 |
DatenkommunikationProf. Jürgen Plate |
|
DatenkommunikationProf. Jürgen Plate |
Nachricht:
Zusammenstellung von Symbolen (Zeichen) zur
Informationsübermittlung.
Symbol:
Element eines Symbol- oder Zeichenvorrates. Dieser Vorrat ist
eine festgelegte endliche Menge von verschiedenen Symbolen (=
Elemente der Menge). Der Unterschied zwischen Symbol und Zeichen
ist recht subtil. Ein Symbol ist ein Zeichen mit bestimmter
Bedeutung.
Alphabet:
Ein geordneter Vorrat von Symbolen.
Wort:
Folge von "zusammengehörigen" Zeichen, die in einem
bestimmten Zusammenhang als Einheit betrachtet werden.
Beispiel:
Alphabet: A,B,C,D,E,F,...,X,Y,Z
Wort: DONALD
Nachricht: DONALD SUCHT DAISY
Hier noch einige Beispiele:

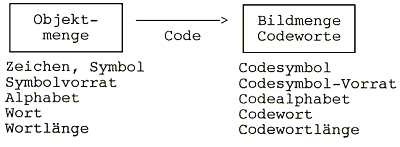
Häufig wird mit "Code" auch nur die Bildmenge bezeichnet.

Wie gesagt: Zweck der Codierung ist die Anpassung der Nachricht an technische Systeme (z. B. Morsecode). Die Codierung ändert nur die Darstellungsform einer Nachricht, nicht ihre Bedeutung.
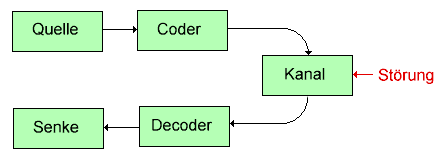
Hier werden nur Binärcodes behandelt. Die Symbole des Codealphabets sind die Binärzeichen {0,1}, Die Codeworte sind Binärworte --> Dualzahlen stellen einen Binärcode dar. Binärcodes spielen in der Technik eine besonders wichtige Rolle.
Beispiele binärer Zeichenvorräte:
| Intensität | hell | dunkel |
| Zahlen | 1 | 0 |
| Zustände | gelocht | ungelocht |
| Wahrheitswerte | wahr | falsch |
| Spannungen | 5 Volt | 0 Volt |
| Ströme | 20 mA | 0 mA |
Zur Codierung von M Zeichen sind also Codeworte der Länge
n = (ganze Zahl >= ld (M))
nötig. Ist M keine Zweierpotenz, können mehr Codeworte gebildet werden. Die nicht verwendeten Codeworte heißen Pseudowörter --> Redundanz. Die Codewortlänge wird oft als Coderahmen bezeichnet.
Es gibt auch Codes, bei denen die Codewortlänge kleiner als ld(M) ist. Die Codeworte sind dann doppelt belegt und Umschaltzeichen ordnen den nachfolgenden Codeworten die Belegung zu (z. B. Telegraphenalphabet CCITT Nr. 2: n = 5, Umschaltung Buchstaben/Ziffern und Sonderzeichen).
Gründe für die Codierung:
Die Forderungen werden aus den o.g. Gründen abgeleitet, was zum Teil auch wiedersprüchliche Merkmale nach sich zieht --> ein für alle Zwecke optimaler Code existiert nicht --> Anwendung mehrerer Codes in einem System (DV-System) nicht ungewöhnlich --> Umcodie- rung notwendig.
Beispiele für Codeeigenschaften (Forderungen):
Der Dualcode ist ein reiner Binärcode, der der Zahlendarstellung im Dualsystem entspricht --> wortorganisierte binäre Codierung, einfache Arithmetik, Umcodierung bei Ein-/Ausgabe oder Übertragung relativ schwierig.
Von den insgesamt 16 Tetraden werden nur 10 Nutztetraden benötigt --> 6 Pseudotetraden. Die Aufteilung der 16 Tetraden in Nutz- und Pseudotetraden führt zu verschiedenen tetradischen Codes. In der Digitaltechnik haben nur einige Möglichkeiten Bedeutung gewonnen.
Ein Code mit dem Coderahmen (Wortlänge) n, dessen Nutzwörter alle m 1-Bits besitzen heißt m-aus-n-Code. Beispiele:
Nebenbemerkung: Kettencodes sind n-Bit-Codes, bei denen über eine zyklische Anordnung von maximal 2n Bits ein Ablesefenster verschoben wird, das n aufeinanderfolgende Bits herausgreift. Für n=3 ist das z. B. mit der folgenden Anordnung von 8 Bits möglich:
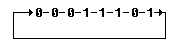
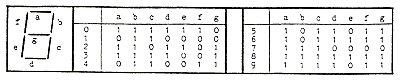
10 Ziffern, 26 Buchstaben, 10 Sonderzeichen --> 46 Zeichen --> 6 Bit Wortlänge
binär |
0000 |
0001 |
0010 |
0011 |
0100 |
0101 |
0110 |
0111 |
0000 |
NUL |
DLE |
|
0 |
@ |
P |
` |
p |
0001 |
SOH |
DC1 |
! |
1 |
A |
Q |
a |
q |
0010 |
STX |
DC2 |
" |
2 |
B |
R |
b |
r |
0011 |
ETX |
DC3 |
# |
3 |
C |
S |
c |
s |
0100 |
EOT |
DC4 |
$ |
4 |
D |
T |
d |
t |
0101 |
ENQ |
NAK |
% |
5 |
E |
U |
e |
u |
0110 |
ACK |
SYN |
& |
6 |
F |
V |
f |
v |
0111 |
BEL |
ETB |
' |
7 |
G |
W |
g |
w |
1000 |
BS |
CAN |
( |
8 |
H |
X |
h |
x |
1001 |
HT |
EM |
) |
9 |
I |
Y |
i |
y |
1010 |
LF |
SUB |
* |
: |
J |
Z |
j |
z |
1011 |
VT |
ESC |
+ |
; |
K |
[ |
k |
{ |
1100 |
FF |
FS |
, |
< |
L |
\ |
l |
| |
1101 |
CR |
GS |
- |
= |
M |
] |
m |
} |
1110 |
SO |
RS |
. |
> |
N |
^ |
n |
~ |
1111 |
SI |
US |
/ |
? |
O |
_ |
o |
DEL |
Die Kodierung eines Zeichens erhält man dadurch, daß Zeilenwert hinter Spaltenwert geschrieben wird, z. B. 'A' = 0100 0001 binär = 41 hexadezimal.
Abkürzungen der Steuer- und Sonderzeichen:
| ACK | acknowledge - positive Rückmeldung |
|---|---|
| BEL | bell - Klingel |
| BS | backspace - Rückwärtschritt |
| CAN | cancel - ungültig, Abbruch |
| CR | carriage return - Wagenrücklauf |
| DCi | device control i - Gerätesteuerung i |
| DEL | delete - löschen, Entfernen |
| DLE | data link escape - Datenübertragungsumschaltung |
| EM | end of medium - Ende der Aufzeichnung |
| ENQ | enquiry - Stationsaufforderung, Anfrage |
| EOT | end of transmission - Ende der Übertragung |
| ESC | escape - Umschaltung |
| ETB | end of transmission block - Ende des Datenübertragungsblocks |
| ETX | end of text - Ende des Textes |
| FF | form feed -Formularvorschub |
| FS | file seperator - Hauptgruppentrenner |
| GS | group seperator - Gruppentrenner |
| HT | horizontal tabulation - Horizontaltabulator |
| LC | lower case - untere Stellung, Kleinbuchstaben |
| LF | line feed - Zeilenvorschub |
| NAK | negative acknowlegde - negative Rückmeldung |
| NL | new line - neue Zeile |
| NUL | nil - Null (Füllzeichen ohne Einfluß auf Zeicheninhalt) |
| RS | record seperator - Untergruppentrenner |
| SI | shift in - Rückschaltung in Standardcode |
| SO | shift out - Dauerumschaltung in andere Codetabellen |
| SOH | start of heading - Anfang des Kopfes |
| STX | Start of text - Anfang den Textes |
| SUB | substitution - Austausch eines Zeichens |
| SYN | synchronous idle - Synchronisationslauf |
| UC | upper case - obere Stellung, Großbuchstaben |
| US | unit seperator - Teilgruppentrenner |
| VT | vertical tabulation - Vertikaltabulator |
In einem fernen Land lebte vor langer, langer Zeit ein kleiner König, der war dick faul und unzufrieden und wollte den lieben langen Tag immer nur essen. Wir wollen hier nur seine Nahrungs- gewohnheiten betrachten - insbesondere, da seine Ernährung recht einseitig war. Den lieben langen Tag aß er nur:
(1) Schweinebraten,
(2) Schokoladenpudding,
(3) Essiggurken,
(4) Erdbeertorte.
Zudem war der König sehr maulfaul und mit der Zeit wurde es ihm sogar zu anstrengend, seine Bestellungen aufzugeben (die er sowieso im Telegrammstil kundtat: "Braten, Torte, Gurken"). Eines Tages beschloß er, eine Codierung zu entwickeln, mit der er seine Befehle auch loswurde, ohne den Mund aufzutun. Durch Zufall wurde es sogar eine Binärcodierung:
Die rechte Hand ein wenig heben heiße: Schweinebraten Die linke Hand etwas heben heiße: Schokopudding Erst die rechte und dann die linke Hand heben: Gurken Zweimal nacheinander die rechte Hand heben: Erdbeertorte
Der Übersichtlichkeit halber wollen wir die Codierung etwas abkürzen. "R" steht für "rechte Hand heben" und "L" für "linke Hand heben". Dann ergibt sich folgende Codezuordnung:
R Braten
L Pudding
RL Gurken
RR Torte
Und schon gab es Probleme. Angenommen der König hob dreimal die rechte Hand (--> RRR). Dann konnte dies bedeuten:
Braten, Braten, Braten oder
Braten, Torte oder
Torte, Braten
Nun mußte der König einmal wirklich viel reden. Er rief seinen Hofmathematikus zu sich und erklärte den Sachverhalt. "Hmmmm" überlegte dieser: "Majestät haben Höchstdero Speisewünsche binär codiert. Vorzüglich, Vorzüglich." "Aber es klappt nicht", raunzte der König,"jedesmal, wenn ich Schweinebraten und Pudding will, bringen diese Hornochsen mir Gurken!" und er sank erschöpft auf seinen Thron zurück. "Mit Verlaub, die Codierung ist nicht ein- deutig, Majestät", wagte der Mathematikus einzuwerfen. "Ich weiß!
Laß Dir gefälligst was einfallen!" grunzte der König. Und vor lauter Angst, wieder etwas Falsches zu bekommen, brüllte er: "Braten und Torte, aber fix!".
Der Mathematiker brütete inzwischen über eine eindeutige binäre Codierung nach und gelangte zu folgenden Überlegungen:
Braten RR
Pudding RL
Gurken LR
Torte LL
Nun war die Codierung unverwechselbar. Die Zeichenfolge "LRRLLLRRRRLL" konnte nur noch bedeuten: Gurken, Pudding, Torte, 2 x Braten, Torte.
Zwar war die Codierung eindeutig, aber war sie auch optimal? Bisher wurde davon ausgegangen, daß der König keine spezielle Vorliebe für bestimmte Gerichte hat (alle Codewörter sind gleich wahrscheinlich). Zudem beschwerte sich der König schon nach kurzer Zeit darüber, daß er viel zu häufig die Hände heben müsse.
Also vergatterte der Mathematikus seinen Assistenten, eine Statistik der königlichen Essenswünsche aufzustellen. Heraus kam folgendes. Jeden Tag verspeiste der König im Schnitt 18 Gerichte.
Die Häufigkeitsverteilung stellte sich so dar:
9 x Schweinebraten,
6 x Schokopudding,
1 x Gurken,
2 x Erdbeertorte.
Soll die Codierung optimal, also eindeutig und zweckmäßig sein, mußte der Matehmatikus versuchen, für den Braten einen möglichst
kurzen Code zu wählen. Dafür darf der Code für eine Grurkenbestellung ruhig länger sein. Also legte er erst einmal fest:
Braten --> R
Damit ist das "R" 'verbraucht', denn es darf wegen der Eindeutigkeit kein Codewort mehr mit "R" beginnen (Fano-Bedingung: Kein Code darf der Beginn eines anderen verwendeten Codes sein). Weiter geht es mit:
Pudding --> LR
Es bleibt somit noch ein zweistelliges Codewort übrig (LL, denn RR und RL sind wegen der Fano-Bedingung 'verboten'), aber es sind noch zwei Speisewünsche zu codieren. Also müssen die nächsten Codes dreistellig sein. Unter Beachtung der Eindeutigkeit ergibt sich:
Torte --> LLR Gurken --> LLL
wahlweise auch:
Torte --> LLL Gurken --> LLR
Ist diese Codierung nun wirklich besser, d. h. kürzer? Beim alten Code benötigte der König für 18 Gerichte 36 bit. Nun sieht es bei der oben genannten Häufigkeitsverteilung folgendermaßen aus:
9 x Schweinebraten 9 bit
6 x Schokopudding 12 bit
1 x Gurken 3 bit
2 x Erdbeertorte 6 bit
---------
Summe 30 bit
Es wurden also durchschnittlich 6 bit pro Tag gespart. Probieren
wir zum Schluß der Geschichte aus, ob es klappt. Was will der
König bei "LRRRLLR"? Da die Codewortlänge variiert, muß man
schrittweise vorgehen. Das erste "L" bedeutet noch nichts. "LR"
heißt eideutig "Pudding". Dann kommt "R" für "Braten"
und gleich noch einer. Wieder ein "L", das noch nichts besagt. Auch das
folgende "L" liefert noch keine Lösung. Erst das letzte "R"
gibt Aufschluß: "Torte!".
Führt eine n-malige Verwirklichung der geforderten Bedingung in m Fällen zum zufälligen Ereignis A, dann liegt die Häufigkeit h(A) = m/n beliebig nahe an der Wahrscheinlichkeit P(A).
Jetzt können wir die Ergebnisse unseres Märchens aufarbeiten. An der königlichen Tafel sind vier zufällige Ereignisse bedeutsam:
A1: Der König bestellt Braten A2: Der König bestellt Pudding A3: Der König bestellt Torte A4: Der König bestellt GurkenAuch die Häufigkeiten sind bekannt. Wir nehmen an, daß die Werte auf genügend vielen Beobachtungen beruhen. Also können wir die Wahrscheinlichkeiten durch die Häufigkeiten annähern:
P(A1) = 9/18 = 1/2 P(A2) = 6/18 = 1/3 P(A3) = 2/18 = 1/9 P(A4) = 1/18 = 1/18Die Summe aller Wahrscheinlichkeiten P(A1) + P(A2) + P(A3) + P(A4) ergibt immer den Wert 1. Betrachten wir nun den König als Nachrichtenquelle. Seine Nachrichten sind A1, A2, A3 und A4. Die oben erwähnten Wahrscheinlichkeiten stellen zusammen mit den zugehörigen Nachrichten das Bild einer (sehr abstrakten) Nachrichtenquelle dar. Die Nachricht A1 hat eine relativ hohe, die Nachricht A4 eine relativ geringe Wahrscheinlichkeit. Mit anderen Worten: A1 dürfte in einer Nachrichtenfolge öfter auftauchen als A4 (wobei nichts über die Position von A1 ausgesagt werden kann). Damit können wir auch den Informationsgehalt definieren:
Je kleiner die Wahrscheinlichkeit des Auftretens einer Nachricht ist, desto höher ist ihr Informationsgehalt. Als Formel:
I(A) = ld( 1/P(A) ) [bit]Wenden wir nun diese Formel auf die Nachrichten A1 bis A4 an:
I(A1) = ld( 1/(1/2) ) = ld(2) = 1,000 bit I(A2) = ld( 1/(1/3) ) = ld(3) = 1,585 bit I(A3) = ld( 1/(1/9) ) = ld(9) = 3,170 bit I(A4) = ld( 1/(1/18) ) = ld(18) = 4,170 bitNun besitzen wir präzise Zahlenwerte über den Informationsgehalt der einzelnen Nachrichten. Das Maß für die Unsicherheit darüber, welche Nachricht nun als nächste in einer Folge kommt, ist die "mittlere Information" (oder Entropie) H:
H(A1, ..., An) = Summe(P(Ai) * ld(1/P(Ai))) für i=1 ... nFür unser Königs-Ernährungsproblem ergibt sich:
H = 1,000/2 + 1,585/3 + 3,170/9 + 4,170/18 = 1,614 bitDieser Wert sagt uns aber noch nicht viel; wir brauchen Vergleichswerte. Betrachten wir nun die binär codierten Essenswünsche, die ja nur noch aus den Zeichen "R" und "L" bestehen. Zunächst die erste Codierung mit jeweils zwei bit für jedes Codewort (man schreibe einfach die Codes entsprechend obiger Häufigkeiten auf und zähle die "R"s und "L"s):
P(R) = 25/36 --> H1(R,L) = 0,883 bit P(L) = 11/36Nun sehen wir uns die optimierte Codierung mit unterschiedlicher Länge der Codeworte an:
P(R) = 17/30 --> H2(R,L) = 0,988 bit P(L) = 13/30Also trägt hier jedes Signal mehr Information.
Es läßt sich aber für eine bestimmte aufgabe ein Code finden, für den H beliebig nahe an m liegt. Zur Informationstheoretischen Beurteilung der Eigenschaften von Codes dient die Redundanz:
absolute Redundanz relative Redundanz:
R = m - H r = (m - H)/m = R/m
Wie sieht das für unseren stets hungrigen König aus?
(1) Code mit fester Wortlänge 2:
H = 1,614 bit R = 2 - 1,614 = 0,386 m = 2 bit r = 0,386/2 = 0,193 = 19,3%
(2) Code mit variabler Wortlänge:
H = 1,614 bit R = 1,722 - 1,614 = 0,108 m = 1,722 bit r = 0,108/1,722 = 0,063 = 6,3%
Fassen wir zusammen. Das Shannonsche Codierungstheorem besagt:
Die zweite Behauptung impliziert auch, daß es nicht den optimalen Code gibt, sondern nur einen relativ besten.
Wir haben gesehen, daß Codes redundant sein können. Formelmäßig läßt sich das Maß für die Redundanz eines Codes allgemein folgendermaßen festlegen:
absolute Redundanz relative Redundanz: R = m - H r = (m - H)/m = R/mm = mittlere Codewortlänge H = Informationsgehalt
Sind alle Codewörter gleich lang, gilt:
absolute Redundanz relative Redundanz:
R = ld(M) - ld(n) r = (ld(M) - ld(n))/ld(M)
= R/ld(M)
M = Anzahl der möglichen Codewörter
n = Anzahl der verwendeten Codewörter
Beispiel: tetradische Codes (Darstellung der Ziffern 0 bis 9) Der Informationsgehalt I = ld(10) ist 3,32 bit. Wir müssen also Codeworte von 4 bit Länge verwenden. Mit 4 bit können jedoch 16 Codeworte dargestellt werden, wir haben also 10 Nutzbits und 6 Pseudoworte. Die Redundanz ergibt sich zu: Rc = 4 - ld(10) = 4 - 3,32 = 0,68 und rc = 0,68 / 4 = 0,17 --> 17%.
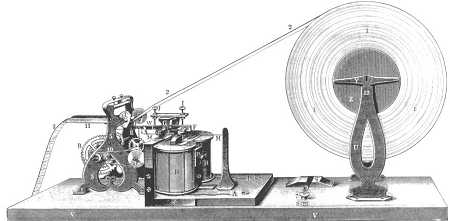
Der Morsetelegraph hatte einen dreiwertigen Code (Punkt, Strick, Leerraum) und variable Codelänge
Verfahren zur Datenreduktion wurden von Shannon, Fano und Huffman entwickelt. Nehmen wir z. B. die Huffman-Codierung. Sie generiert anhand der Häufigkeiten einen optimalen Code:
Dazu ein Beispiel: In einem Text werden die Buchstaben gezählt. Es ergeben sich folgende Häufigkeiten:
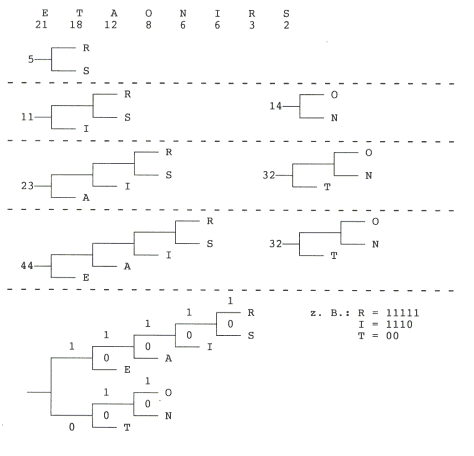
1728 * 290 * 3,85 = 1929312 bit
Bei einer Datenübertragungsrate von 9600 bit/s dauert das Senden einer Seite ca. 200 s = 3 Minuten, 20 Sekunden. Da eine normale Schreibmaschinenseite überwiegend weiß ist, haben die Daten sicher hohe Redundanz. Bei einem Schwarzanzeil von 5% ergibt sich z. B. ein Informationsgehalt von:
H = 0,05 * ld(1/0,05) + 0,95 * ld(1/0,95)
= 0,216 + 0,07 = 0,286
Für die Datenreduktion werden die Bildpunkte einer Zeile zusam- mengefaßt, denn eine Bildzeile besteht abwechselnd aus weißen und schwarzen Feldern unterschiedlicher Länge. Nun werden nicht mehr die einzelnen Bildpunkte codiert übertragen, sondern nur noch ein Code für die Anzahl, beispielsweise 10w, 30s, 123w, 2s, 67w, ... Das Ganze nennt sich dann "Lauflängencodierung" (run length encoding). Für jede Anzahl weißer und schwarzer Bildpunkte wird nun ein optimales (Binär-)Codewort ermittelt und übertragen.
Da nun jede Vorlage einen anderen Schwarzanteil besitzt, müßte man für jede Seite eine optimale Codierung ermitteln und diesen Code an die Gegenstation senden. Dieses Vorgehen ist sicher nicht praktikabel. Daher untersucht man eine repräsentative Auswahl von Vorlagen ("Standardseiten") und ermittelt für diese einen optimalen Code. Dieser Code wird dann für alle Telefax-Übertragungen verwendet. In der Realität ist das noch komplizierter, da die Lauflängen nach einen bestimmten Schema codiert werden. Insgesamt ergibt sich jedoch - je nach Vorlage - eine Datenreduktion auf 5 bis 20 Prozent des ursürünglichen Volumens.
Die Störung muß groß genug sein, um die physikalische Repräsentation umzukehren. Ja nach Repräsentation ist das nur schwer möglich (Vorteil gegenüber der Analogtechnik). Die "Stärke" der Störung wird durch die Bitfehler-Wahrscheinlichkeit ausgedrückt. Eine Bitfehlerwahrscheinlichkeit von z. B. 0,00001 bedeutet, daß auf 10000 übertragene Bits eines verfälscht ist. Die Bitfehlerwahrscheinlichkeit von 0 ist die theoretische Grenze und mit endlichem Aufwand nicht erreichbar. Für ISDN-Leitungen der Telekom wird beispielsweise eine Bitfehlerwahrscheinlichkeit von 10-7 für sogenannte Dauerwählverbindungen angegeben.
Aufgabe der Codesicherung ist es, die Bitfehler in Codewörtern oder Codewort-Blöcken zu erkennen oder zu beseitigen. Fehlererkennung ist nur möglich, wenn durch Bitfehler ungültige Codeworte entstehen (= Codeworte, die nicht im Codewort-Vorrat definiert sind). Bitfehler die ein Codewort in ein anderes gültiges Codewort verfälschen sind nicht erkennbar.
Beispiel: 5-4-2-1-Code:
0 1 0 1 (= 5) 0 1 0 1 (= 5)
| |
1 1 0 1 (Pseudotetrade) 0 1 0 0 (= 4)
--> Fehler erkannt --> Fehler nicht erkannt
Grundsätzlich gilt: Codewörter ohne Zeichenzuornung müssen vorhanden
sein --> Code muß redundant sein.
Beispiel: tetradische Codes:
m = 4 Rc = 4 - ld(10) = 4 - 3,32 = 0,68 M = 10 rc = 0,68 / 4 = 0,17 --> 17%Die Redundanz stellt aber die Sicherheit gegen Übertragungsfehler noch nicht her. Codes gleicher Redundanz können unterschiedlich übertragungssicher sein.
Beispiel: 2-aus-5-Walking-Code <--> Libway-Craig-Code Für beide gilt: m = 5, M = 10, Rc = 1,68, rc = 33,6%
Beim 2-aus-5-Walking-Code führt jede Verfälschung nur eines Bits zu einem fehlerhaften Codewort. Beim Libway-Craig-Code kann ein 1-Bit-Fehler zu einem gültigen Codewort führen.
Das unterschiedliche Verhalten der beiden Codes ist darauf zurückzuführen, daß sich zwei beliebige Codeworte beim 2-aus-5-Walking-Code in mindestens zwei Stellen voneinander unterscheiden und beim Libway-Craig-Code nur ein Bit Unterschied besteht.
Distanz: (Stellendistanz)
Anzahl von Stellen, in denen sich zwei gültige Codeworte eines Codes voneinander
unterscheiden: 1 %lt;= d < m
Hammingdistanz:
Die Mindestzahl der Stellen, in denen sich jedes gültige Codewort
eines Codes von jedem anderen unterscheidet: h = dmin
Für das obige Beispiel zeigt sich:
2-aus-5-Walking-Code: h = 2 Libway-Craig-Code: h = 1
Erst bei h = 2 werden 1-Bit-Fehler sicher erkannt. Bei tetradischen Codes mit h = 1 können solche Fehler nur teilweise erkannt werden. Sollen mehr als ein Bitfehler erkannt werden oder Fehler korrigiert werden, so muß die Hamming-Distanz erhöht werden.
e = h - 1
Beispiel: Der Code besteht aus den Codeworten 0000 und 1111.
1111 \__________Störung_____________ 1110 1 Fehler
0000 / 1001 2 Fehler
1000 3 Fehler
h = 4 --> e = h - 1 = 3
Welche Möglichkeiten bieten sich?
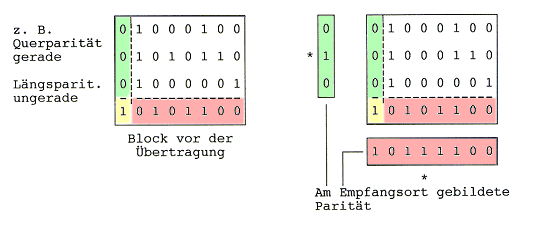
Die Erweiterung des Codewortes um ein Paritätsbit wird auch "Querparität" oder "Zeichenparität" genannt. Die Überprüfung der empfangenen Codeworte kann durch Bildung der Quersumme (Addition modulo 2, d.h. ohne Berücksichtigung des Übertrags) erfolgen. Jede ungeradzahlige Anzahl von 1-Bit-Fehlern im Codewort wird erkannt, geradzahlige Bitfehlerzahl wird nicht erkannt.
Beispiel "ASCII", gerade Parität:
A 1 0 0 0 0 0 1
S 1 0 1 0 0 1 1
C 1 0 0 0 0 1 1
I 1 0 0 1 0 0 1
I 1 0 0 1 0 0 1
-----------------------
Parity: 1 0 1 0 0 0 1
Beispiel: 8 6 1 3 2 5 1 8
a) 8 + 1 + 2 + 1 = 12
b) 6 + 3 + 5 + 8 = 22
c) 22 * 3 = 26
d) 12 + 26 = 78
e) 80 - 78 = 2
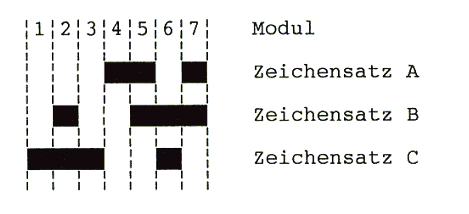
Die gesamte Codetabelle ist weiter unten abgedruckt. (0 = weiß, 1 = schwarz). Nun ist noch zu klären, wo die 13. Ziffer versteckt wird (es ist übrigens die ganz links vor dem Code gedruckte Ziffer). Diese Ziffer wird durch die Kombination von Zeichensatz A und B in der linken Hälfte des Barcodes festgelegt. Wie die Zuordnung ist, zeigt die zweite Tabelle unten. Der EAN-8-Code besteht nur aus zwei Blöcken zu je 4 Zeichen aus den Zeichensätzen A (links) und C (rechts).
Die drei Zeichensätze des EAN-Barcodes
| Zeichensatz A | Zeichensatz B | Zeichensatz C | |
|---|---|---|---|
| 0 | 0 0 0 1 1 0 1 | 0 1 0 0 1 1 1 | 1 1 1 0 0 1 0 |
| 1 | 0 0 1 1 0 0 1 | 0 1 1 0 0 1 1 | 1 1 0 0 1 1 0 |
| 2 | 0 0 1 0 0 1 1 | 0 0 1 1 0 1 1 | 1 1 0 1 1 0 0 |
| 3 | 0 1 1 1 1 0 1 | 0 1 0 0 0 0 1 | 1 0 0 0 0 1 0 |
| 4 | 0 1 0 0 0 1 1 | 0 0 1 1 1 0 1 | 1 0 1 1 1 0 0 |
| 5 | 0 1 1 0 0 0 1 | 0 1 1 1 0 0 1 | 1 0 0 1 1 1 0 |
| 6 | 0 1 0 1 1 1 1 | 0 0 0 0 1 0 1 | 1 0 1 0 0 0 0 |
| 7 | 0 1 1 1 0 1 1 | 0 0 1 0 0 0 1 | 1 0 0 0 1 0 0 |
| 8 | 0 1 1 0 1 1 1 | 0 0 0 1 0 0 1 | 1 0 0 1 0 0 0 |
| 9 | 0 0 0 1 0 1 1 | 0 0 1 0 1 1 1 | 1 1 1 0 1 0 0 |
Codierung des 13. Zeichens
| 0 | A A A A A A |
| 1 | A A B A B B |
| 2 | A A B B A B |
| 3 | A A B B B A |
| 4 | A B A A B B |
| 5 | A B B A A B |
| 6 | A B B B A A |
| 7 | A B A B A B |
| 8 | A B A B B A |
| 9 | A B B A B A |
Von links nach rechts besteht der gesamte EAN-13-Barcode aus:
Die letzte Ziffer (ganz rechts) ist eine Prüfziffer, die folgendermaßen ermittelt wird:
Beispiel:
Code: 0 1 1 3 7 3 5 5 9 2 4 3 PZ a) 0 + 1 + 7 + 5 + 9 + 4 = 26 b) 1 + 3 + 3 + 5 + 2 + 3 = 17 c) 17 * 3 = 51 d) 26 + 51 = 77 e) 80 - 77 = 3 --> Prüfziffer 3Von links nach rechts besteht der gesamte EAN-8-Barcode aus:
Auch hier ist wieder das letzte Zeichen ganz links ein Prüfzeichen zur Fehlererkennung.
Um Bitfehler nicht nur erkennen, sondern auch korrigieren (d. h. lokalisieren) zu können, muß der Hammingabstand auf h >= 3 erhöht werden. Beispiel h = 3:
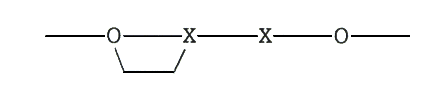
O: gültiges Codewort
X: ungültiges Codewort
Ein Bitfehler führt zu einem ungültigen Codewort, das sich vom verfälschten Codewort in nur einem Bit unterscheidet. Zu allen anderen gültigen Codeworten hat es mindestens zwei Bit Unter- schied. Da die Auftrittswahrscheinlichkeit des 1-Bit-Fehlers in einem Codewort wesentlich höher ist, als bei zwei oder mehr Bit- fehlern, ordnet man das fehlerhafte Codewort dem ähnlichsten gültigen Codewort zu --> Fehlerkorrektur. Allgemein gilt für die Anzahl der korrigierbaren Fehler:
k = (h - 1)/2
Es existieren eine Reihe von Verfahren zur Fehlersicherung, z. B.
Beispiel: Blockübertragung mit Kreuzsicherung
k = (h - 1)/2 = e/2
k = Anzahl der korrigierbaren Fehler
e = Anzahl der erkennbaren Fehler
Hamming-Codes haben viel mehr Bits als notwendig und sind nach einem bestimmten System aufgebaut. So benötigen z. B. Codes mit 2, 3 und 4 Nutzbits noch zusätzliche 3 Prüfbits zur Korrektur eines Fehlers.
Ein System zum Aufbau von Haming-Codes zur Korrektur eines Fehlers verwendet 4 Nutzbits (n1 - n4) + 3 Prüfbits (p1 - p3) --> 7 Bits:

Berechnung der Prüfbits (Addition modulo 2):

Beispiel: 8421-Code mit Hammingzusatz (h = 3):
Wert | p1 p2 n1 p3 n2 n3 n4
-----+---------------------
0 | 0 0 0 0 0 0 0
1 | 1 1 0 1 0 0 1
2 | 0 1 0 1 0 1 0
3 | 1 0 0 0 0 1 1
4 | 1 0 0 1 1 0 0
5 | 0 1 0 0 1 0 1
6 | 1 1 0 0 1 1 0
7 | 0 0 0 1 1 1 1
8 | 1 1 1 0 0 0 0
9 | 0 0 1 1 0 0 1
Gesendet wird: 1 0 0 0 0 1 1
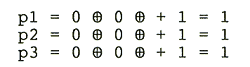
empfangene Prüfbits: 1 0 0
berechnete Prüfbits: 1 1 1
Daraus ergibt sich:
1 0 0
1 1 1
-------
(Antivalenz): 0 1 1
LSB MSB
"von rückwärts" gelesen: 1 1 0
--> Stelle 6 ist zu korrigieren.
Die Vorgehensweise ist folgende:
B(x) ist durch G(x) ohne Rest teilbar. Auf Empfängerseite wird B(x) wieder durch G(x) geteilt. Das CRC-Feld muß dann lauter Nullen enthalten.
Bei einem 16-Bit-CRC werden Burst-Fehler von nicht mehr als 16 Bit erkannt. Bei längeren Burst ist die Wahrscheinlichkeit der Erkennung 99,997%. Bei einem 32-Bit-CRC werden 99,99999995% aller längeren Fehler-Bursts erkannt.
Die technische Realisierung kann durch ein rückgekoppeltes Schieberegister der Länge k erfolgen. Das folgende Beispiel wird aus Gründen der Übersichtlichkeit nur mit einem 5-Bit-Schieberegister realisiert. Wir wőhlen dazu das Generator-Polynom:
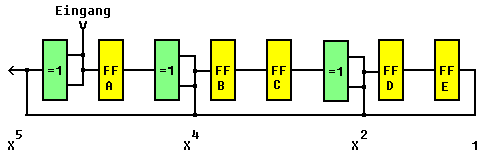
Die Nutzdaten werden um 5 Nullbits verlängert und dann seriell in das Schieberegister gespeist. nach n Schiebeoperationen sind die Nutzdaten gesendet, nach weiteren k Schiebeoperationen auch das CRC-Feld. Dazu ein Beispiel. Es soll der Datenblock 1010001101 (n = 10) gesendet werden. Der Inhalt des Schieberegisters kann anhand der folgenden Tabelle verfolgt werden:
| Flipflops des Schieberegisters | Nutz- daten | ||||||
| Urzustand | A | B | C | D | E | ||
| 1.Schritt | 0 | 0 | 0 | 0 | 0 | ||
| 2.Schritt | 1 | 0 | 1 | 0 | 0 | 1 | |
| 3.Schritt | 1 | 1 | 1 | 1 | 1 | 0 | |
| 4.Schritt | 1 | 1 | 1 | 1 | 0 | 1 | |
| 5.Schritt | 0 | 1 | 0 | 0 | 1 | 0 | |
| 6.Schritt | 1 | 0 | 0 | 1 | 0 | 0 | |
| 7.Schritt | 1 | 0 | 0 | 0 | 1 | 0 | |
| 8.Schritt | 0 | 0 | 0 | 1 | 0 | 1 | |
| 9.Schritt | 1 | 0 | 0 | 0 | 1 | 1 | |
| 10.Schritt | 1 | 0 | 1 | 1 | 1 | 0 | |
| 11.Schritt | 0 | 1 | 1 | 1 | 0 | 1 | |
Im Schieberegister steht nun R(x), das CRC-Feld. Da nun 5 Nullbits folgen, wird dieses unverändert an die Daten angefügt.
 Zum vorhergehenden Abschnitt Zum vorhergehenden Abschnitt |
 Zum Inhaltsverzeichnis Zum Inhaltsverzeichnis |
 Zum nächsten Abschnitt Zum nächsten Abschnitt |