 |
Webdesignvon Prof. Jürgen Plate |
|
Webdesignvon Prof. Jürgen Plate |
Vorteile:
- Einfach zu erstellen. Ein Scanner gibt die Daten z.B. als Bitmap aus.
- Pixel können sehr einfach einzeln oder in Gruppen manipuliert werden (z.B. Änderung der Farbe).
- Können für ein Ausgabegerät optimal erstellt werden, wenn dieses Daten pixelweise ausgibt. Dazu gehören z. B. Monitore.
Nachteile:
- Dateien können sehr groß werden, insbesondere wenn das Bild sehr viele Farben enthält. Durch geeignete Kompressionsverfahren kann diese Datenmenge u.U. reduziert werden.
- Bitmaps lassen sich schlecht verkleinern oder vergrößern (skalieren). Beim Vergrößern werden im wesentlichen einzelne Pixel dupliziert, so daß das Bild unannehmbar verändert werden kann. Beim Verkleinern werden einzelne Pixel einfach verworfen. Daher können Bitmaps meist nur in der Auflösung vernünftig gedruckt werden, mit der sie erstellt wurden.
In früheren Versionen dieses Skripts habe ich Bildschirm und Drucker in
einen Topf geworfen. Dazu schrieb mir aber Rüdiger Heierhoff von der
Akademie für interaktive Medien und Kommunikation GmbH eine interessante
E-Mail, die ich hier weitergeben will:
...
Meiner Meinung nach geben Drucker diese Daten eben nicht als Pixel aus,
sondern als Punkt (Dot). Wie Sie weiter unten erläutern, wird z. B. bei
Echtfarbenbildern (24-bit) jedes "Pixel ... durch drei Bytes repräsentiert
(z. B. RGB)..."
Anders ausgedrückt, EIN Pixel enthält die Farbinformationen für Cyan, Magenta
und Gelb (CMY). Um diese Informationen darzustellen, benötigt ein Farbdrucker
mindestens DREI Punkte. Praktische Konsequenz ist (grob gesagt), das die effektiv
nutzbare Auflösung eines 600 dpi Bildes eigentlich nur 200 dpi beträgt. Dazu
kommt noch die Rasterfrequenz mit der der Drucker das Druckbild erzeugt
etc.(s.a. Baufeldt/Rösner/Scheuermann/Walk: Informationen übertragen und
drucken, Lehr-und Arbeitsbuch für das Berufsfeld Drucktechnik; Verlag Beruf
+ Schule, Itzehoe 1977 und 1998).
Dazu ist es wichtig zu verstehen, dass die gespeicherte elektronische
Bilddatei eigentlich keine Längenausdehnung besitzt, im Gegensatz zum
gedruckten Bild. Die Angabe der Auflösung macht daher immer nur dann Sinn,
wenn es um die Ausgabe z.B. auf einen Drucker geht (X cm Breite mal Y cm Höhe
bei Z dpi). Für die Bildschirmausgabe reicht in der Regel die Angabe der Bildmaáe
in Pixeln (X Pixel Breite mal Y Pixel Höhe).
In der Fachliteratur wird übrigens dem von mir angedeuteten Umstand insofern
Rechnung getragen, als es für Pixel pro Inch und Punkte pro Inch
entsprechende Bezeichnungen gibt: ppi (Pixel pro Inch) bzw. dpi (Punkte pro
Inch), wobei in der Regel jedoch für beide Bezeichnungen dpi benutzt wird.
Vorteile:
- Ideal zur Speicherung von Bildern, die entweder linienbasierte Information enthalten oder die Elemente enthalten, die leicht in linienbasierte Information zu überführen sind (z. B. Text).
- Leicht skalierbar und manipulierbar
- Meist einfach in andere Vektor- oder Rasterformate wandelbar.
Nachteile:
- Nicht geeignet zur Speicherung von extrem komplexen Bildern, z. B. Fotografien mit pixelweise wechselnden Farben.
- Das Erscheinungsbild kann stark von der Anwendung abhängen, mit der die Vektordatei eingelesen wird. Identische Vektordaten werden leider nicht immer identisch interpretiert.
- Die Ausgabequalität ist nur optimal bei Vektorausgabegeräten wie z.B. Plotter.


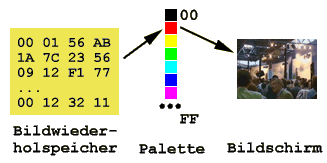

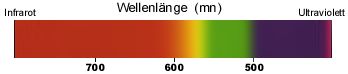
Licht ist elektromagnetische Strahlung und das für den Menschen sichtbare Spektrum ist der Wellenlängenbereich von 400 nm (Violett) bis 700 nm (Rot). Farben sind ein grundlegender Bestandteil unseres Lebens. Das Farbempfinden ist bei jedem Menschen unterschiedlich.
 Sichtbares Licht ist ein ganz kleiner Teil des Wellenspektrums. Je
nach Länge der Wellen in diesen Spektrum erscheint ein Lichtstrahl
in einer bestimmten Farbe.
Ein Lichtstrahl mit einer Wellenlänge von 700 nm erscheint
rot, ein Lichtrahl mit einer Wellenlänge von ca 500 nm erscheint
blau. So entstehen die Farben.
Wenn ein weißer Lichtstrahl (ein Gemisch aller Wellenlängen)
auf eine Fläche prallt, die alle Wellenlängen außer
Rot absorbiert, dann erscheint diese Fläche rot.
Sichtbares Licht ist ein ganz kleiner Teil des Wellenspektrums. Je
nach Länge der Wellen in diesen Spektrum erscheint ein Lichtstrahl
in einer bestimmten Farbe.
Ein Lichtstrahl mit einer Wellenlänge von 700 nm erscheint
rot, ein Lichtrahl mit einer Wellenlänge von ca 500 nm erscheint
blau. So entstehen die Farben.
Wenn ein weißer Lichtstrahl (ein Gemisch aller Wellenlängen)
auf eine Fläche prallt, die alle Wellenlängen außer
Rot absorbiert, dann erscheint diese Fläche rot.
Für das Farbensehen beim Menschen sind bestimmte Sehzellen, die sogenannten Zapfen zuständig. Es gibt drei verschiedene Sorten von Zapfen in der Netzhaut, die jeweils mit einem anderen lichtempfindlichen Farbstoff ausgestattet sind. Ein reines Licht von 400 nm Wellenlänge erregt nur den 'Blaurezeptor' unter den Zapfen. Ein Licht der Wellenlänge 450 nm erregt den 'Blaurezeptor' stark und den Grünrezeptor sehr schwach. Licht von 500 nm Wellenlänge spricht alle drei Zapfensorten an. Die einzelnen Farbeindrücke werden also durch unterschiedliche Erregungsstärken der einzelnen Zapfensorten ausgelöst. Gleiche Erregung aller Zapfen führt zum Eindruck ,,weiß``. Es genügen also drei Grundfarben, um als deren Mischung alle Farben darzustellen.
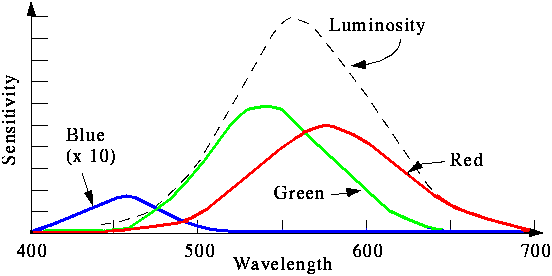
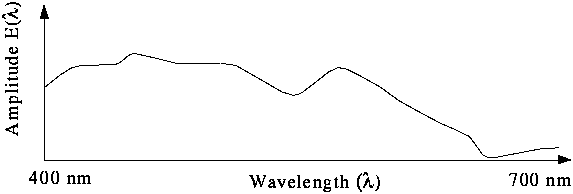
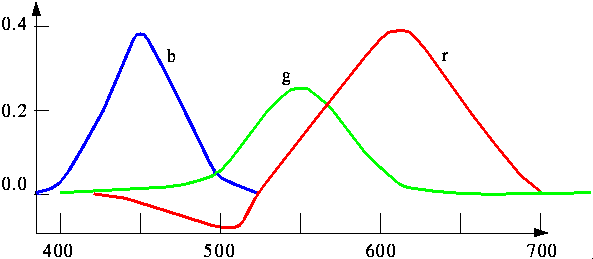
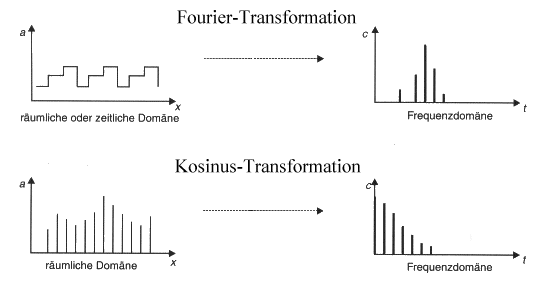
Betrachtet man Farben nur im Hinblick auf ihren Farbton und nicht auf Helligkeit und Sättigung, so liegt die Wellenlänge zwischen zwei gerade noch als unterschiedlich zu erkennende Farben zwischen 2 nm und 10 nm, je nachdem aus welchem Wellenlängenbereich die Farben stammen. Zur Codierung einer Farbe sind so 3 x 8 = 24 Bit ausreichend. Das folgende Diagramm zeigt die Spektren der (reinen) Grundfarben, die man addieren kann, um alle sichtbaren Farben darzustellen. Ein negativer Wert bedeutet dabei, daß die entsprechende Farbe nicht exakt darstellbar ist.
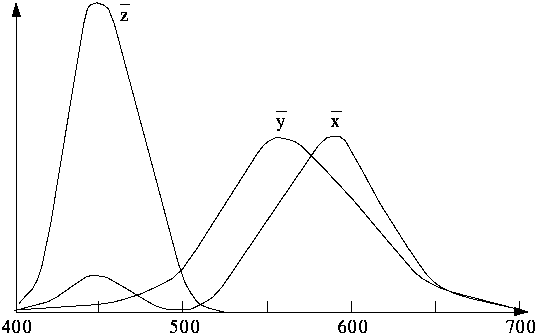
Um alle Farben darstellen zu können, muß man von den Grundfarben abgehen und 'nicht-reine' Farben verwenden. 1931 definierte die CIE drei Standard-Primärfarben, (X,Y,Z). Die Primärfarbe Y ist dabei an die Helligkeitsempfindlichkeit des menschlichen Auges angepaßt
Grundfarben-KontrastDie "klassischen" Grundfarben Blau, Gelb und Rot bilden untereinander einen starken Farbkontrast. |
 |
Hell-Dunkel-KontrastHier handelt es sich um die gleiche Farbe, jeweils als sehr helle oder sehr dunkle Nuance. |
 |
Komplementär-KontrastDie komplementären Farben liegen sich im Farbkreis gegenüber: Rot - Grün, Gelb - Lila, Orange - Blau. |
 |
QualitätskontrastFarbqualität bedeutet die Intensität einer Farbe zwischen Reinheit und Trübung. |
 |
QuantitätskontrastMengenverhältnis von Farben zueinander (in der Fläche). |
 |
Simultan-KontrastDieselbe Farbe wirkt auf unterschiedlichem Hintergrund verschieden. |
 |
Dominante FarbenEinige Farben drängen sich mehr als andere in den Vordergrund. Ein Beispiel dafür sind die Signal-Farben Rot oder Orange. |
 |
| Helle Farben treten in dunkler Umgebung in den Hintergrund. Auf der anderen Seite treten dunklere Farben vor hellem Hintergrund hervor. |  |
LuftperspektiveMan kennt es aus der Natur oder aus Gemählden: wenn man in die Ferne schaut, wird die Landschaft zum Horizont hin immer bläulicher. Diesen Effekt kann man ausnutzen, um Tiefe in einem Bild zu erreichen. |
 |
Langes Lesen ermüdet, Bildschirmarbeit sogar noch mehr. Ziel des Webdesign soll sein, die Augenbelastung zu vermindern. Die höchste Belastung entsteht durch weißes Licht. Auch warme Farben belasten uns mehr als kalte Farben. Am geringsten belasten uns Farben im Bereich Laubgrün bis Gelbgrün.
Farbwahrnehmung erzeugt beim Menschen auch bestimmte psychische Empfindungen:
Warme FarbenAls "warm" gilt die Gelb-Orange-Rot Palette.
|
 |
Kalte FarbenAls "kühl" werden Blau-Grün-Töne empfunden.
|
 |
Neutrale FarbenWeiß, Grau und Schwarz wirken am sachlichsten, aber manchmal auch etwas langweilig. |
 |
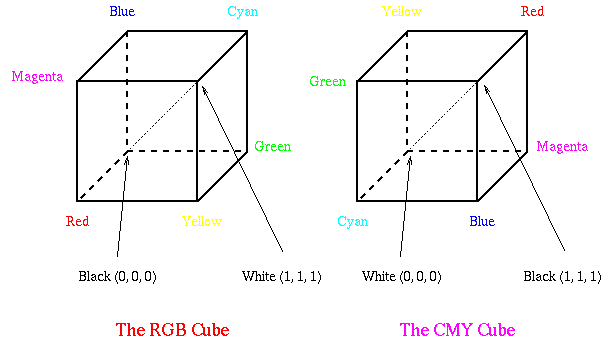
Die physikalisch-technischen Farbmodelle beschreiben eine Farbe als Mischung dreier Primärfarben. Die Unterschiede zwischen den einzelnen Modellen liegen in der Wahl der Primärfarben und der Art der Farbmischung. Zu den wichtigsten technischen Farbmodellen zählen:
 |
 |
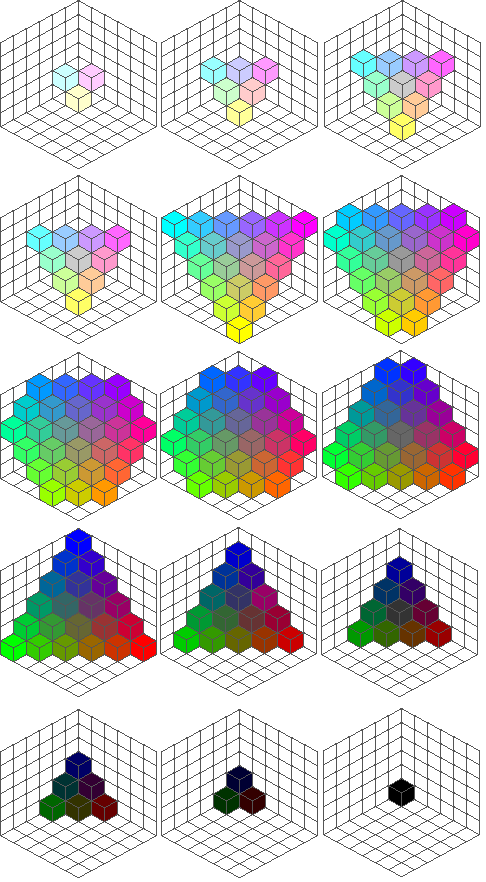
| RGB-Farbwürfel Ins Innere des Würfels |
RGB-Farbmischung per "Scheinwerfer" |
Bei Grafikkarten und bei der Farbdefinition für WWW-Anwendungen wird der reelle Zahlenbereich 0.0 - 1.0 auf den Wertebereich 0 - 255 umgesetzt. Durch die 256 Werte pro Farbkanal bei drei Kanälen können so 16.7 Mio. Farben, d. h. Truecolor, festgelegt werden:

Das RGB-Modell ist wichtig bei der Farbdarstellung auf Monitoren. Bei Farbbildschirmen werden drei Phosphorarten auf der Mattscheibe aufgebracht, die von drei unabhängigen Elektronenkanonen angesteuert werden und das in drei Teilbilder (RGB) zerlegte Farbbild erzeugen.
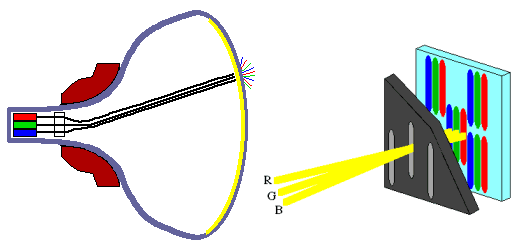
Daraus ergibt sich die besondere Bedeutung des RGB-Modells: alle anderen Farbbeschreibungen müssen vor der Farbausgabe in den äquivalenten Punkt des RGB-Würfels umgerechnet werden.Benutzen zwei Farbbildschirme Kathodenstrahlröhren mit verschiedenem Phosphor, so ergeben sich auch unterschiedliche Farbskalen. Man kann jedoch durch eine Transformationsrechnung die auf einer Kathodenstrahlröhre spezifizierte Farbe auf die Farbskala der anderen Röhre abstimmen.
Die Umrechnung zwischen RGB- und CMY-Modell erfolgt nach folgenden Formeln:
Beim CMYK-Modell erfolgt die Umrechnung nach folgenden Formeln:
Eine aus nur einer Wellenlänge bestehende Lichtquelle ist eine monochromatische Quelle. Nehmen wir als Beispiel an, darf die Wellenlänge dieser monochromatischen Quelle £ ist. Diese Quelle hat eine Energie, die auch Intensität genannt wird. Wir nennen diese Intensität C. In Wirklichkeit sind nur wenige Quellen monochromatisch. Die meisten Quellen setzen sich aus einem Bereich von Wellenlängen mit je einer eigenen Intensität zusammen. Das ist die spektrale Verteilung der Lichtquelle, die durch die Funktion C(£) dargestellt wird.
Im sichtbaren Spektrum kann das menschliche Auge zwischen verschiedenen Wellenlängen monochromatischen Lichts unterscheiden. jede Wellenlänge erzeugt einen anderen Eindruck, die Farbempfindung. Die Art, wie das menschliche Auge auf Licht reagiert, weist einige interessante Aspekte auf, z. B., daß zwei verschiedene Wellenlängen nicht als verschiedene Farben erscheinen. Zwei monochromatische Quellen mit genau der gleichen Intensität erwecken einen anderen Eindruck von 'Leuchtdichte'. Das menschliche Auge reagiert auf bestimmte Wellenlängen empfindlicher als auf andere. Mit anderen Worten, das Auge reagiert auf manche Farben empfindlicher als auf andere. Unser Auge reagiert empfindlicher auf Gelb oder Gelbgrün als etwa auf Rot oder violett.
Die Reaktion des menschlichen Auges V(£) entspricht jeder Wellenlänge £. Das ist die spektrale Reaktion des menschlichen Sehvermögens. Die Luminanz einer Lichtquelle oder eines beleuchteten Gegenstands ist kein physisches Merkmal der Quelle oder des Gegenstands, sondern eine wahrgenommene Empfindung des menschlichen Betrachters. Luminanz ist ein Produkt der spektralen Verteilung von Energie durch spektrale Reaktion der menschlichen Sicht.
L = f * C(£) * V(£) * d£
Luminanz ist also ein Maß der allgemeinen Reaktion des Auges auf alle in einer Quelle oder einem Gegenstand enthaltenen Wellenlängen.
Luminanz und Farbunterschied im analogen Fernsehen
Die drei Signale Rot, Grün und Blau können in drei andere Signale
umgewandelt weren: in die Information der Luminanz (, d. h. die Leuchtdichte
bzw. die Lichtintensität) und zwei weitere Farbsignale.
Das Prinzip der Umwandlung der RGB-Signale in Luminanz- und Farbsignale
ist älter als das Farbfernsehen. Dafür gibt es zwei Gründe. Erstens ist
dadurch eine Abwärtskompatibilität möglich, so daß alte
Schwarzweiß-Fernsehgeräte unterstützt werden. Das ist die Aufgabe des
Luminanzsignals. Da das menschliche Sehvermögen weniger stark auf Farbe
als auf Luminanz reagiert, kann das Farbsignal gegebenenfalls mit geringerer
Genauigkeit übertragen oder dargestellt werden.
In der Fernsehtechnik wird das Luminanzsignal Y-Signal genannt. Die zwei Chrominanzsignale werden aus den Farbunterschieden herechnet. Ein Farbunterschiedssignal für Rot, Grün und Blau entsteht durch Suhtrahieren des Luminanzsignals vom Farbsignal. ist beispielsweise R das Farbsignal Rot, ist das Farbunterschiedssignal von Rot (R - Y). In der Praxis genügen zwei Farbunterschiedssignale, wenn Luminanz verfügbar ist. Farbunterschiedssignale werden nicht so übertragen wie sie sind, sondern vor der šbertragung in zwei Signale - die Cbrominanzsignale - umgewandelt. Die Umwandlung ist linear. Jede Femsehnorm definiert ihre eigene Umwandlungsmethode:
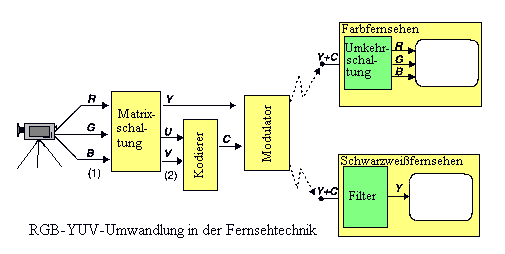
Die NTSC-Norm bezeichnet die Luminanz als Y-Komponente und die zwei Chrominanzsignale als I- und Q-Komponenten. I und Q bilden zusammen die Farbton- und Sättigungsaspekte (Chrominanz). Sie werden wie folgt herechnet:
Y = 0,30*R + 0,59*G + 0,11*B
(1) I = 0,74*(R - Y) - 0,27*(B - Y) = 0,60*R - 0,28*G - 0,32*B
Q = 0,48*(R - Y) + 0,41*(B - Y) = 0,2l*R - 0,52*G + 0,31*B
Die PAL-Norm bezeichnet die Luminanz Y und zwei Chrominanzsignale mit U und V:
Y = 0,30*R + 0,59*G + 0,11*B
(2) U = 0,493*(B - Y) = -0,15*R - 0,29*G + 0,44*B
V = 0,877*(R - Y) = 0,62*R - 0,52*G - 0,10*B
Die folgenden Modelle basieren auf Luminanz und Chrominanz.
Dabei ist I in etwa die Rot-Orange-Achse und Q annähern orthogonal zu I. Das menschliche Auge ist am Empfindlichsten für Y, danach für I und schließlich für Q.
Daraus leitet sich bei den meisten Bildbearbeitungsprogrammen das HSB-Modell ab. Es entspricht von allen drei Modellen unserer verbalen Farbbeschreibung am meisten. Beschreibungen wie ein kräftiges, helles Gelb lassen sich sofort umsetzen. Die Initialen stehen für Hue (Farbton), Saturation (Sättigung) und Brightness (Helligkeit). Der Farbton beeinhaltet die reine Farbinformation, die Sättigung das Verhätlniss von Stärke der reinen Farbe und den unbunten Anteilen. Die Helligkeit entspricht der Helligkeit von 1% - 100%. 0% stellt immer Schwarz dar, 100% immer Weiß.
 Bei der professionellen Bildbearbeitung
werden fast alls Änderungen an Bildern über sogenannte Gradationskurven
gemacht. Diese Bildberabeitungen sind nötig, um Abbildungen auf
die Besonderheiten spezieller Ausgabegeräte einzustellen oder um
besondere Effekte zu erzielen.
Bei der professionellen Bildbearbeitung
werden fast alls Änderungen an Bildern über sogenannte Gradationskurven
gemacht. Diese Bildberabeitungen sind nötig, um Abbildungen auf
die Besonderheiten spezieller Ausgabegeräte einzustellen oder um
besondere Effekte zu erzielen.
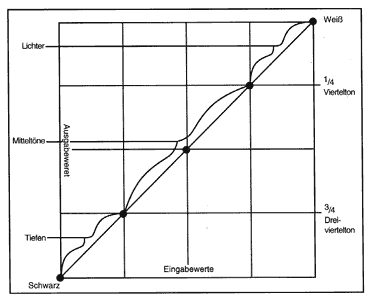
Die Gradationskurve ist die Visualisierung des Verhältnisses
von Eingabe- zu Ausgabewerten in einem Bereich von 0% bis 100%. Diese
Kurve repräsentiert alle Farben eines Bildes, jede Veränderung
ist dort ablesbar. Die Beeinflussung der Farbbereiche eines Bildes durch
die Gradationskurve verdeutlicht die nebenstehende Abbildung.
Der Wert für I0 hängt von der verwendeten Bildröhre ab und liegt normalerweise zwischen 1/200 und 1/40 des maximal erreichbaren Wertes. Das Verhältnis zwischen maximaler und minimaler Helligkeit nennt man den Dynamikbereich einer Bildröhre.
Für I0 = 0.02 errechnet sich r = 1.015. Um die Darstellung einer Graustufentreppe (also Werte zwischen 0 .. 1) ohne Stufen erscheinen lassen ist ein Wert r < 1.01 nötig, dann kann das Auge die einzelnen Helligkeitssprünge nicht mehr voneinander unterscheiden.
Nun werden die gewünschten Helligkeitswerte durch den Bildschirm auch nichtlinear
verändert, es ist also eine weitere Korrektur notwendig, um eine korrekte
Abbildung zu erreichen.
Die Lichtintensität I die durch einen Elektronenstrahl durch den Phosphor
des Bildschirms umgesetzt wird, hängt von der Zahl der Elektronen N wie
folgt ab:
I = k * N y
Dabei sind k und y Konstanten die vom Bildschirm abhängig sind. y ist der Wert Gamma und liegt bei den meisten Bildschirmen zwischen 2.2 und 2.5. Eine Umrechnung der gewünschten Helligkeit auf einen Eingabewert basierend auf dieser Formel nennt man auch Gammakorrektur.

Mit Hilfe einer Tabelle ist es nun möglich, die gesamte Helligkeits-Korrektur durchzuführen. Bei manchen Monitoren ist es auch möglich, die Korrekturtabelle im Monitor abzulegen, üblicherweise wird jedoch die Korrektur in der Grafikkarte durchgeführt. Natürlich können auch die Bildinformationen selbst bereits korrigiert werden. Die Korrektur für die Helligkeitsabbildung kann vorab erfolgen. Insbesondere sind auch Korrekturen für gescannte Bilder oder Videos nötig, da diese selbst wieder eine andere Helligkeitsumsetzung aufweisen.
Ähnliche Korrekturen sind auch für Filmbelichter, Drucker etc. notwendig, will
man Bilder mit Graustufen korrekt darstellen. Für eine Korrektur an Farbildern
kann es ggf. nötig sein die Korrektur für alle drei Farbkomponenten getrennt
durchzuführen.
Die folgende Tabelle zeigt typische Werten der Dynamik 1/I0 und der
Anzahl der benötigten Intensitätsstufen. Die Zahl der möglichen
Intensitätsstufen erhält man aufgrund des Dynamik-Bereichs mit der Formel
n = log(1.01(1/I0))
| Technik | Dynamik | Intensitäts- Stufen |
|---|---|---|
| Bildschirm | 50 - 200 | 400 - 530 |
| Photo-Druck | 100 | 465 |
| Dia | 1000 | 700 |
| S/W-Druck auf gestrichenem Papier | 100 | 465 |
| Farb-Druck auf gestrichenem Papier | 50 | 500 |
| Zeitung | 10 | 234 |
Beim Dithering wird ein Farbton durch Kombination vorhandener Farben erzeugt. Die Kombination besteht darin, daß ein Pixelmuster erzeugt wird, welches aus einer gewissen Entfernung betrachtet dem gewünschten Farbton ähnelt. Bei naher Betrachtung sieht man freilich die Pixel. Bei Text kann dieses Raster aber schnell zur Unleserlichkeit führen.
Möchten Sie sicherstellen, daß ihr Dokument auf nahezu allen Geräten angezeigt werden kann, so beschränken Sie die Farbe. Es ist sicher heute nicht mehr nötig, sich auf die 16 Grundfarben zu beschränken. Aber bei der Farbdefinition von Text- umd Hintergrundfarbe ist es durchaus günstig, sich auf 256 Farben zurückzuziehen.
Betrachten wir ein Beispiel zum Dithering. Als Ausgangsbild verwenden wir ein Bild mit Farbverläfen:





Sie sehen also, daß auch auf nicht-Truecolor-Systemen erträgliche Bilder produziert werden können. Ein günstiges Vorgehen ist, auch das Dithern dem Browser des Betrachters zu überlassen, d. h. Echtfarbenbilder auch als Echtfarbenbilder zu übertragen. Dennoch sollte man sich als Autor klar sein, daß ein Bild bei jedem Betrachter gegebenenfalls verändert erscheint. Man kann sich also nicht darauf verlassen, daß der Betrachter jedes Detail sehen kann.
Das Beispiel zeigt, daß Dithering auch Übergänge erzeugen kann (Fehlerdiffusion). Dabei wird versucht, sich der wirklichen Übergang von einer Farbe über Zwischentöne zur anderen durch ein Muster verfügbarer Farben anzunähern. Stellt man sich jedoch eine Zeile Text vor, so kann dieser Effekt zur oben bereits erwähnten Unleserlichkeit führen.
Erste Schritte zur Verringerung der Dateigröße unternehmen Grafikformate, die intern Kompressionsmethoden wie Lauflängencodierung, LZW- oder Huffman-Codierung verwenden, wie z.B. GIF, PCX oder TIFF. Allerdings überschreiten diese Methoden selbst in ihrer modernsten Form selten den Kompressionsfaktor drei. Jedoch komprimieren diese Verfahren ohne Verluste und das Original läßt sich bis aufs letzte Bit wieder herstellen.
Bei der Reduktion von Bilddaten kann man sogenannte 'Kompressionsverfahren'
verwenden, um die Redundanz in der Bildinformation zu beseitigen. Dabei
unterscheidet man zwischen verlustfreier Kompression, bei der das
unrsprüngliche Bild wieder originalgetreu hergestellt wird und
verlustbehafteter Kompression, wo bei der Kompression ein mehr oder
minder großer Teil der Bildinformation verloren geht.
Ein einfaches Kompressionsverfahren ist die Run-Length-Codierung (RLE).
Dabei verfährt man wie folgt: Das Bild wird z. B. Zeile für Zeile abgespeichert.
Wenn mehrere aufeinanderfolgende Bildpunkte die gleiche Farbe haben, so
speichert man einen Zähler ab, der angibt, wie oft diese Farbe folgt. Der
Zähler ist eine Bildpunktfarbe, die nicht vorkommt und über einen Sonderfall
abgehandelt wird. Dieses Verfahren eignet sich am Besten für Bilder die eine
Palette verwenden und keine Farbverläufe (z.B. bei Fotos) oder komplizierte
Muster enthalten. Bilder in Echtfarben, z.B. von Fotoaufnahmen eignen sich für
dieses Verfahren nicht sehr gut. So lassen sich umgekehrt z.B. Grafiken, die
farbige Flächen enthalten sehr gut mit dem Verfahren abspeichern.
Wenn man komplexere Codierungen z. B. LZW (GIF) verwendet, lassen sich noch
bessere Kompressionsfaktoren erreichen, da dann auch sich wiederholende Muster
erkannt werden. Auch hier gilt, daß Echtfarbenbilder nur schlecht komprimiert
werden können.
H(S) = Summe(Pi * ld(1/Pi))
wobei Pi die Wahrscheinlichkeit des Auftretens vom Symbol Si ist. ld(1/Pi) ist
der Logarithmus zur Basis 2 von 1/Pi und gibt an, wieviele Bits benötigt
werden, um das Symbol Si zu codieren. Dazu ein Beispiel:
Für ein Bild mit gleichverteilten Graustufenwerten gilt pi = 1/256. Es
werden also 8 Bit benötigt, um jede Graustufe zu codieren. Die Entropie
des Bildes ist 8.
Die folgenden Algorithmen können mit einem einfachen Beispiel erläutert werden. Es sei die folgende Häfigkeitsverteilung gegeben:
Symbol A B C D E
---------------------------------
Anzahl 15 7 6 6 5
(15 + 7 + 6 + 6 + 5)*3 = 39*3 = 117 bit
Es wird nun versucht, für die häufigsten Symbole einen kurzen, für die
seltenen Modelle einen längeren Code zu finden. Dabei muß auf jeden
Fall die Fano-Bedingung erfüt sein: Kein Codewort eines Codes mit variabler
Wortlänge darf Anfang eines anderen Codewortes sein.
| A | 0 |
| B | 10 |
| C | 11 |
| D | 110 |
| E | 111 |
Nun benötigt man nur noch
15*1 + 7*2 + 6*2 + 6*3 + 5*3 = 15 + 14 + 12 + 18 + 15 = 74 bit
Mit zunehmender Zahl von Symbolen würde bei diesem Ansatz die Länge
der Codeworte rasch steigen. Deshalb werden in der Praxis andere Algorithmen
verwendet.
/\
0/ \1
/ \
AB CDE
/\
0/ \1
/ \
/\ 0/\1
0/ \1 / \
A B C DE
/\
0/ \1
/ \
/\ 0/\1
0/ \1 / \
A B C /\
0/ \1
D E
Es ergibt sich somit folgende Codierung:
| Symbol | Anzahl | ld(1/p) | Code | Anzahl Bits |
|---|---|---|---|---|
| A | 15 | 1.38 | 00 | 30 |
| B | 7 | 2.48 | 01 | 14 |
| C | 6 | 2.70 | 10 | 12 |
| D | 6 | 2.70 | 110 | 18 |
| E | 5 | 2.96 | 111 | 15 |
P4(39)
/\
0/ \1
/ \
/ \
/ \
A(15) \P3(24)
/\
0/ \1
/ \
P2(13)/ \P1(11)
/| /\
0/ |1 0/ \1
/ | / \
/ | / \
B(7) C(6) D(6) E(5)
Es ergibt sich somit folgende Codierung:
| Symbol | Anzahl | ld/1/p) | Code | Anzahl Bits |
|---|---|---|---|---|
| A | 15 | 1.38 | 0 | 15 |
| B | 7 | 2.48 | 100 | 21 |
| C | 6 | 2.70 | 101 | 18 |
| D | 6 | 2.70 | 110 | 18 |
| E | 5 | 2.96 | 111 | 15 |
Für beide Algorithmen gilt:
Die verlustbehafteten JPEG-Prozesse sind auf fotografische Aufnahmen mit fließenden Farbübergängen hin optimiert. Für andere Arten von Bildern sind sie weniger geeignet z. B. für Bilddaten mit harten Kontrasten wie Cartoons, Liniengrafiken oder Texte, die meist große Farbflächen und abrupte Farbwechsel enthalten.
Bei der Entwicklung des JPEG - Standards war es oberstes Ziel einheitliche Verfahren bereitzustellen, die möglichst alle Belange der Bilddatenkompression abdeckt. Dabei wurde auf folgende Aspekte besonderen Wert gelegt:
Die verwendeten Algorithmen sollten sowohl in Software als auch in Hardware relativ schnell und einfach zu implementieren sein.
Untersuchungen des JPEG-Gremiums haben ergeben, daß bei den verlustbehafteten Umformungsmethoden die 8 x 8 diskrete Kosinustransformation (DCT) die besten Ergebnisse liefert. Für die Operationen, die auf der DCT beruhen wurde ein Minimal-Algorithmus, der Baseline Codec festgelegt, auf den alle DCT-Modi aufbauen.
Die Komprimierung mit dem JPEG Baseline Codec besteht im wesentlichen aus 5 Schritten:
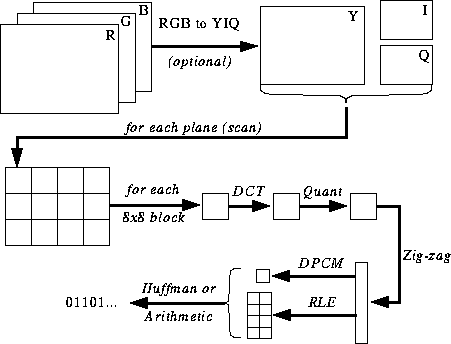
Das YCbCr-Modell ist ein solches Helligkeit-Farbigkeit-Modell. Dabei wird ein RGB-Farbwert in eine Grundhelligkeit Y und zwei Komponenten Cb und Cr aufgeteilt, wobei Cb ein Maß für die Abweichung von der 'Mittelfarbe' Grau in Richtung Blau darstellt. Cr ist die entsprechende Maßzahl für Differenz zu Rot. Diese Darstellung verwendet die Besonderheit des Auges, für grünes Licht besonders empfindlich zu sein. Daher steckt die meiste Information in der Grundhelligkeit Y, und man braucht nur noch Abweichungen nach Rot und Blau darzustellen.
Um nun Farbwerte in RGB-Darstellung in den YCbCr-Farbraum umzurechnen, benötigt man folgende Formel:
Y = 0,2990*R + 0,5870*G + 0,1140*B
Cb = -0,1687*R - 0,3313*G + 0,5000*B
Cr = 0,5000*R - 0,4187*G - 0,0813*B
Die Rücktransformation vom YcbCr-Farbraum in RGB-Werte geschieht wie folgt:
R = 1,0*Y + 0,0 *Cb + 1,402 *Cr
G = 1,0*Y - 0,34414*Cb - 0,71414*Cr
B = 1,0*Y + 1,7720 *Cb + 0,0 *Cr
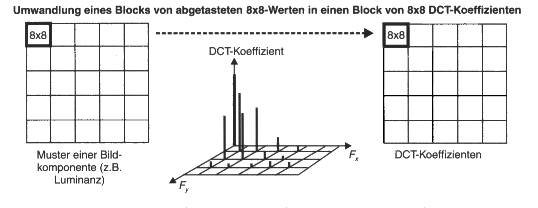
Als Basisvektoren werden aber nun 64 Blöcke zu 8x8 Pixeln verwendet, welche bezüglich des Vektorraums eine Orthonormalbasis bilden. Die Basisvektoren gewinnt man durch folgende Formel.
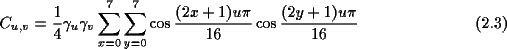
Durch den Basiswechsel ergeben sich 64 eindeutige Koeffizienten, die den Anteil des jeweiligen Basisblocks an dem Bilddatenblock darstellen. Die Koeffizienten werden berechnet durch:
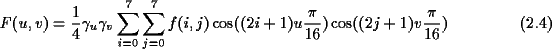
Um diese Koeffizientendarstellung in ihre Ursprungsform zurückzutransformieren, benötigt man folgende Beziehung:
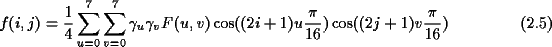
wobei
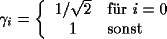
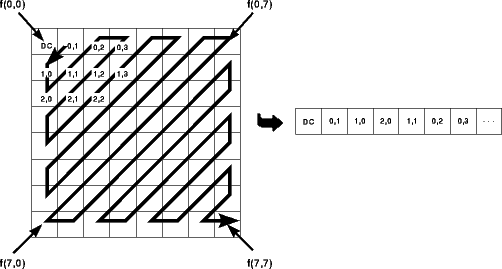
Das folgende Bild zeigt die 8 x 8 = 64 DCT-Basisfunktionen. Links oben ist F(0,0) (der DC-Anteil), rechts untern der höchste AC-Anteil.

Bei dieser Codierung und Decodierung (Codec) treten schon ohne weitere Behandlung der Koeffizienten Verluste auf, da die benötigte Kosinus- bzw. Sinusfunktion nur in begrenzter Genauigkeit auf Rechnern dargestellt werden kann. Daraus folgt ebenso, daß dieses Verfahren nicht iterierbar ist. Wird also ein mittels DCT codiertes Bild decodiert und wieder codiert, bekommt man ein anderes Ergebnis, als bei der ersten Codierung. Der Vorteil der DCT wird bei Bildern mit kontinuierlichen Farbübergängen besonders deutlich: Da sich benachbarte Bildpunkte in der Regel kaum unterscheiden, werden in der Koeffizientendarstellung nur der DC-Koeffizient (das ist der Koeffizient dessen Basisvektor in beiden Richtungen die Frequenz Null hat) und einige niederfrequente AC-Koeffizienten (das sind die übrigen Koeffizienten) größere Werte annehmen. Die anderen sind fast Null oder meistens sogar gleich Null. Dies bedeutet, daß kleinere Zahlen codiert werden müssen, und dies hat bei geeigneter Darstellung schon einen Komprimierungseffekt.
Wie man aus den Formeln erkennt, ist die Berechnung der Koeffizienten recht umfangreich. So benötigt man für einen 8 x 8-Block 63 Additionen und 64 Multiplikationen. Man kann das Problem durch Faktorisierung vereinfachen
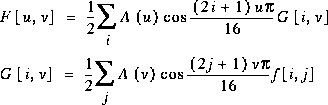
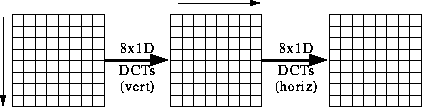
Die meisten Hardware- und Softwareimplementierungen von Coder und Decoder verwenden Ganzzahlarithmetik und approximieren die Koeffizienten. Die Multiplikationen reduzieren sich dann auf Schiebeoperationen. Der Weltrekord für die DCT lag 1989 bei 11 Multiplikationen und 29 Additionen.
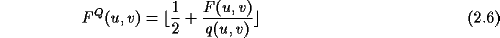
Die Umkehrabbildung multipliziert dann einfach den quantisierten Wert mit dem Quantisierungsfaktor. Durch diese Hin- und Zurücktransformation entsteht ein Informationsverlust, da bei dieser Rückrechnung die quantisierten Werte nicht immer auf den originalen Wert zurückführen. Je größer dabei der Quantisierungsfaktor ist, desto größer ist auch der Informationsverlust. Dieser Informationsverlust kann durch geeignete Wahl der Quantifizierungsfaktoren so gering gehalten werden, daß er vom Auge kaum wahrgenommen werden kann. Kompressionsraten von < 1:10 sind hierbei leicht realisierbar, ohne daß beim rekonstruierten Bild große Unterschiede zum Original zu erkennen sind.
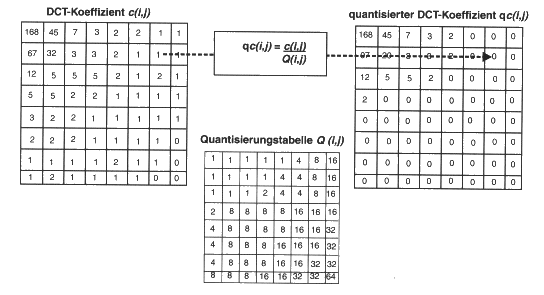
Für die Quantisierung ohne sichtbaren Informationsverlust sind jeweils für Helligkeit und Farbigkeit optimierte Quantisierungstabellen entwickelt worden. Diese sind zu entnehmen. In diesen Tabellen werden für den DC-Koeffizienten und die niederfrequenten AC-Koeffizienten bessere (kleinere) Quantisierungsfaktoren verwendet als für die höheren Frequenzen. Man nutzt dabei die oben genannte Schwäche des menschlichen Auges aus.
Tabelle der Quantisierungsfaktoren q(u,v) für die Luminanz
16 11 10 16 24 40 51 61
12 12 14 19 26 58 60 55
14 13 16 24 40 57 69 56
14 17 22 29 51 87 80 62
18 22 37 56 68 109 103 77
24 35 55 64 81 104 113 92
49 64 78 87 103 121 120 101
72 92 95 98 112 100 103 99
Für die Chrominanz wird eine zweite, ähnliche Tabelle verwendet.
Es lassen sich aber auch eigene Tabellen verwenden (die dann im Header der
Bilddatei mitgegeben werden).
Bei Implementierungen von JPEG kann man eine gewünschte Kompressionsrate
(oder Bildqualität) als Parameter einstellen, bei der folgenden Kompression
werden einfach die Quantisierungsfaktoren entsprechend skaliert.
Das zweite Bild ist nur noch ca. 2,1 KByte groß, der Faktor ist 1:100.

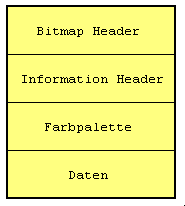
| Bezeichnungen | Microsoft Windows Bitmap, BMP, DIB |
| Farben | 1-Bit (s/w), 4-Bit (16 Farben), 8-Bit (256 Farben), 24-Bit (16,7 Mio. Farben) |
| Kompression | normalerweise keine oder RLE |
| Maximale Bildgröße | 65536 x 65536 Pixel |
Das Format BMP wird von den meisten Graphikprogrammen unterstützt, die unter MS-Windows arbeiten. Auch die meisten Konvertierprogramme unterstützen BMP. Zur Zeit gibt es vier Versionen des BMP-Formats:
Hier wird beispielhaft nur die MS-Windows Version ab 3.x beschrieben. Eine BMP-Datei besteht aus vier Abschnitten:
| Bezeichnungen | Graphics Interchange Format, GIF |
| Farben | 1- bis 8-Bit (s/w bis 256 Farben/Graustufen) |
| Kompression | LZW |
| Maximale Bildgröße | 65536 x 65536 Pixel |
| Besonderheit | Mehrere Bilder in einer Datei möglich -->
'animated GIF', 'interlaced' GIF, transparenter Hintergrund |
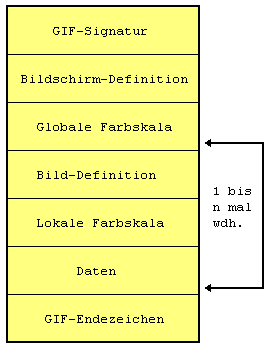
GIF wurde von den Firmen UNISYS Corp. und CompuServe entwickelt. Ziel war eine minimale Dateigröße zum Austausch von Graphiken über Mailboxen. Da im Mikrocomputerbereich für jede gängige Hardware (Amiga, Atari, IBM-kompatible, Macintosh) Programme existieren, die GIF-Grafiken verarbeiten können, ist es vor allem als Austauschformat über Hardwaregrenzen hinweg von Bedeutung. Eine GIF-Datei kann mehrere Bilder enthalten, was z. B. Interlacing ermöglicht. Im sequentiellen Modus wird das Bild zeilenweise von links oben nach rechts unten codiert und ausgegeben. Unter 'Interlacing' versteht man eine Abwandlung des Bildaufbaus bei der Wiedergabe. Es erscheint zunächst ein recht grobes Bild, das dann schrittweise immer schärfer wird. So kann man sich schon recht schnell einen Eindruck verschaffen. Dazu wird der Bildaufbau in vier Durchgänge aufgeteilt. Im ersten Durchgang wird ausgehend von der Zeile 0 jede achte Zeile ausgegeben, also die Zeilen 0, 8, 16 usw. Im zweiten Durchgang wird ausgehend von Zeile 4 jede achte Zeile ausgegeben, also 4, 12, 20 usw. Im dritten Durchgang folgt ausgehend von Zeile 2 jede vierte Zeile, also 2, 6, 10 usw. Durchgang vier vervollständigt das Bild ausgehend von Zeile 1 mit jeder zweiten Zeile, also 1, 3, 5 usw.
Des weiteren kann man eine Farbe des Bildes als 'Hintergrundfarbe' definieren. Diese Farbe (im linken Bild hellblau) wird bei der Wiedergabe dann durch die Farbe des Hintergrundes ersetzt (rechtes Bild):


Zur Zeit gibt es zwei Versionen des GIF-Formats:
Eine GIF-Datei hat folgenden Aufbau:
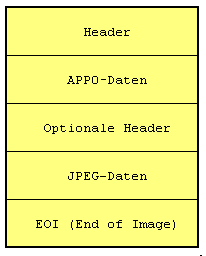
| Bezeichnungen | JPEG File Interchange Format, JPG, JPEG, JFIF, JFI |
| Farben | Bis 24-Bit (bis 16,7 Mio. Farben) |
| Kompression | JPEG |
| Maximale Bildgröße | 65536 x 65536 Pixel |
Das JPEG File Interchange Format (JFIF) ist eine Entwicklung der Firma C-Cube Microsystems zur Speicherung JPEG-komprimierter Daten. Eine JFIF-Datei hat folgenden Aufbau:
| Bezeichnungen | PC Paintbrush File Format, DCX, PCC |
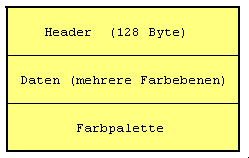
| Farben | 1-, 2-, 4-, 8-, 24-Bit (s/w bis 16,7 Mio. Farben) |
| Kompression | Keine oder RLE |
| Maximale Bildgröße | 65536 x 65536 Pixel |
Das PCX-Format wurde von der Firma ZSoft Corporation zur Speicherung und Übertragung der mit PC-Paintbrush erstellten Grafiken entwickelt. Dieses Format wurde von Microsoft übernommen und u.a. im Grafikprogramm MS-Paintbrush für Windows benutzt. PCX ist im PC-DOS/Windows-Bereich weit verbreitet, aber auch auf anderen Plattformen anzutreffen.
Nachteile des PCX-Formates sind eine hardwareabhängige Darstellung von Farben und Auflösung sowie ein relativ ineffizienter RLE-Kompressionsalgorithmus. Eine PCX-Datei hat folgenden Aufbau:
Gültige Kombinationen von Farbebenen und Anzahl der Pixel pro Farbebene sind:
| Farbebenen | Bits/Pixel | Anzahl Farben | Video-Modus |
| 1 | 1 | 2 | s/w |
| 1 | 2 | 4 | CGA |
| 3 | 1 | 8 | EGA |
| 4 | 1 | 16 | EGA und VGA |
| 1 | 8 | 256 | Extended VGA |
| 3 | 8 | 16,7 Mio. | Extended VGA + XGA |
| Bezeichnungen | Tag Image File Format, TIF |
| Farben | 1- bis 24-Bit (s/w bis 16,7 Mio. Farben) |
| Kompression | Keine, RLE, LZW, CCITT Group 3 und 4, JPEG |
| Maximale Bildgröße | ca. 4 Milliarden Bildzeilen |
| Besonderheit | Mehrere Bilder in einer Datei möglich |
TIFF ist eine Entwicklung der Firma Aldus Corporation. Dieses Format hat sich in den letzten Jahren zu einem der wichtigsten Formate für Rasterdateien entwickelt. Es wurde von Anfang an so umfangreich konzipiert, daß es eine Vielzahl von Speichermöglichkeiten bietet und neben den eigentlichen Grafikdaten auch Angaben wie der Name der benutzten Grafiksoftware oder der Scannertyp aufgenommen werden können. TIFF ist in der Lage, Schwarz/Weiß-, Grauwert- und Farbbilder zu speichern. Diese Möglichkeiten machen das Format komplizierter, andererseits aber auch universeller einsetzbar. Neben den meisten Scannern benutzen viele Grafikprogramme das TIFF-Format. Die letzte Revision ist TIFF 6.0 vom Juni 1992.
Das Einlesen von TIFF-Bildern bereitet manchen Programmen große Probleme. Aufgrund der möglichen Komplexität einer TIFF-Datei und der damit verbundenen Varianten (z.B. viele verschiedene Kompressionsmethoden) lesen viele Programme nur einen kleinen Anteil aller TIFF-Varianten. Die Fehlerursache ist dabei aber meist bei diesen Programmen zu suchen, da das TIFF-Format sehr präzise definiert ist. Wenn Sie Probleme beim Importieren einer TIFF-Datei haben, versuchen Sie, diese, falls noch möglich, unkomprimiert abzuspeichern und dann zu importieren.
Eine TIFF-Datei hat folgenden Aufbau:
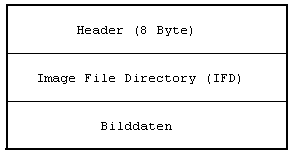
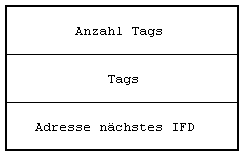
|
Header IFD_1 IFD_2 ... IFD_n Bilddaten_1 Bilddaten_2 ... Bilddaten_n |
Header IFD_1 Bilddaten_1 IFD_2 Bilddaten_2 ... ... IFD_n Bilddaten_n |
Header Bilddaten_1 Bilddaten_2 ... Bilddaten_n IFD_1 IFD_2 ... IFD_n |
 Zum vorhergehenden Abschnitt Zum vorhergehenden Abschnitt |
 Zum Inhaltsverzeichnis Zum Inhaltsverzeichnis |
 Zum nächsten Abschnitt Zum nächsten Abschnitt |
{kind=link}