steuerzeilen (Content-Type: application/octett-stream) und Trennzeilen (--==================_8769453AF34==_) erkennbar.
Wer mehr über die Header in E-Mails wissen will, findet hier ein Mailheader-FAQ.
In News können die Beiträge von allen Benutzern gelesen und in
der überwiegenden Zahl der Gruppen können auch eigene
Artikel oder Antworten veröffentlicht werden. Dies eröffnet
etliche neue Möglichkeiten. Man kann oft feststellen, daß
Probleme (und deren Lösungen) anderer News-Benutzer auch
für einen selbst von Interesse sind, und es bestehen bei eigenen
Problemen gute Aussichten, daß einer der vielen Experten (die
sogenannten 'Gurus' oder 'Wizards') relativ schnell weiterhelfen
kann. Umgekehrt sollte man sich die Zeit nehmen, Fragen anderer
News-Nutzer zu beantworten, denn das System funktioniert nur 'auf
Gegenseitigkeit'. News ist deshalb auf keinen Fall nur eine
kurzweilige Unterhaltung für Computer-Begeisterte, sondern eine
ernst zu nehmende Informationsquelle und eine neue Möglichkeit,
die wissenschaftliche Zusammenarbeit auf vielen Gebieten zu
unterstützen.
Darüber hinaus eröffnet News vollkommen neue Möglichkeiten der
Publikation und der schnellen Diskussion innerhalb eines
internationalen, offenen Teilnehmerkreises. Dies wird bisher zwar nur
in speziellen Fachrichtungen genutzt, wird in Zukunft jedoch bestimmt
auf breiteres Interesse stoßen. Wer sich schon gleich zu Beginn
auf das Lesen weniger ausgesuchter Newsgruppen beschränkt,
kann von Anfang an News als wertvolle Informationsquelle mit
minimalem Zeitaufwand kennenlernen. Damit Sie sich nicht gleich als
Anfänger outen, zunächst ein paar Fachbegriffe und weiter
unten einige Verhaltensregeln:
Einige Begriffe (nach ihrer Wichtigkeit aufgeführt):
Die Newsgruppen sind hierarchisch geordnet. Unterhalb der oben angegebenen Hierarchien wird weiter verzweigt, wobei die einzelnen Hierarchiestufen durch Punkte getrennt werden. Bei landesspezifischen Gruppen wird das Länderkürzel vorangestellt, z. B. für deutschsprachige Gruppen 'de'; die deutsche Entsprechung von 'comp' ist somit 'de.comp'. Dann kann man weiter unterteilen, z. B. für die Duskussion über Computer-Betriebssysteme (operating systems) 'de.comp.os' Nachdem es verschiedene Betriebssysteme gibt, entstehen dann Gruppen wie 'de.comp.os.linux', 'de.comp.os.minix', 'de.comp.os.os2', 'de.comp.os.unix', usw. Eine Unterteilung wird oft dann vorgenommen, wenn die Anzahl der täglichen Artikel in einer Newsgruppe zunimmt und die Gruppe unübersichtlich wird. Die Newsgruppenhierarchie 'de.*' ist übrigens eine internationale deutschsprachige Hierachie im Usenet. Es ist nicht die Deutschlandhierachie, eine Hierachie für Deutschland gibt es nicht.
Einige Newsgruppen enthalten auch Binärdaten (Programme, Bilder, Sound-Dateien etc.). Sie sind durch den Begriff 'binaries' im Namen der Gruppe erkennbar (z. B. comp.binaries.msdos). Da nach wie vor 7-Bit-ASCII als kleinster gemeinsamer Standard für News und Mail gilt, lassen sich Binärdateien nicht ohne weiteres posten. Abhilfe schaffen hier die Programme UUENCODE und UUDECODE, mit deren Hilfe sich binäre Daten auf den Bereich der druckbaren ASCII-Zeichen (Großbuchstaben, Ziffern und Sonderzeichen) abbilden lassen. Es werden also Bytes in 6-Bit-Worten codiert und in Zeilen umbrochen. Die mit UUENCODE erzeugte Datei ist nun zwar größer als die Ursprungsdatei, sie läßt sich aber problemlos per News (oder Mail) verbreiten.
Das wachsende Newsaufkommen hat aber auch zu unschönen Erscheinungen geführt. Die Gruppen sind zwar thematisch untergliedert, aber man findet trotzdem immer mehr uninteressante Beiträge, endlose Streitereien um des Kaisers Bart oder Artikel, die überhaupt nicht zum Thema passen. Der Anteil an solchen nutzlosen Beiträgen wird oft in Analogie zur Störung beim Rundfunkempfang als 'Rauschen' bezeichnet. Das hat bei ständigen Newsbenutzern zu einer Absenkung der Toleranzschwelle geführt. Man muß bedenken, daß nicht nur das Lesen selbst Zeit kostet (selbst wenn man sich auf Überschriften beschränkt), sondern auch der Datentransport der News bis zum Rechner des Lesers in der Regel Telefonkosten verursacht. Wenn dann nur Unsinn zu lesen ist, reagieren die News-Benutzer irgendwann sauer. Insbesondere Nachrichten meist werblichen Inhalts, die in zahlreichen Diskussionsgruppen veröffentlicht werden und in keinem dieser Foren eigentlich einen Platz haben, lösen heftige Raktionen (sogenannte 'flames') aus. Solche Massenveröffentlichungen haben den passenden Namen 'spam' (Sülze) erhalten. Das Rauschproblem hängt aber auch damit zusammen, daß viele Provider ihre Benutzer ohne jede Anleitung auf das Netz loslassen.
Zum Schluß des Abschnitts möchte ich noch auf Newsgruppen hinweisen, die Informationen zu den verschiedensten Themen enthalten. Die wichtigsten sind news.answers und de.newusers. Dort finden Sie die sogenannten 'FAQ's (Frequently Asked Questions and Answers), in denen Antwort auf viele Fragen gegeben wird. Bevor man also eine Frage in den News losläßt, erst einmal in den FAQs stöbern. Sonst gibt es als Antwort auf eine Frage höchstens ein 'RTFM' (Read The Fucking Manual = Lies das Sch...-Handbuch) oder 'RTFAQ'. In Kapitel 4 wird das Thema News noch weiter vertieft. Ein Begriff sollte aber gleich noch geklärt werden, 'Usenet' User Network). News-Artikel und auch Mail sind nicht an das Internet gebunden, sondern können auch auf anderen Wegen, z. B. per Modem-Transfer, ausgetauscht werden (bei den News ist das durch die gewaltigen Datenmengen praktisch nur eingeschränkt möglich). Der Begriff 'Usenet' ist jedoch schwer zu fassen. Deshalb der Versuch einer Unterscheidung: Ein Internet ist eine Menge von Rechnern, die sich via IP ständig (!) untereinander verständigen können. Damit ist ein Internet ein Netz von sich technisch verstehenden Systemen. 'Ständig' ist auf definierte Zeiträume einschränkbar (für PPP und SLIP), heißt aber generell: jederzeit bis auf technische Pannen. Usenet-Rechner müssen darüberhinaus auch E-Mail senden und empfangen können. Dazu noch ein Zitat von Ed Krol aus seinem Buch 'Die Welt des Internet': 'USENET ist eines der am häufigsten mißverstandenen Konzepte. Es ist kein Rechnernetz. Es hängt nicht vom Internet ab. Es ist keine Software. Es ist eine Sammlung von Regeln, wie Newsgruppen weitergeleitet und verwaltet werden. Es ist außerdem ein Haufen Freiwilliger, die diese Regeln anwenden und respektieren. [...]. USENET besteht aus sieben gut verwalteten Newsgruppen-Hierarchien.'
Auch wenn Newsgruppen sind nach wie vor großer Beleibtheit erfreuen, haben sie Konkurrenz bekommen. Die Web-basierten "Blogs" und "Wikis":
Die ersten Weblogs tauchten Mitte der 1990er Jahre auf. Sie wurden Online-Tagebücher genannt und waren Webseiten, auf denen Internetnutzer periodisch Einträge über ihr eigenes Leben machten. Um 2004 wurde das "Bloggen" immer mehr kommerziell eingesetzt. Viele Online-Medien betreiben eigene Blogs, um ihren Leserkreis zu erweitern. D
Wikis gehören zu den Content-Management-Systemen, setzen aber auf die Philosophie des offenen Zugriffs, im Unterschied zu teils genau geregelten Arbeitsabläufen von Redaktionssystemen. Mit "offenem Zugriff" ist aber nicht gemeint, dass zwangsläufig jedes Wiki für alle lesbar oder schreibbar sein müsste, es kann sehr wohl Berechtigungen oder Beschränkungen für bestimmte Benutzergruppen geben.
Erste Wikis entstanden als Wissensverwaltungswerkzeuge von Architekten im Rahmen der Entwurfsmuster-Theorie. Das erste Wiki, WikiWikiWeb genannt, wurde vom US-amerikanischen Softwareautor Ward Cunningham ab 1994 entwickelt und 1995 übers Internet verfügbar gemacht. Das Wiki basierte auf Ideen aus HyperCard-Systemen, den Vorläufern des World Wide Web. Den Namen wählte Cunningham, da er bei der Ankunft am Flughafen auf Hawaii die Bezeichnung Wiki Wiki für den dortigen Shuttlebus kennengelernt hatte. Dabei übernahm er die Verdoppelung, die im Hawaiischen für eine Steigerung ("sehr schnell") steht.
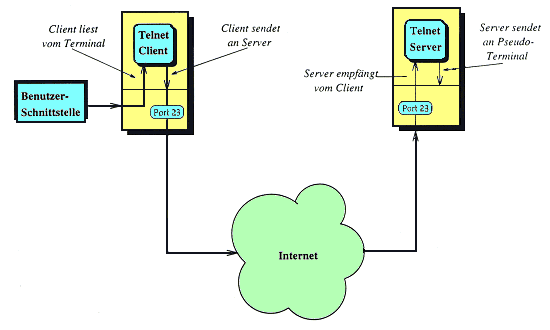
Deshalb kann es bei Programmen zu Problemen kommen, die bildschirmorientiert arbeiten (z. B. Editoren). Für die Steuerung der Ausgabe, beispielsweise die Positionierung der Schreibmarke oder die Einstellung der Bildschirmfarbe, werden Steuerzeichen gesendet, welche die Terminal-Emulation 'verstehen' muß. Man hat also den gleichen Funktionsumfang wie ein lokal an dem jeweiligen Rechner angeschlossenes Terminal - egal wie weit der Rechner entfernt ist. Ist der Verbindungsaufbau erfolgreich, erscheint der Login-Prompt des fernen Rechners. Man kann sich prinzipiell an jedem Rechner im Internet einloggen - vorausgesetzt, man besitzt dort eine Zugangsberechtigung. Viele Rechner bieten jedoch auch einen Gastzugang. Es werden aber auch spezielle Informationsdienste angeboten. Um beispielsweise Whois-Anfragen abzusetzen, kann Telnet verwendet werden. Auch bieten manche Rechner über Telnet Zugang zu Multiuser-Spielen.
Primär dient Telnet aber dem Shell-Zugang auf einem fernen Rechner. Bei Shell-Zugängen verwenden Sie lediglich die Tastatur Ihres Computers, den "Rest" Ihres Computers brauchen Sie eigentlich gar nicht (so wie damals mit DOS beim PC). Sobald Sie die Verbindung zum fernen Rechner aufgebaut haben, können Sie all das auf dem Rechner machen, was man auch lokal an der Konsole machen kann. Je nach Betriebssystem (meist ist es UNIX) müssen Sie dessen Befehle lernen. Für den 'Normalnutzer' spielt Telnet eine untergeordnete Rolle, dagegen kann ein Administrator alle ihm unterstehenden Computer bedienen, ohne seinen Arbeitsplatz verlassen zu müssen.
Es gilt übrigens als ausgesprochen unhöflich, beispielsweise von München aus ein Programm in Hawaii abzuholen, wenn man es genausogut von Stuttgart bekommen kann (die Leitungen ins Ausland sind noch nicht so zahlreich, und man sollte deren Belastung möglichst gering halten). Benutzen Sie ausländische Server auch bitte zu Zeiten, wo diese wenig gebraucht werden, also ausserhalb der 'Bürostunden'. Meistens sieht man es der Internet-Adresse an, wo der entsprechende Server steht. Die wichtigsten Kennungen sind 'com', 'edu', 'gov', 'mil', 'net' und 'org' (siehe auch Kapitel 1). Server mit diesen Kennungen sind in der Regel in den USA stationiert (Zeitzone = Mitteleuropäische Zeit minus 6 bis 9 Stunden / Hawaii minus 12 Stunden), obwohl 'com'- und 'net'-Rechner überall auf der Welt stehen können. Andere Server erkennt man an der Länderkennung, z. B:
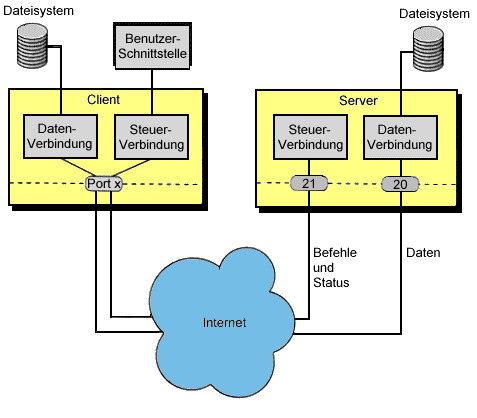
Der Verbindungsaufbau erfolgt wie bei Telnet, indem man dem FTP-Programm den gewünschten Zielrechner angibt. Bei erfolgreicher Verbindung kommt vom fernen Rechner wieder ein Login-Prompt. FTP funktioniert aber auch, wenn man auf dem fernen Rechner keine Benutzerberechtigung hat, denn viele Rechner bieten große Dateibereiche über sogenannten 'anonymen' FTP. Man gibt in diesem Fall als Benutzernamen 'ftp' (manchmal auch 'anonymous') ein und als Paßwort die eigene Mailadresse. Danach kann man sich im öffentlichen Dateibereich tummeln. Dazu braucht man nicht viele Kommandos.
Noch etwas ganz Wichtiges: Das FTP-Protokoll kennt zwei Übertragungsmodi, den Transfer von Texten und von Binärdateien. Um die Daten auch korrekt zu bekommen, sollte man auf jeden Fall mit dem Kommando 'binary' in den Binärmodus schalten (Texte werden da natürlich auch korrekt angeliefert). Es gibt inzwischen, speziell bei Windows, auch etliche grafisch orientierte FTP-Clients, die sich automatisch das Inhaltsverzeichnis des fernen Rechners holen und dieses zusammen mit dem lokalen Verzeichnis wie in einem Dateimanager anzeigen. Hier kann man dann die Dateien per Mausklick hin- und hertransportieren.
Man kann eine zusammengefaßte Liste Hunderter von Anonymous-FTP-Sites erhalten, indem man eine E-Mail-Nachricht an mail-server@rtfm.mit.edu verschickt mit diesen Zeilen im Text der Nachricht:
send usenet/news.answers/ftp-list/sitelist/part1 send usenet/news.answers/ftp-list/sitelist/part2 ... send usenet/news.answers/ftp-list/sitelist/part13 send usenet/news.answers/ftp-list/sitelist/part18Dann erhält man per E-Mail 18 Dateien, die die "FTP Site List" enthalten. Jede dieser Dateien ist etwa 60 KB groß, die komplette Liste umfaßt also insgesamt mehr als 1 MB!
Site: oak.oakland.edu
Country: USA
Organ: Oakland University, Rochester, Michigan
System: Unix
Comment: Primary Simtel Software Repository Mirror
Files: BBS lists; ham radio; TCP/IP; Mac;
mode protocol info; MS-DOS; MS-Windows;
PC Blue; PostScript; Simtel-20; Unix
Grundsätzlich beginnen alle Befehle mit einem Schrägstrich. Um
einen Kanal auszuwählen, rufen Sie entweder mit '/list'
eine Liste der verfügbaren Kanäle auf oder wechseln per
'/join #Kanalname'
direkt in einen Kanal. Nehmen wir an, Sie wollen in den Kanal
#irchelp gelangen. Dazu müssen Sie '/join #irchelp'
eingeben. Nun befinden Sie sich in einem Kanal, in dem Sie Hilfe zu
Problemen mit IRC finden. Wollen Sie nun etwas zum Gespräch
beitragen, müssen Sie Ihren Text lediglich eintippen und mit der
Return-Taste abschließen, und schon erscheint die Zeile bei den
anderen Teilnehmern des Kanals. Persönliche Nachrichten an einen
Teilnehmer sendet man mit '/msg <nickname>'.
Möchten Sie mehr über den IRC-Teilnehmer 'willy' erfahren,
geben Sie '/ctcp willy finger'
ein. Auf dem Bildschirm erscheint dann mehr Information über
ihn. Die Informationen, die andere mit diesem Befehl über Sie
erhalten, können Sie meist selbst unter '/ctcp finget reply'
in Ihrem Client eintragen.
Eine Liste der momentan auf Ihrem Server verfügbaren Kanäle
erhalten Sie, wie oben schon erwähnt, mit dem Befehl '/list'.
Diesen Befehl können Sie einschränken, indem Sie etwa mit
'/list -min20'
nur die Kanäle auflisten lassen, die mindestens 20 Teilnehmer
haben. Oder Sie zeigen mit '/list #name'
alle Kanäle, bei denen 'name' im Titel vorkommt. Übrigens
kann es vorkommen, daß der Server nach dem List-Kommando die
Verbindung beendet. Der Grund ist ein Schutzmechanismus im IRC, der
verhindern soll, daß mehr Zeichen auf einmal übertragen
werden, als man tippen kann. So kann niemand einen Kanal mit Texten
blockieren, aber leider setzt dieser Mechanismus auch beim Auflisten
der Kanäle ein. Abhilfe schafft da nur ein erneuter Connect
(Verbindungaufbau).
Wenn Sie einen eigenen Kanal ins Leben rufen, kommen auch Sie in den Genuß, einmal Operator zu sein. Die Gründung eines Kanals ist denkbar einfach. Sie müssen lediglich den neuen Kanal, beispielsweise 'blafasel', mit '/join #blafasel' aufrufen. In der Liste der Teilnehmer stehen zunächst nur Sie. Wenn Sie sich hier mit Freunden treffen möchten, sollten alle den gleichen IRC-Server verwenden, da neue Kanäle nicht immer auf die anderen Server übertragen werden. Nun können Sie loslegen und Ihren Kanal 'regieren'. Der wichtigste Befehl dabei ist '/mode #Kanal', gefolgt von verschiedenen Parametern. Die Angabe des jeweiligen Kanals ist nur dann nötig, wenn Sie sich nicht in ihm befinden. Ein Pluszeichen vor einem Schalter aktiviert die jeweilige Funktion, ein Minus hebt sie auf. Mit '/mode #blafasel +s' machen Sie 'blafasel' einen geheimen Kanal, der in keiner Liste auftaucht. '/mode #blafasel +b <person>' etwa verbannt jemanden aus dem Kanal. Dabei wird die Person in der Form 'nickname!username@host' angegeben. Wer jetzt glaubt, einen Kanal namens blafasel gäbe es noch nicht, wird enttäuscht - zumindest auf dem Server in München.
Zum Schluß noch eine Warnung: Geben Sie keine Kommandos ein, die Sie nicht kennen. Es gibt nämlich auch die Möglichkeit, innerhalb des IRC Daten zwischen zwei Benutzern zu übertragen oder einem Benutzer gewisse Zugriffsrechte auf dem eigenen Rechner einzuräumen - jedenfalls genügend Möglichkeiten für einen kleinen Schabernack mit einem 'newbie'.
Die deutschen IRC-Server sind miteinander verbunden, Sie sollten sich also immer beim geographisch nächstgelegenen anmelden:
Aachen: irc.informatik.rwth-aachen.de
Berlin: irc.fu-berlin.de
Erlangen: ircserver.informatik.uni-erlangen.de
Kaiserslautern sokrates.informatik.uni.kl.de
Karlsruhe: irc.rz.uni-karlsruhe.de
München: irc.informatik.tu-muenchen.de
Paderborn: irc.uni-paderborn.de
Rostock: irc.informatik.uni-rostock.de
Stuttgart: irc.rus.uni-stuttgart.de
 Erfinder des WWW: Tim Berners-Lee 

|
WWW wurde 1989 im CERN (dem Europäischen Kernforschungszentrum in
Genf, Conseil Européen pur la Récherche Nucléaire) entwickelt,
basierend auf einem System namens Hypertext.
Stellen Sie sich ein Lexikon vor. Sie schlagen einen Begriff nach und
finden dort auch Querverweise auf verwandte Begriffe. Ist das Lexikon
einbändig, müssen Sie nur etwas blättern, um den
angegebenen Querverweis zu finden. Bei einem mehrbändigen
Lexikon müssen Sie unter Umständen einen anderen Band aus
dem Regal nehmen. Handelt es sich beim Querverweis um eine andere
Literaturangabe, ist möglicherweise ein Gang zur Bibliothek
notwendig. 'Hypertext' bedeutet also, daß der Text Querverweise
enthält, die man mit dem Betrachtungsprogramm per Tastendruck
oder Mausklick abrufen kann. Das Hilfesystem von MS-Windows verwendet
ein sehr einfaches Hypertextsystem. Nur geht WWW sehr viel weiter, es
können nicht nur lokale Dateien, sondern Dateien auf
beliebigen Rechnern im Internet als Querverweis angegeben und per
Knopfdruck erreicht werden.
Das Dokument, mit dem die Software des Cern angekündigt wurde,
ist freundlicherweise vom Forschungsinstitut ins Web gestellt
worden (auf's Vorschaubild klicken). |
Aber das WWW ist nicht nur ein weiterer verbesserter Informationsservice wie seine Vorgänger Gopher oder WAIS, sondern es erlaubt auch die Einbindung von Bildern, Sounds oder Animationen in die Hypertext-Dokumente. Das Informationsangebot kann nun multimedial sein. Das hat letztendlich auch zur derzeitigen Popularität des Internet geführt; aber auch dazu, daß leider viele Menschen WWW und Internet gleichsetzen.
WWW ist aber auch der Versuch, die gesamte Information im Internet zusammenzufassen und über ein einziges Benutzerinterface zugänglich zu machen. Für den Benutzer existieren Programme verschiedener Hersteller, 'Browser' genannt, die das WWW verfügbar machen. Die ausgewählten Wörter sind durch Farbe oder Unterstreichung hervorgehoben und können per Mausklick expandiert werden. Damit beginnt die Reise durch das WWW. Auf dieser Reise begegnen Sie unter Umständen recht unterschiedlichen Quellen des Internet (beispielsweise FTP, News, Telnet, Gopher, E-Mail). WWW ist dabei aber höchst flexibel und kann Ihnen sowohl einen FTP-Server als auch einen Telnet-Zugang, einen News-Reader oder weiteres komfortabel präsentieren, so daß es in naher Zukunft für viele Nutzer nur noch ein einziges Werkzeug geben wird, um im Internet zu recherchieren. Die einzelnen Informationsquellen werden durch URLs (URL = Unified Resource Locator) bezeichnet, die den gewählten Dienst und die Datenquelle (Rechner und Datei) angeben (siehe unten).
'Netscape Navigator', 'Internet Explorer', 'Opera', 'Hot Java' sind Programme zum Zugriff auf das WWW mit grafischer Benutzeroberfläche. Es gibt aber auch für einige Systeme textorientierte Browser, z. B. 'LYNX'. Wenn Sie das Programm starten, gelangen Sie automatisch in die 'Homepage' Ihres Systems (bzw. des Systems ihres Providers). Mit 'Homepage' wird normalerweise die Einstiegsseite eines WWW-Servers - oder auch eines Benutzers - bezeichnet. Von dort aus können Sie einfach durch Auswahl eines Querverweises mit der Maus oder den Cursortasten auf weitere Informationsseiten eines beliebigen Internetrechners wechseln, wobei der Verbindungsaufbau automatisch erfolgt. Woher die Information kommt, kann im Browser angezeigt werden. Aber nicht nur durch Unterstreichung und Farbe hervorgehobene Texte können als Link (so nennt man bei WWW die Querverweise) dienen, sondern auch Bilder, beispielsweise kleine Icons. Eine weitere Möglichkeit wird durch sogenannte 'Imagemaps' geboten. Hier kann der Benutzer beliebige Stellen auf einem Bild anklicken. Die Mauskoordinaten werden an den Informations-Server übertragen, und der kann entsprechend reagieren. Bei LEO (http://www.leo.org/) gibt es beispielsweise eine Deutschlandkarte, auf der man den gewünschten Zielort anklicken kann.
Wie Gopher basiert auch WWW auf dem Client-Server-Prinzip. Die Kommunikation erfolgt zwischen einem WWW-Server, der Informationen bereitstellt, und einem Client, der die Informationen anzeigt. Das Protokoll dafür heißt HTTP (HyperText Transfer Protocol). Mitttels dieses Protokolls fordert der Client bei einem Server eine ganz bestimmte Datei mit einem Hypertext-Dokument an, die oft auch als 'WWW-Seite' bezeichnet wird. Diese Datei wird dann vom Server an den Client übertragen und danach die Verbindung wieder geschlossen. Enthält das Dokument Bilder oder andere Multimedia-Teile, werden auch diese Datei für Datei übertragen. Weder Server noch Client 'merken' sich die Tatsache der Kommunikation (es gibt höchstens einen Eintrag in eine Protokolldatei auf dem Server). So ist jede Informationsanforderung ein abgeschlossener Vorgang. Etliche Browser können für ein Dokument, das aus mehreren Dateien besteht, auch mehrere Übertragungen parallel öffnen. Bilder bauen sich dann z. B. simultan auf. Dadurch wird aber auch die Belastung des Netzes erhöht. Damit Seiten, die öfter aufgerufen werden, nicht immer über das Netz transportiert werden müssen, können die meisten Browser WWW-Seiten lokal zwischenspeichern (Cache-Speicherung). Es erfolgt dann nur eine kurze Anfrage an den Server, ob sich die entsprechende Information seit dem letzten Zugriff geändert hat. Ist dies nicht der Fall, werden die Daten lokal von der Platte geholt. Die größeren Provider und Uni-Rechenzentren unterhalten ebenfalls ein Cache-System. Wenn ein Benutzer eine WWW-Seite anfordert, wird die Info auf der Platte des Providers zwischengespeichert. Bei der Anfrage eines weiteren Benutzers nach derselben Seite innerhalb eines bestimmten Zeitraums wird die lokale Kopie zur Verfügung gestellt ('Proxy-Cache', 'Proxy-Server'). Die Proxy-Software überprüft regelmäßig, ob sich die lokal gespeicherten Infos eventuell geändert haben und aktualisiert sie gegebenenfalls. Nicht mehr gefragte Seiten werden nach einiger Zeit gelöscht.
Die Browser selbst brauchen natürlich die Fähigkeit, nicht nur Text schön darzustellen, sondern auch Bilder anzuzeigen oder Töne abzuspielen. Für die gebräuchlichsten Dateiformate im WWW sind die entsprechenden Darstellungsprogramme im Browser integriert (z. B. für die Bildformate GIF und JPEG oder die Audioformate AU und WAV). Für andere Bildformate kann man dem Browser in einer Konfigurationsdatei mitteilen, welche externen Programme für bestimmte Dateiformate aufzurufen sind. Auf diese Weise kann man den Browser für beliebige Datenformate fit machen. Teilweise liefern auch schon die Browser-Hersteller solche Programme mit. Besinders komfortabel sind Programmen, die sich automatisch in den Browser einklinken (sogenannte 'Plug-In'-Programme) Die Angabe des Anzeigeprogramms kann sogar interaktiv erfolgen. Stößt der Browser auf ein unbekanntes Dateiformat, wird der Benutzer gefragt, ob er ein Anzeigeprogramm angeben möchte oder ob die Datei für später auf der Platte gespeichert werden soll. In diesem Zusammenhang noch ein Hinweis: Alles was man beim Surfen im WWW auf dem Bildschirm sieht, ist in den lokalen Rechner übertragen worden und kann natürlich auch dauerhaft abgespeichert werden (File-Menü des Browsers, Menüpunkt 'Save as...'). Ebenso lassen sich die Bilder abspeichern (beim Netscape-Browser Mauszeiger auf das Bild ziehen, rechte Maustaste drücken).
Eigentlich ist das, was der Browser auf dem Bildschirm zeigt, die Wiedergabe einer Textdatei, die bestimmte Strukturierungsmerkmale enthält (probieren Sie mal den Menüpunkt 'view source' Ihres Browsers aus). Die Definitionssprache für solche Hypertext-Dokumente ist recht einfach, sie heißt HTML (HyperText Markup Language). HTML besteht aus normalem Text, bei dem Steueranweisungen, sogenannte HTML-'Tags', in den Text eingefügt werden. Diese Tags beeinflussen das Schriftbild, das später im Betrachtungsprogramm angezeigt wird; so gibt es zum Beispiel Tags, die einen Text als Überschrift kennzeichnen, oder Tags, die das Schriftbild verändern können. die Tags werden immer in '<' und '>' eingeschlossen. Mit nur wenigen Tags lassen sich schon sehr ansprechende Dokumente erstellen (siehe Kapitel 4).
Damit sind wir bei einem sehr wichtigen Punkt angelangt. HTML beschreibt die Struktur eines Dokuments, nicht dessen Aussehen! Denn der Informationsanbieter kann ja nicht wissen, ob der Leser seine Infos mit einem grafischen oder textorientierten Browser liest. Auch Bildschirmauflösung des Client-Computers, aktuelle Größe des Browser-Fensters, Farb- und Schriftwahl des Benutzers spielen eine Rolle. Manchen Benutzer schalten die Darstellung der Bilder ab, um Übertragungszeit zu sparen. All das sollte der Anbieter berücksichtigen (manche tun es, manche nicht). HTML ist eben kein Desktop-Publishing, sondern eine Struktursprache.
Wie kommt man zu interessanten Informationen? Es gibt drei Möglichkeiten:
1. Durch Empfehlung von Bekannten (Es können auch Informationen aus den News sein). Jemand sagt also zu Ihnen: "Probiere mal: http://www.fh-muenchen.de/". Das tippen Sie dann ins Adreßfenster des Browsers, und schon landen Sie auf dem entsprechenden Computer, der Ihnen die gewünschte Information serviert.
2. Durch Netsurfen. Sie starten einfach irgendwo. Klicken Sie auf eines der Links, und Sie werden auf einem Server irgendwo in der großen weiten Welt landen. Die Chance ist groß, daß diese Web-Seite weitere Links enthält und so werden Sie von von Australien bis Japan springen und dabei ein paar interessante Dinge entdecken (und, falls Sie Ihr Datenvolumen bezahlen müssen, den nächsten Monat nicht mehr Netsurfen).
3. Durch Suchen. Ähnlich wie bei Gopher gibt es etliche Server, die mit Suchmaschinen einen Index vieler, vieler WWW-Server anlegen. In diesem Index kann man dann nach Stichworten suchen. Im Anhang sind einige Suchsysteme aufgelistet.
Oft hat man schon eine recht große Anzahl an Bildschirmen und WWW-Schritten hinter sich, bis man an der gewünschten Stelle oder interessanter Information angekommen ist. Um sich einen relativ langen oder umständlichen Weg bis zu dieser Stelle ein zweites Mal zu ersparen, kann man solche Stellen im WWW in der persönlichen 'Hotlist' eintragen.
Ein weiteres Merkmal des WWW ist die Schreiboption. Damit ist es möglich, Formulare, z. B. Bestellscheine von Bibliotheken oder Anmeldungen für Konferenzen, auszufüllen und abzuschicken. Diese Formulare werden dann von Programmen auf dem Server-Rechner bearbeitet. Diese schicken dann die Antwort wieder als WWW-Dokument zurück.
Protokoll://Rechneradresse:Port/Dateipfad/Dateiname
Ein URL besteht also aus vier Teilen, wobei nicht immer alle Teile aufgeführt werden müssen (meist ist z. B. keine Portangabe nötig). Beim Gopher-Protokoll wird statt Pfad- und Dateiname der Menütyp (01 fürs Startmenü) und ein Pfad angegeben. Das Protokoll gibt an, welcher Dienst genutzt werden soll, hier sind gebräuchlich:
Die Portangabe hat einen sehr technischen Hintergrund. Um die einzelnen Dienste zu unterscheiden, wird beim TCP/IP-Protokoll (vereinfacht gesagt) jedem Dienst eine Nummer zugewiesen, eben die Port-Nummer. Es gibt allgemein festgelegte Ports, z. B. 80 für das http-Protokoll. Solche Standard-Ports müssen nicht angegeben werden. Man kann aber auch unbelegte Portnummern verwenden, beispielsweise um einen modifizierten WWW-Dienst anzubieten. In diesem Fall muß dann die Portnummer angegeben werden.
Sie sehen, ein URL ist ein nützliches Instrument, um Informationsquellen im Netz eindeutig zu bezeichnen. Inzwischen wird die Form der URL-Schreibweise nicht nur in WWW-Dokumenten, sonder auch ganz allgemein verwendet, um auf eine Ressource hinzuweisen, z. B. in einer E-Mail.
ping Rechnername
kann man den fernen Rechner 'anklingeln'. Je nach Programmversion erhält
man nur die Meldung
Rechnername is alive
wenn alles in Ordnung ist - oder eine der Fehlermeldungen 'no answer',
'unknown host' oder 'network unreachable'.
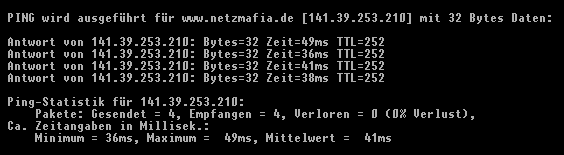
Bei anderen Versionen (oder durch Angabe des Parameters -s) erhält man für jedes Datenpaket eine Meldung. Das Kommando kann dann mit Ctrl-C abgebrochen werden, worauf eine Statistik ausgegeben und das Kommando beendet wird. Bei grafischen Benutzerschnittstellen erfolgt die Parameterangabe über Dialogfelder und nicht in der Kommandozeile.
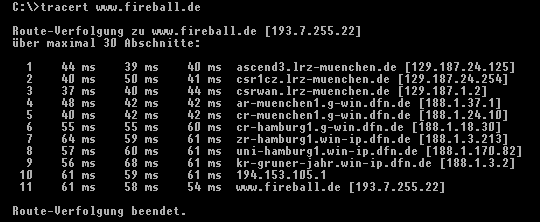
Zähler Gateway-Name Gateway-IP-Nummer "round-trip"-Zeit (3 Werte)Traceroute sendet jeweils drei Datenpakete. Wenn auf ein Paket keine Antwort erfolgt, wird ein Sternchen (*) ausgegeben. Ist ein Gateway nicht erreichbar, wird statt einer Zeitangabe '!N' (network unreachable) oder '!H' (host unreachable) ausgegeben. Man kann so feststellen, wo eine Verbindung unterbrochen ist, und auch, welchen Weg die Daten nehmen - wo also der Zielrechner in etwa steht. Bei grafischen Benutzerschnittstellen erfolgt die Parameterangabe über Dialogfelder und nicht in der Kommandozeile.
whois Namensangabe
wenn der voreingestellte Server verwendet wird. Mit Serverangabe lautet
das Kommando:
whois -h Serverrechner Namensangabe
Man erhält dann alle Angaben aus der Datenbank, die zur Namensangabe
passen. Als Namensangabe kann entweder ein Userpseudonym (Login-Name)
oder der "echte" Name, eventuell als 'Nachname, Vorname', angegeben
werden. Bei grafischen Benutzerschnittstellen erfolgt die Parameterangabe
über Dialogfelder und nicht in der Kommandozeile.
Die Entwicklung der WWW-Browser schritt in den letzten Jahren rasant voran. Was mit der einfachen Darstellung von Texten mit der Einbindung von Multimedia-Elementen begann, entwickelt sich heute in Richtung 'virtuelle Realität' mit dreidimensionalen Darstellungen, Animationen und mehr.
Für Java-Code, der in einem
Web-Browser ablaufen soll, dient die Klasse 'Applet' als
Ausgangspunkt. Im HTML-Code werden die Java-Klassen durch das
<applet>-Tag eingebettet. 'Applet' definiert als Superklasse
für alle Applikationen, die in Browser eingebettet werden
sollen, auch einen Eventhandler für Benutzereingaben. Die
wichtigsten Methoden für ein Applets sind die Initialisierung,
Aktivierung der Anzeige, Deaktivierung der Anzeige und das
Terminieren. Der Programmierer definiert in diesen Methoden das
Verhalten des Applets auf der Seite. Gemäß dem
'Java-Knigge' sind Applets so zu programmieren, daß sie nur
dann Rechenzeit beanspruchen, wenn die umgebende HTML-Seite angezeigt
wird. Mit Java lassen sich auch komplette Bedienoberflächen
programmieren. Die Möglichkeit, mit einem Mausklick ein Applet
zu stoppen und wieder anzustarten, runden die Vorschriften ab. Um
nicht den Browser mit der Interpretation des Applets zu blockieren
und auch mehrere Applets simultan in einer HTML-Seite animieren
zu können, sind Threads bereits Grundausstattung der
Java-Laufzeitumgebung.
Wer sich für Java interessiert, findet Java-Seiten mit vielen Demos,
den HotJava-Browser (für SUNs) und Java-Entwicklersoftware auf
dem Server von SUN Microsystems unter http://java.sun.com/.
Die Entwicklertools für Java-Applikationen stecken noch in den
Kinderschuhen und sind zwar mächtig in der Leistung, aber noch
recht unkomfortabel in der Bedienung.
Um nicht bei Null zu beginnen und statt dessen eine geeignete, bereits vorhandene 3D-Technologie zu nutzen, fiel die Wahl der Entwickler auf 'Open Inventor' von Silicon Graphics (SGI). Open Inventor unterstützt 3D-Szenarien mit Polygonobjekten, verschiedenen Belichtungsmöglichkeiten, Materialien oder Texturen. Zudem stellte SGI noch eine erste VRML-Parser-Library zur Verfügung, die als Grundlage für die Implementierung von 3D-Viewern diente.
 Zum Inhaltsverzeichnis
Zum Inhaltsverzeichnis
 Zum nächsten Abschnitt
Zum nächsten Abschnitt